 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-AID: Enhancing Pre-trained Language Models with Domain Knowledge for Question Answering
Sep 22, 2021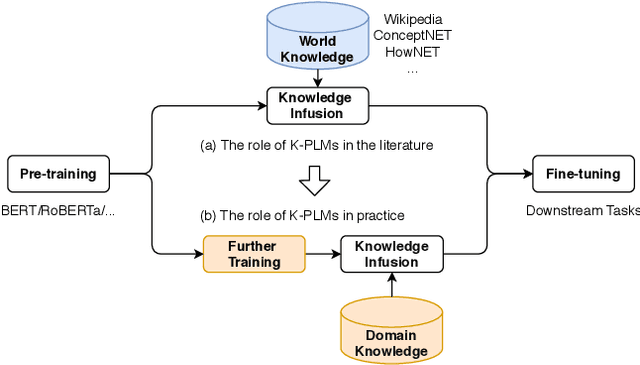

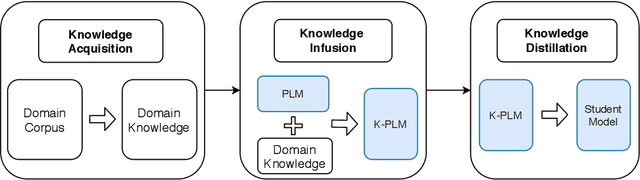
Knowledge enhanced pre-trained language models (K-PLMs) are shown to be effective for many public tasks in the literature but few of them have been successfully applied in practice. To address this problem, we propose K-AID, a systematic approach that includes a low-cost knowledge acquisition process for acquiring domain knowledge, an effective knowledge infusion module for improving model performance, and a knowledge distillation component for reducing the model size and deploying K-PLMs on resource-restricted devices (e.g., CPU) for real-world application. Importantly, instead of capturing entity knowledge like the majority of existing K-PLMs, our approach captures relational knowledge, which contributes to better-improving sentence-level text classification and text matching tasks that play a key role in question answering (QA). We conducted a set of experiments on five text classification tasks and three text matching tasks from three domains, namely E-commerce, Government, and Film&TV, and performed online A/B tests in E-commerce. Experimental results show that our approach is able to achieve substantial improvement on sentence-level question answering tasks and bring beneficial business value in industrial settings.
AliMe MKG: A Multi-modal Knowledge Graph for Live-streaming E-commerce
Sep 13, 2021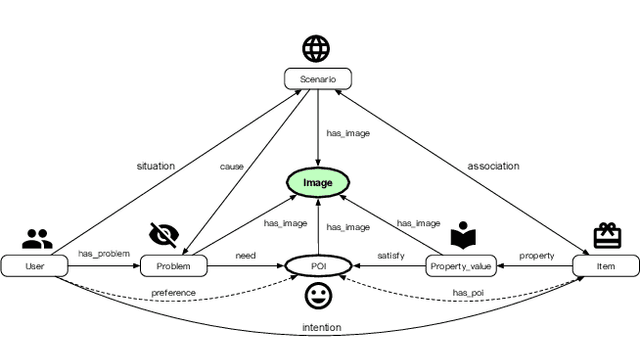
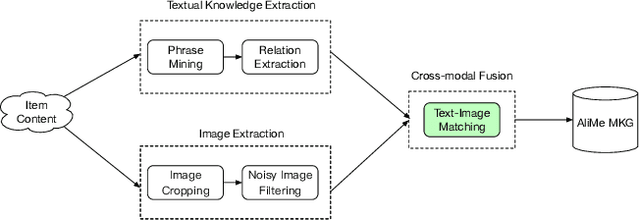
Live streaming is becoming an increasingly popular trend of sales in E-commerce. The core of live-streaming sales is to encourage customers to purchase in an online broadcasting room. To enable customers to better understand a product without jumping out, we propose AliMe MKG, a multi-modal knowledge graph that aims at providing a cognitive profile for products, through which customers are able to seek information about and understand a product. Based on the MKG, we build an online live assistant that highlights product search, product exhibition and question answering, allowing customers to skim over item list, view item details, and ask item-related questions. Our system has been launched online in the Taobao app, and currently serves hundreds of thousands of customers per day.
U-Net: Machine Reading Comprehension with Unanswerable Questions
Oct 12, 2018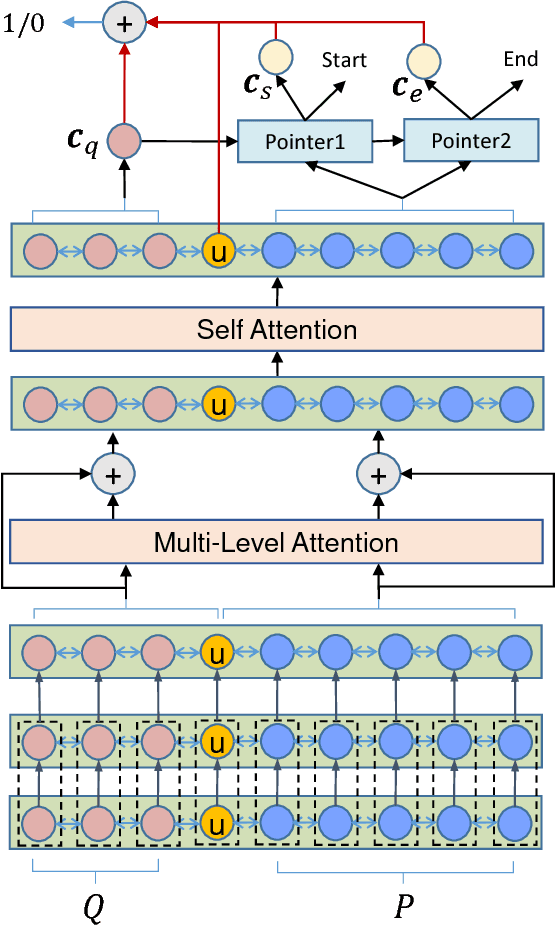
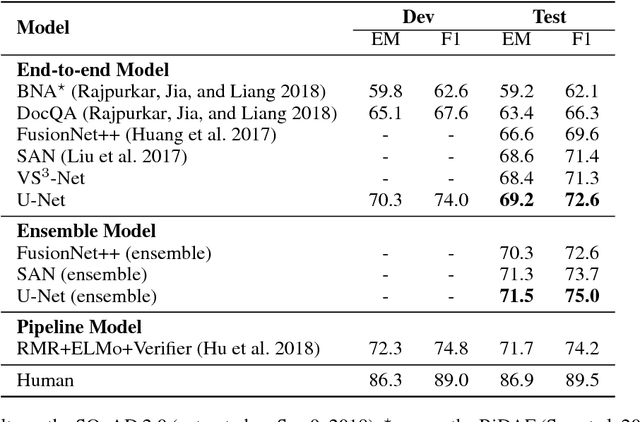

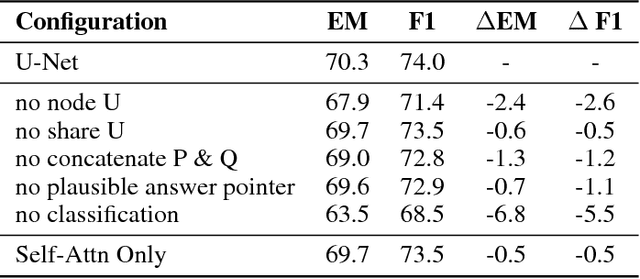
Machine reading comprehension with unanswerable questions is a new challenging task for natural language processing. A key subtask is to reliably predict whether the question is unanswerable. In this paper, we propose a unified model, called U-Net, with three important components: answer pointer, no-answer pointer, and answer verifier. We introduce a universal node and thus process the question and its context passage as a single contiguous sequence of tokens. The universal node encodes the fused information from both the question and passage, and plays an important role to predict whether the question is answerable and also greatly improves the conciseness of the U-Net. Different from the state-of-art pipeline models, U-Net can be learned in an end-to-end fashion. The experimental results on the SQuAD 2.0 dataset show that U-Net can effectively predict the unanswerability of questions and achieves an F1 score of 71.7 on SQuAD 2.0.