 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Using Very Large Target Vocabulary for Neural Machine Translation
Paper and Code
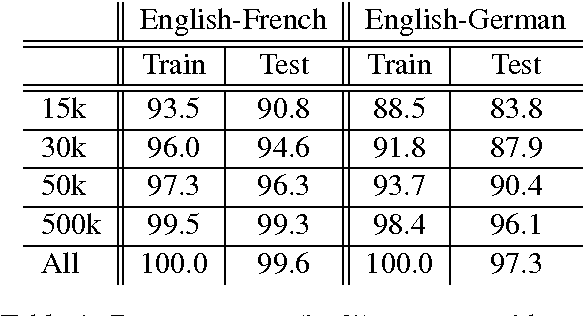
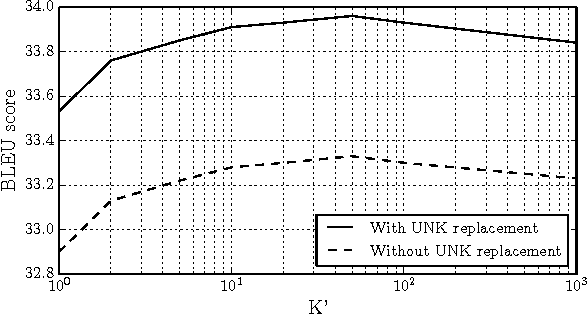
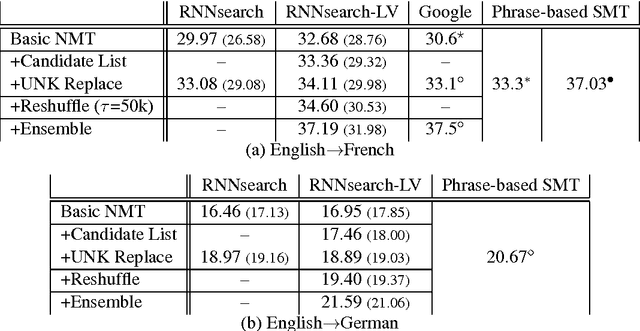
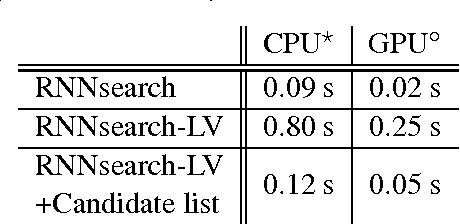
Neural machine translation, a recently proposed approach to machine translation based purely on neural networks, has shown promising results compared to the existing approaches such as phrase-based statistical machine translation. Despite its recent success, neural machine translation has its limitation in handling a larger vocabulary, as training complexity as well as decoding complexity increase proportionally to the number of target words. In this paper, we propose a method that allows us to use a very large target vocabulary without increasing training complexity, based on importance sampling. We show that decoding can be efficiently done even with the model having a very large target vocabulary by selecting only a small subset of the whole target vocabulary. The models trained by the proposed approach are empirically found to outperform the baseline models with a small vocabulary as well as the LSTM-based neural machine translation models. Furthermore, when we use the ensemble of a few models with very large target vocabularies, we achieve the state-of-the-art translation performance (measured by BLEU) on the English->German translation and almost as high performance as state-of-the-art English->French translation system.