 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudit After Segmentation: Reference-Free Mask Quality Assessment for Language-Referred Audio-Visual Segmentation
Feb 03, 2026Language-referred audio-visual segmentation (Ref-AVS) aims to segment target objects described by natural language by jointly reasoning over video, audio, and text. Beyond generating segmentation masks, providing rich and interpretable diagnoses of mask quality remains largely underexplored. In this work, we introduce Mask Quality Assessment in the Ref-AVS context (MQA-RefAVS), a new task that evaluates the quality of candidate segmentation masks without relying on ground-truth annotations as references at inference time. Given audio-visual-language inputs and each provided segmentation mask, the task requires estimating its IoU with the unobserved ground truth, identifying the corresponding error type, and recommending an actionable quality-control decision. To support this task, we construct MQ-RAVSBench, a benchmark featuring diverse and representative mask error modes that span both geometric and semantic issues. We further propose MQ-Auditor, a multimodal large language model (MLLM)-based auditor that explicitly reasons over multimodal cues and mask information to produce quantitative and qualitative mask quality assessments. Extensive experiments demonstrate that MQ-Auditor outperforms strong open-source and commercial MLLMs and can be integrated with existing Ref-AVS systems to detect segmentation failures and support downstream segmentation improvement. Data and codes will be released at https://github.com/jasongief/MQA-RefAVS.
Thinking Beyond Labels: Vocabulary-Free Fine-Grained Recognition using Reasoning-Augmented LMMs
Dec 21, 2025Vocabulary-free fine-grained image recognition aims to distinguish visually similar categories within a meta-class without a fixed, human-defined label set. Existing solutions for this problem are limited by either the usage of a large and rigid list of vocabularies or by the dependency on complex pipelines with fragile heuristics where errors propagate across stages. Meanwhile, the ability of recent large multi-modal models (LMMs) equipped with explicit or implicit reasoning to comprehend visual-language data, decompose problems, retrieve latent knowledge, and self-correct suggests a more principled and effective alternative. Building on these capabilities, we propose FiNDR (Fine-grained Name Discovery via Reasoning), the first reasoning-augmented LMM-based framework for vocabulary-free fine-grained recognition. The system operates in three automated steps: (i) a reasoning-enabled LMM generates descriptive candidate labels for each image; (ii) a vision-language model filters and ranks these candidates to form a coherent class set; and (iii) the verified names instantiate a lightweight multi-modal classifier used at inference time. Extensive experiments on popular fine-grained classification benchmarks demonstrate state-of-the-art performance under the vocabulary-free setting, with a significant relative margin of up to 18.8% over previous approaches. Remarkably, the proposed method surpasses zero-shot baselines that exploit pre-defined ground-truth names, challenging the assumption that human-curated vocabularies define an upper bound. Additionally, we show that carefully curated prompts enable open-source LMMs to match proprietary counterparts. These findings establish reasoning-augmented LMMs as an effective foundation for scalable, fully automated, open-world fine-grained visual recognition. The source code is available on github.com/demidovd98/FiNDR.
MIRA: A Novel Framework for Fusing Modalities in Medical RAG
Jul 10, 2025Multimodal Large Language Models (MLLMs) have significantly advanced AI-assisted medical diagnosis, but they often generate factually inconsistent responses that deviate from established medical knowledge. Retrieval-Augmented Generation (RAG) enhances factual accuracy by integrating external sources, but it presents two key challenges. First, insufficient retrieval can miss critical information, whereas excessive retrieval can introduce irrelevant or misleading content, disrupting model output. Second, even when the model initially provides correct answers, over-reliance on retrieved data can lead to factual errors. To address these issues, we introduce the Multimodal Intelligent Retrieval and Augmentation (MIRA) framework, designed to optimize factual accuracy in MLLM. MIRA consists of two key components: (1) a calibrated Rethinking and Rearrangement module that dynamically adjusts the number of retrieved contexts to manage factual risk, and (2) A medical RAG framework integrating image embeddings and a medical knowledge base with a query-rewrite module for efficient multimodal reasoning. This enables the model to effectively integrate both its inherent knowledge and external references. Our evaluation of publicly available medical VQA and report generation benchmarks demonstrates that MIRA substantially enhances factual accuracy and overall performance, achieving new state-of-the-art results. Code is released at https://github.com/mbzuai-oryx/MIRA.
OpenSeg-R: Improving Open-Vocabulary Segmentation via Step-by-Step Visual Reasoning
May 22, 2025Open-Vocabulary Segmentation (OVS) has drawn increasing attention for its capacity to generalize segmentation beyond predefined categories. However, existing methods typically predict segmentation masks with simple forward inference, lacking explicit reasoning and interpretability. This makes it challenging for OVS model to distinguish similar categories in open-world settings due to the lack of contextual understanding and discriminative visual cues. To address this limitation, we propose a step-by-step visual reasoning framework for open-vocabulary segmentation, named OpenSeg-R. The proposed OpenSeg-R leverages Large Multimodal Models (LMMs) to perform hierarchical visual reasoning before segmentation. Specifically, we generate both generic and image-specific reasoning for each image, forming structured triplets that explain the visual reason for objects in a coarse-to-fine manner. Based on these reasoning steps, we can compose detailed description prompts, and feed them to the segmentor to produce more accurate segmentation masks. To the best of our knowledge, OpenSeg-R is the first framework to introduce explicit step-by-step visual reasoning into OVS. Experimental results demonstrate that OpenSeg-R significantly outperforms state-of-the-art methods on open-vocabulary semantic segmentation across five benchmark datasets. Moreover, it achieves consistent gains across all metrics on open-vocabulary panoptic segmentation. Qualitative results further highlight the effectiveness of our reasoning-guided framework in improving both segmentation precision and interpretability. Our code is publicly available at https://github.com/Hanzy1996/OpenSeg-R.
Domain Disentangled Generative Adversarial Network for Zero-Shot Sketch-Based 3D Shape Retrieval
Feb 24, 2022



Sketch-based 3D shape retrieval is a challenging task due to the large domain discrepancy between sketches and 3D shapes. Since existing methods are trained and evaluated on the same categories, they cannot effectively recognize the categories that have not been used during training. In this paper, we propose a novel domain disentangled generative adversarial network (DD-GAN) for zero-shot sketch-based 3D retrieval, which can retrieve the unseen categories that are not accessed during training. Specifically, we first generate domain-invariant features and domain-specific features by disentangling the learned features of sketches and 3D shapes, where the domain-invariant features are used to align with the corresponding word embeddings. Then, we develop a generative adversarial network that combines the domainspecific features of the seen categories with the aligned domain-invariant features to synthesize samples, where the synthesized samples of the unseen categories are generated by using the corresponding word embeddings. Finally, we use the synthesized samples of the unseen categories combined with the real samples of the seen categories to train the network for retrieval, so that the unseen categories can be recognized. In order to reduce the domain shift between the synthesized domain and the real domain, we adopt the transductive setting to reduce the gap between the distributions of the synthesized unseen categories and real unseen categories. Extensive experiments on the SHREC'13 and SHREC'14 datasets show that our method significantly improves the retrieval performance of the unseen categories.
Contrastive Embedding for Generalized Zero-Shot Learning
Mar 30, 2021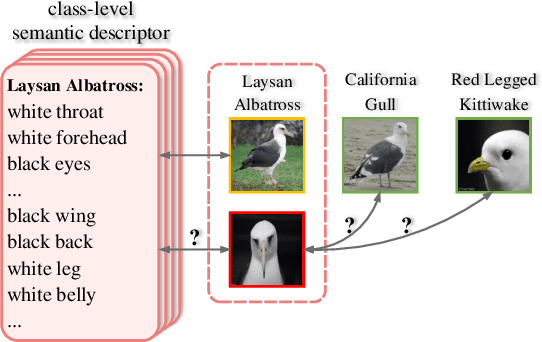
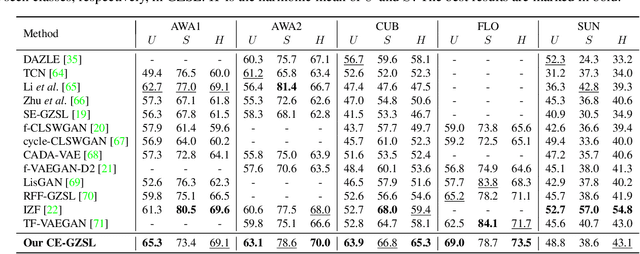

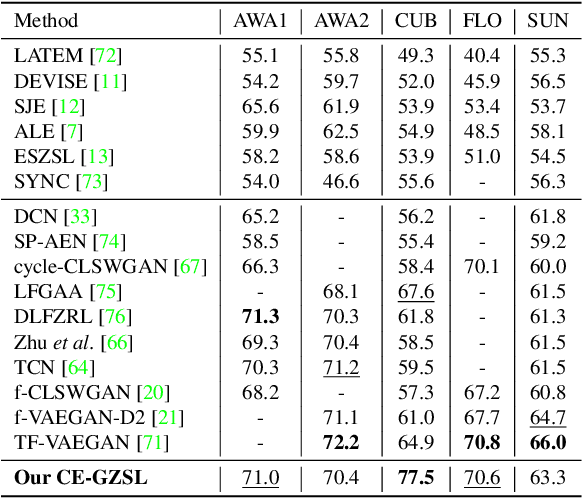
Generalized zero-shot learning (GZSL) aims to recognize objects from both seen and unseen classes, when only the labeled examples from seen classes are provided. Recent feature generation methods learn a generative model that can synthesize the missing visual features of unseen classes to mitigate the data-imbalance problem in GZSL. However, the original visual feature space is suboptimal for GZSL classification since it lacks discriminative information. To tackle this issue, we propose to integrate the generation model with the embedding model, yielding a hybrid GZSL framework. The hybrid GZSL approach maps both the real and the synthetic samples produced by the generation model into an embedding space, where we perform the final GZSL classification. Specifically, we propose a contrastive embedding (CE) for our hybrid GZSL framework. The proposed contrastive embedding can leverage not only the class-wise supervision but also the instance-wise supervision, where the latter is usually neglected by existing GZSL researches. We evaluate our proposed hybrid GZSL framework with contrastive embedding, named CE-GZSL, on five benchmark datasets. The results show that our CEGZSL method can outperform the state-of-the-arts by a significant margin on three datasets. Our codes are available on https://github.com/Hanzy1996/CE-GZSL.
Learning the Redundancy-free Features for Generalized Zero-Shot Object Recognition
Jun 16, 2020
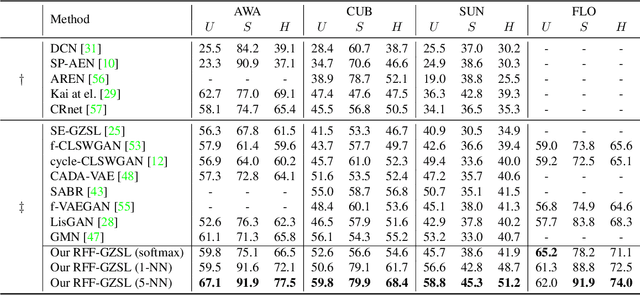

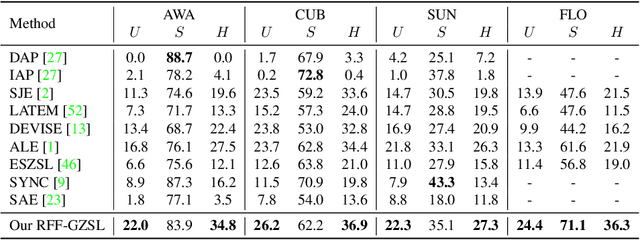
Zero-shot object recognition or zero-shot learning aims to transfer the object recognition ability among the semantically related categories, such as fine-grained animal or bird species. However, the images of different fine-grained objects tend to merely exhibit subtle differences in appearance, which will severely deteriorate zero-shot object recognition. To reduce the superfluous information in the fine-grained objects, in this paper, we propose to learn the redundancy-free features for generalized zero-shot learning. We achieve our motivation by projecting the original visual features into a new (redundancy-free) feature space and then restricting the statistical dependence between these two feature spaces. Furthermore, we require the projected features to keep and even strengthen the category relationship in the redundancy-free feature space. In this way, we can remove the redundant information from the visual features without losing the discriminative information. We extensively evaluate the performance on four benchmark datasets. The results show that our redundancy-free feature based generalized zero-shot learning (RFF-GZSL) approach can outperform the state-of-the-arts often by a large margin. Our code is available.
AIM 2019 Challenge on Image Demoireing: Methods and Results
Nov 08, 2019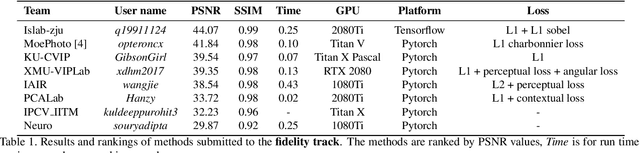
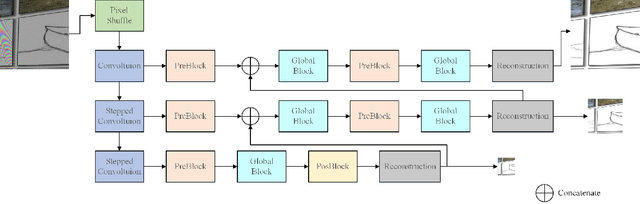
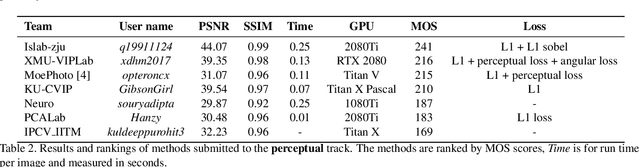
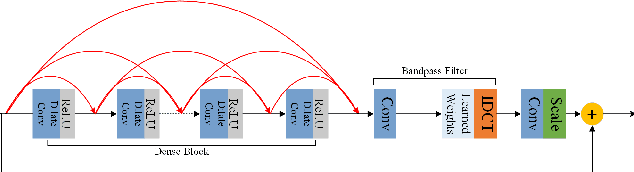
This paper reviews the first-ever image demoireing challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ICCV 2019. This paper describes the challenge, and focuses on the proposed solutions and their results. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. A new dataset, called LCDMoire was created for this challenge, and consists of 10,200 synthetically generated image pairs (moire and clean ground truth). The challenge was divided into 2 tracks. Track 1 targeted fidelity, measuring the ability of demoire methods to obtain a moire-free image compared with the ground truth, while Track 2 examined the perceptual quality of demoire methods. The tracks had 60 and 39 registered participants, respectively. A total of eight teams competed in the final testing phase. The entries span the current the state-of-the-art in the image demoireing problem.