 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeep it Consistent: Topic-Aware Storytelling from an Image Stream via Iterative Multi-agent Communication
Paper and Code
Nov 11, 2019
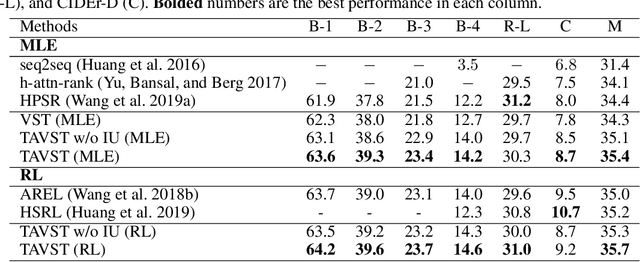
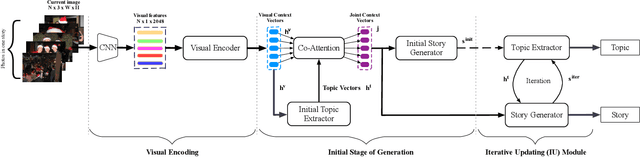
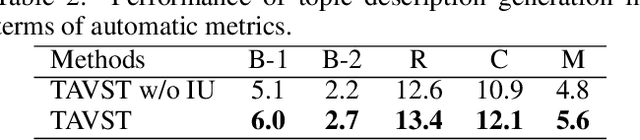
Visual storytelling aims to generate a narrative paragraph from a sequence of images automatically. Existing approaches construct text description independently for each image and roughly concatenate them as a story, which leads to the problem of generating semantically incoherent content. In this paper, we proposed a new way for visual storytelling by introducing a topic description task to detect the global semantic context of an image stream. A story is then constructed with the guidance of the topic description. In order to combine the two generation tasks, we propose a multi-agent communication framework that regards the topic description generator and the story generator as two agents and learn them simultaneously via iterative updating mechanism. We validate our approach on VIST, where quantitative results, ablations, and human evaluation demonstrate our method's good ability in generating stories with higher quality compared to state-of-the-art methods.