 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter than BERT but Worse than Baseline
May 12, 2021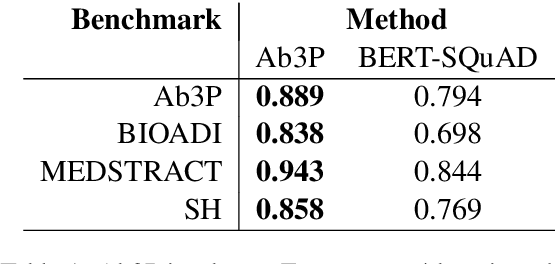
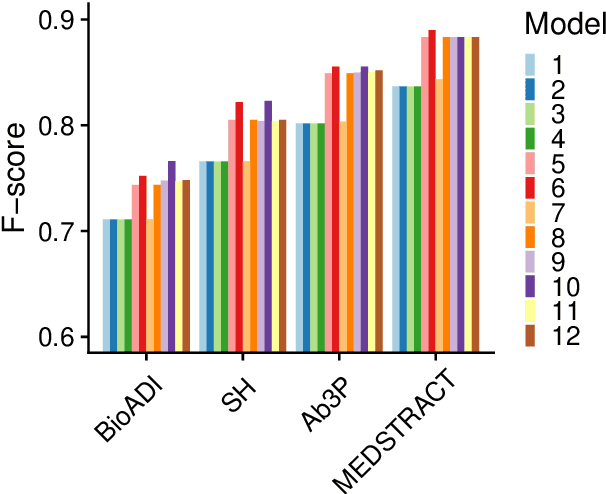
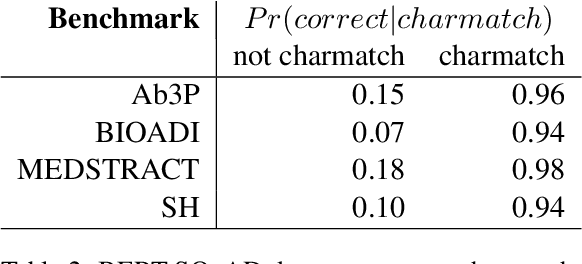
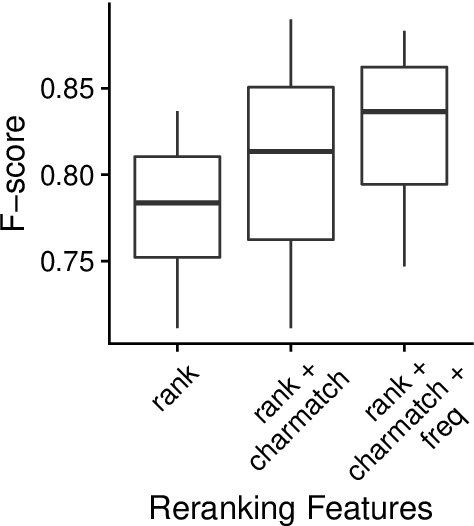
This paper compares BERT-SQuAD and Ab3P on the Abbreviation Definition Identification (ADI) task. ADI inputs a text and outputs short forms (abbreviations/acronyms) and long forms (expansions). BERT with reranking improves over BERT without reranking but fails to reach the Ab3P rule-based baseline. What is BERT missing? Reranking introduces two new features: charmatch and freq. The first feature identifies opportunities to take advantage of character constraints in acronyms and the second feature identifies opportunities to take advantage of frequency constraints across documents.
NEJM-enzh: A Parallel Corpus for English-Chinese Translation in the Biomedical Domain
May 18, 2020


Machine translation requires large amounts of parallel text. While such datasets are abundant in domains such as newswire, they are less accessible in the biomedical domain. Chinese and English are two of the most widely spoken languages, yet to our knowledge a parallel corpus in the biomedical domain does not exist for this language pair. In this study, we develop an effective pipeline to acquire and process an English-Chinese parallel corpus, consisting of about 100,000 sentence pairs and 3,000,000 tokens on each side, from the New England Journal of Medicine (NEJM). We show that training on out-of-domain data and fine-tuning with as few as 4,000 NEJM sentence pairs improve translation quality by 25.3 (13.4) BLEU for en$\to$zh (zh$\to$en) directions. Translation quality continues to improve at a slower pace on larger in-domain datasets, with an increase of 33.0 (24.3) BLEU for en$\to$zh (zh$\to$en) directions on the full dataset.