 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook, Listen, and Attend: Co-Attention Network for Self-Supervised Audio-Visual Representation Learning
Aug 13, 2020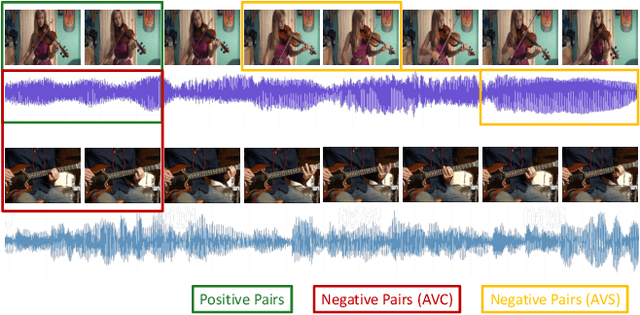
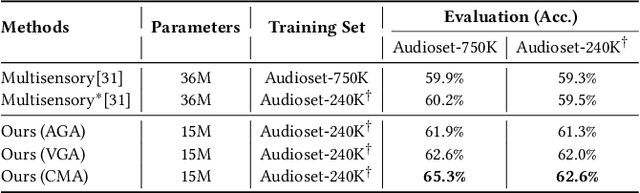
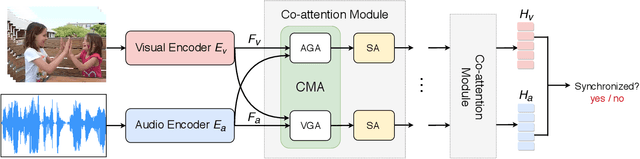
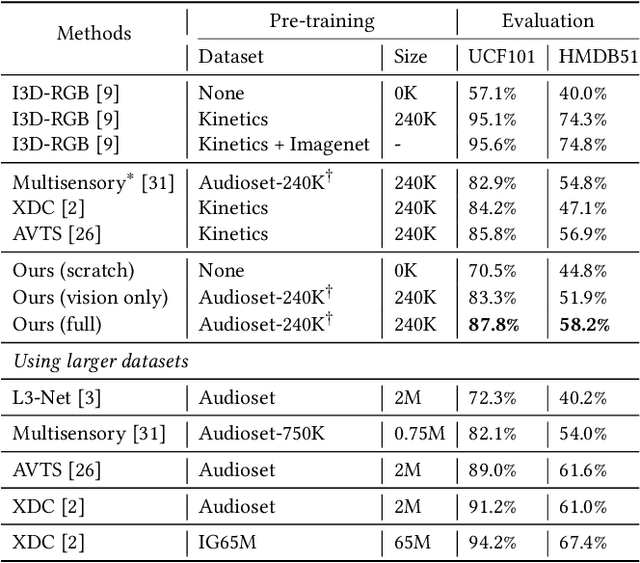
When watching videos, the occurrence of a visual event is often accompanied by an audio event, e.g., the voice of lip motion, the music of playing instruments. There is an underlying correlation between audio and visual events, which can be utilized as free supervised information to train a neural network by solving the pretext task of audio-visual synchronization. In this paper, we propose a novel self-supervised framework with co-attention mechanism to learn generic cross-modal representations from unlabelled videos in the wild, and further benefit downstream tasks. Specifically, we explore three different co-attention modules to focus on discriminative visual regions correlated to the sounds and introduce the interactions between them. Experiments show that our model achieves state-of-the-art performance on the pretext task while having fewer parameters compared with existing methods. To further evaluate the generalizability and transferability of our approach, we apply the pre-trained model on two downstream tasks, i.e., sound source localization and action recognition. Extensive experiments demonstrate that our model provides competitive results with other self-supervised methods, and also indicate that our approach can tackle the challenging scenes which contain multiple sound sources.