Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge vocabulary speech recognition for languages of Africa: multilingual modeling and self-supervised learning
Paper and Code
Aug 05, 2022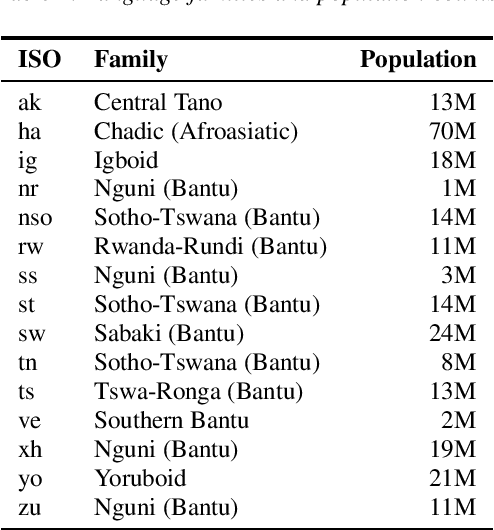
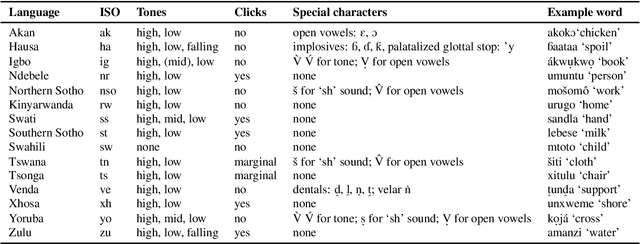
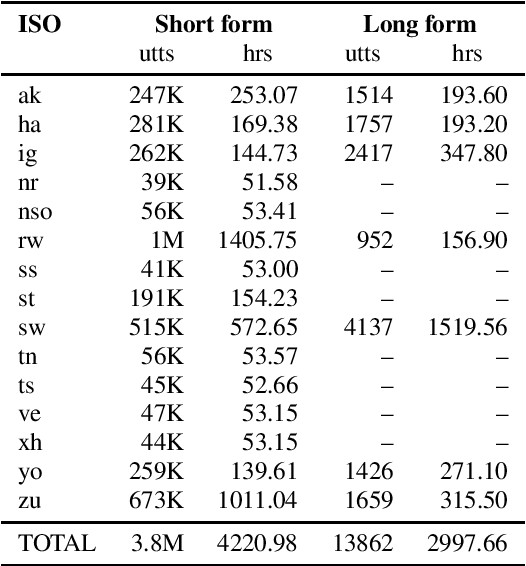
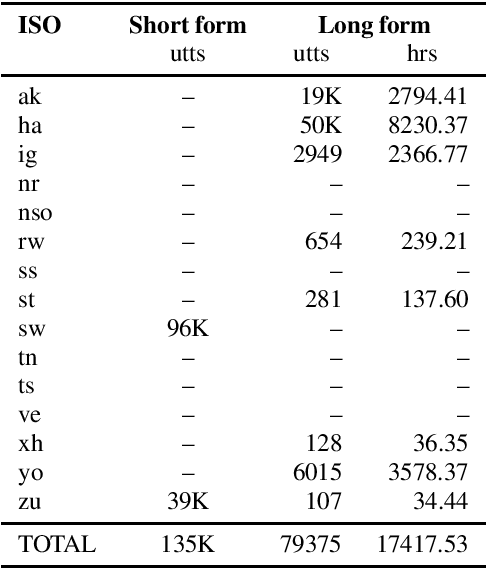
Almost none of the 2,000+ languages spoken in Africa have widely available automatic speech recognition systems, and the required data is also only available for a few languages. We have experimented with two techniques which may provide pathways to large vocabulary speech recognition for African languages: multilingual modeling and self-supervised learning. We gathered available open source data and collected data for 15 languages, and trained experimental models using these techniques. Our results show that pooling the small amounts of data available in multilingual end-to-end models, and pre-training on unsupervised data can help improve speech recognition quality for many African languages.
View paper on