 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge vocabulary speech recognition for languages of Africa: multilingual modeling and self-supervised learning
Aug 05, 2022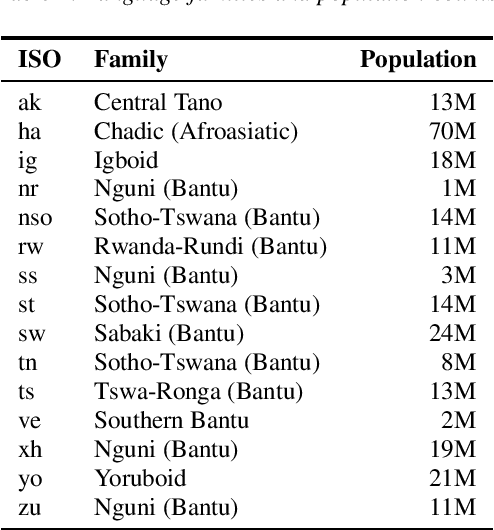
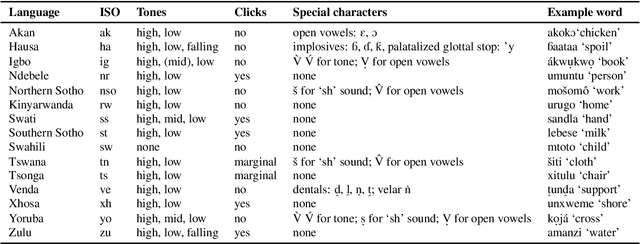
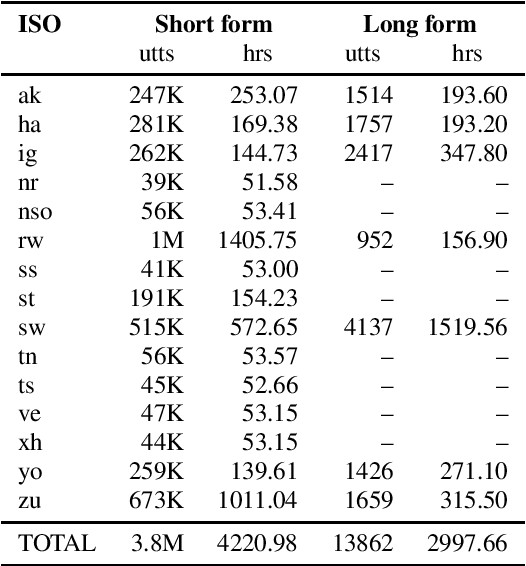
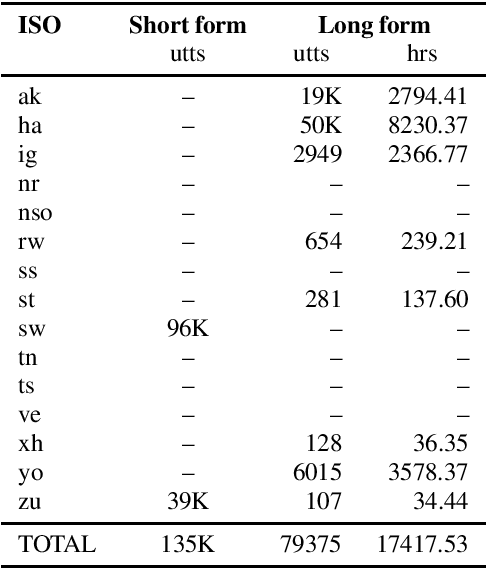
Almost none of the 2,000+ languages spoken in Africa have widely available automatic speech recognition systems, and the required data is also only available for a few languages. We have experimented with two techniques which may provide pathways to large vocabulary speech recognition for African languages: multilingual modeling and self-supervised learning. We gathered available open source data and collected data for 15 languages, and trained experimental models using these techniques. Our results show that pooling the small amounts of data available in multilingual end-to-end models, and pre-training on unsupervised data can help improve speech recognition quality for many African languages.
Capitalization Normalization for Language Modeling with an Accurate and Efficient Hierarchical RNN Model
Feb 16, 2022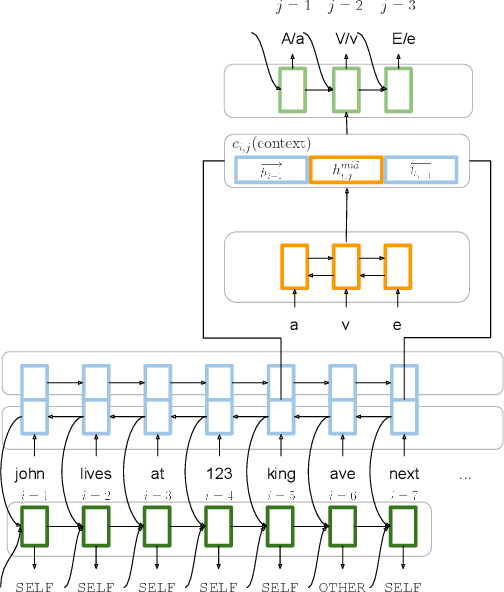
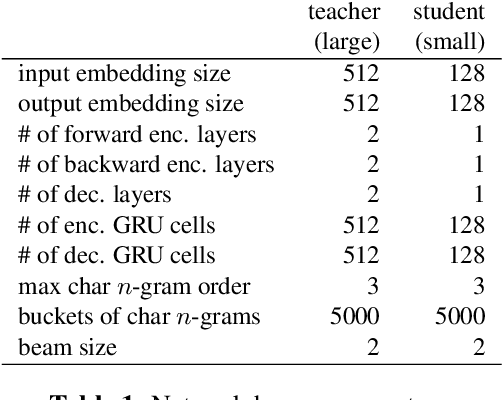
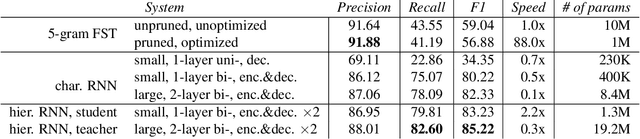

Capitalization normalization (truecasing) is the task of restoring the correct case (uppercase or lowercase) of noisy text. We propose a fast, accurate and compact two-level hierarchical word-and-character-based recurrent neural network model. We use the truecaser to normalize user-generated text in a Federated Learning framework for language modeling. A case-aware language model trained on this normalized text achieves the same perplexity as a model trained on text with gold capitalization. In a real user A/B experiment, we demonstrate that the improvement translates to reduced prediction error rates in a virtual keyboard application. Similarly, in an ASR language model fusion experiment, we show reduction in uppercase character error rate and word error rate.
Position-Invariant Truecasing with a Word-and-Character Hierarchical Recurrent Neural Network
Sep 01, 2021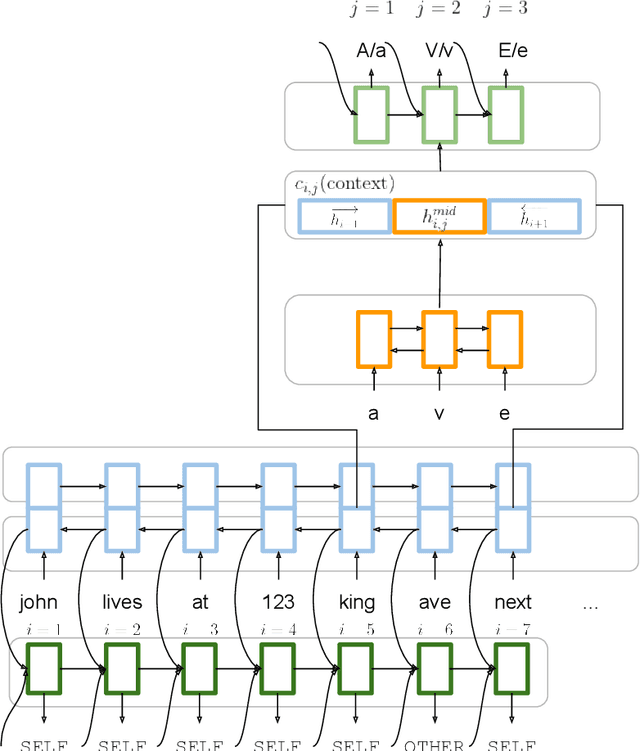
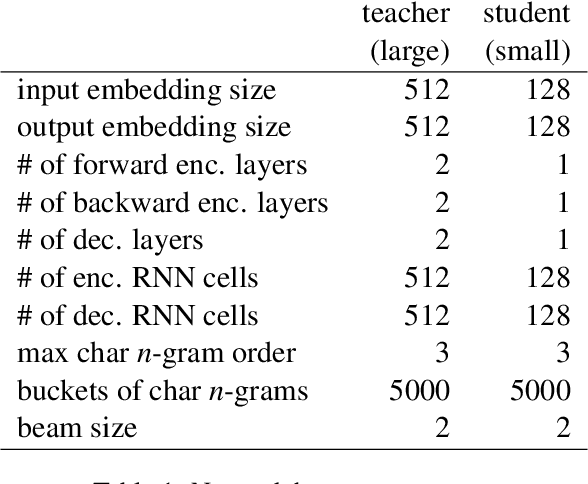

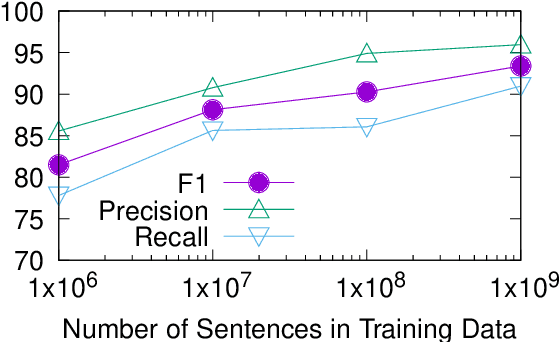
Truecasing is the task of restoring the correct case (uppercase or lowercase) of noisy text generated either by an automatic system for speech recognition or machine translation or by humans. It improves the performance of downstream NLP tasks such as named entity recognition and language modeling. We propose a fast, accurate and compact two-level hierarchical word-and-character-based recurrent neural network model, the first of its kind for this problem. Using sequence distillation, we also address the problem of truecasing while ignoring token positions in the sentence, i.e. in a position-invariant manner.