 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Human Action Representation Learning via Cross-View Consistency Pursuit
Paper and Code
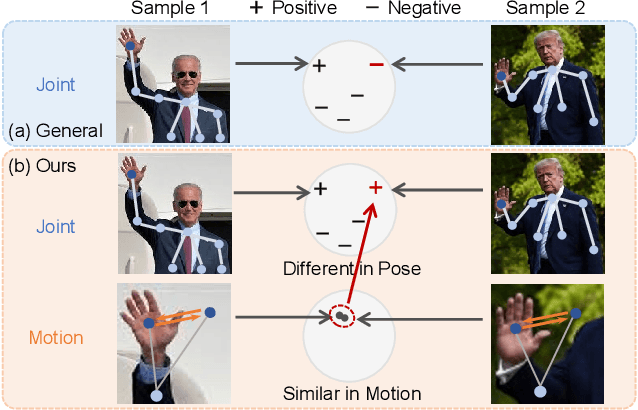
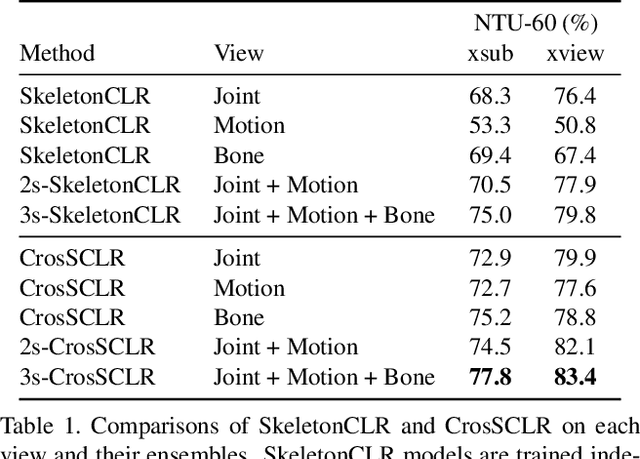
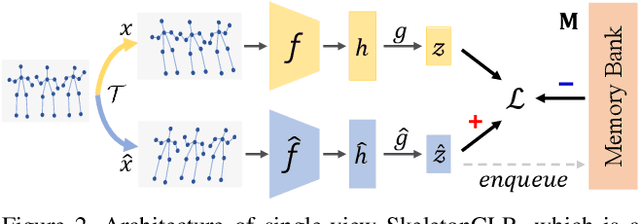
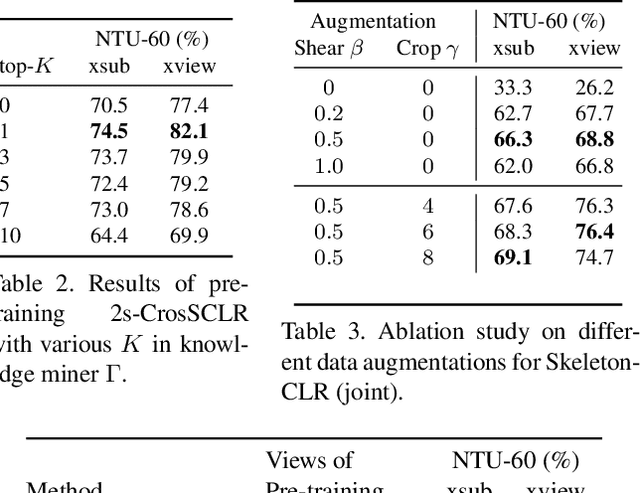
In this work, we propose a Cross-view Contrastive Learning framework for unsupervised 3D skeleton-based action Representation (CrosSCLR), by leveraging multi-view complementary supervision signal. CrosSCLR consists of both single-view contrastive learning (SkeletonCLR) and cross-view consistent knowledge mining (CVC-KM) modules, integrated in a collaborative learning manner. It is noted that CVC-KM works in such a way that high-confidence positive/negative samples and their distributions are exchanged among views according to their embedding similarity, ensuring cross-view consistency in terms of contrastive context, i.e., similar distributions. Extensive experiments show that CrosSCLR achieves remarkable action recognition results on NTU-60 and NTU-120 datasets under unsupervised settings, with observed higher-quality action representations. Our code is available at https://github.com/LinguoLi/CrosSCLR.