 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Modeling For Spoken Language Identification
Sep 19, 2023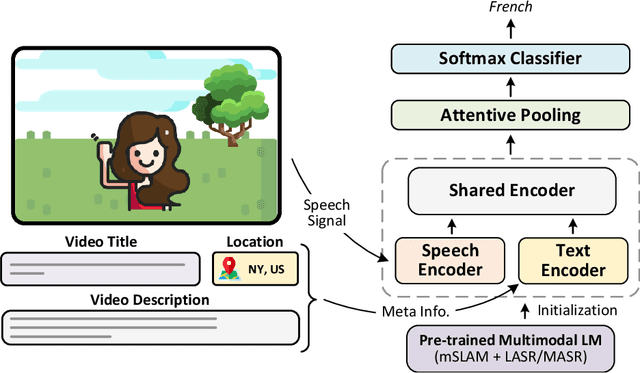
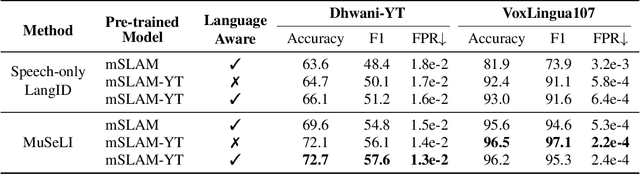
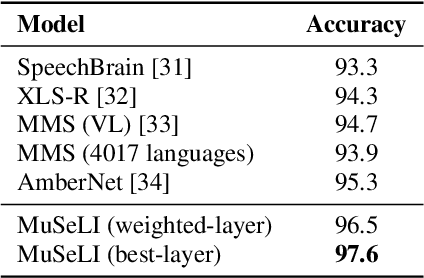
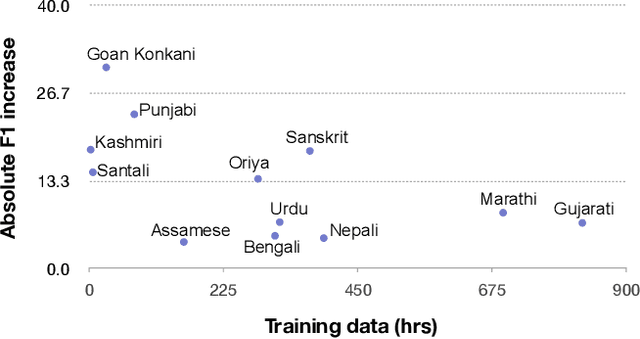
Spoken language identification refers to the task of automatically predicting the spoken language in a given utterance. Conventionally, it is modeled as a speech-based language identification task. Prior techniques have been constrained to a single modality; however in the case of video data there is a wealth of other metadata that may be beneficial for this task. In this work, we propose MuSeLI, a Multimodal Spoken Language Identification method, which delves into the use of various metadata sources to enhance language identification. Our study reveals that metadata such as video title, description and geographic location provide substantial information to identify the spoken language of the multimedia recording. We conduct experiments using two diverse public datasets of YouTube videos, and obtain state-of-the-art results on the language identification task. We additionally conduct an ablation study that describes the distinct contribution of each modality for language recognition.
Large vocabulary speech recognition for languages of Africa: multilingual modeling and self-supervised learning
Aug 05, 2022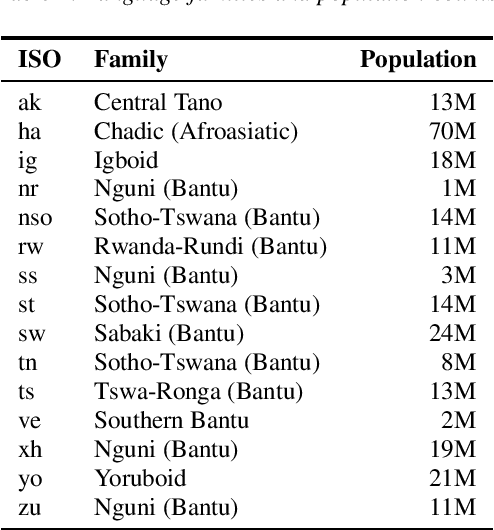
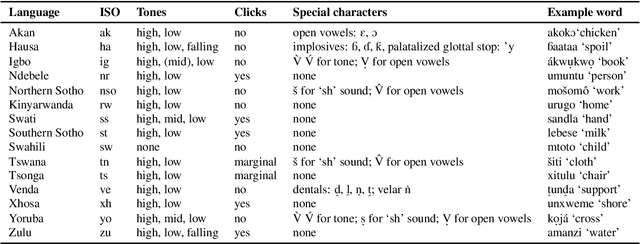
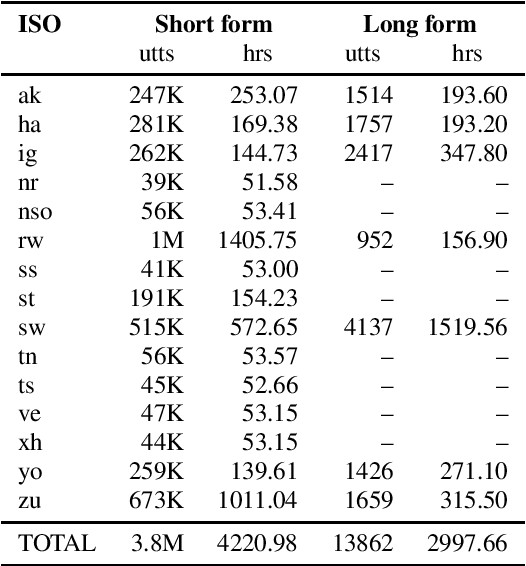
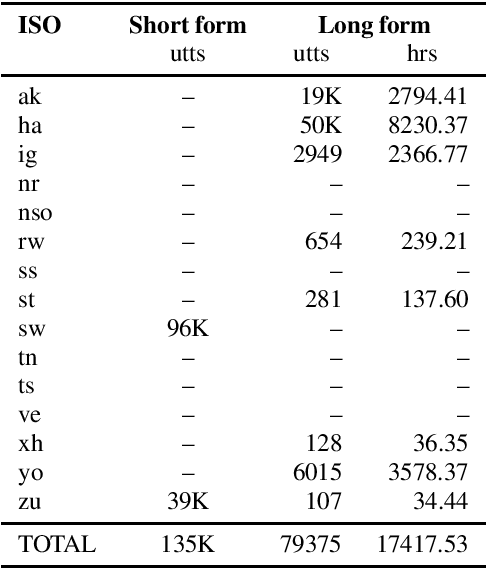
Almost none of the 2,000+ languages spoken in Africa have widely available automatic speech recognition systems, and the required data is also only available for a few languages. We have experimented with two techniques which may provide pathways to large vocabulary speech recognition for African languages: multilingual modeling and self-supervised learning. We gathered available open source data and collected data for 15 languages, and trained experimental models using these techniques. Our results show that pooling the small amounts of data available in multilingual end-to-end models, and pre-training on unsupervised data can help improve speech recognition quality for many African languages.
Text Normalization for Low-Resource Languages of Africa
Mar 29, 2021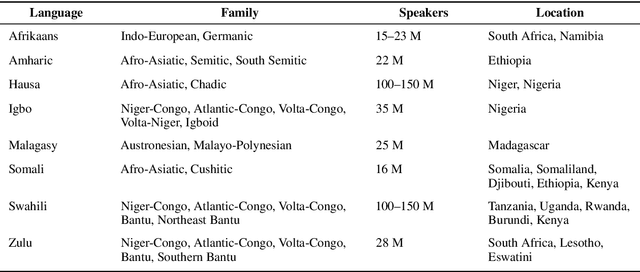
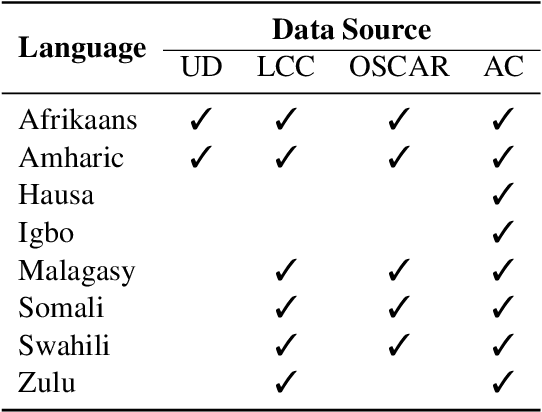

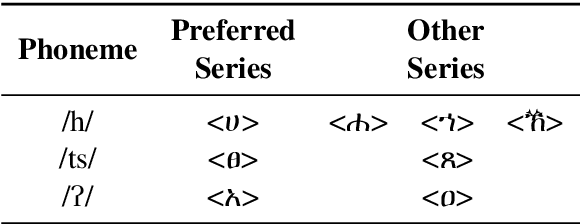
Training data for machine learning models can come from many different sources, which can be of dubious quality. For resource-rich languages like English, there is a lot of data available, so we can afford to throw out the dubious data. For low-resource languages where there is much less data available, we can't necessarily afford to throw out the dubious data, in case we end up with a training set which is too small to train a model. In this study, we examine the effects of text normalization and data set quality for a set of low-resource languages of Africa -- Afrikaans, Amharic, Hausa, Igbo, Malagasy, Somali, Swahili, and Zulu. We describe our text normalizer which we built in the Pynini framework, a Python library for finite state transducers, and our experiments in training language models for African languages using the Natural Language Toolkit (NLTK), an open-source Python library for NLP.
Mining Large-Scale Low-Resource Pronunciation Data From Wikipedia
Jan 27, 2021



Pronunciation modeling is a key task for building speech technology in new languages, and while solid grapheme-to-phoneme (G2P) mapping systems exist, language coverage can stand to be improved. The information needed to build G2P models for many more languages can easily be found on Wikipedia, but unfortunately, it is stored in disparate formats. We report on a system we built to mine a pronunciation data set in 819 languages from loosely structured tables within Wikipedia. The data includes phoneme inventories, and for 63 low-resource languages, also includes the grapheme-to-phoneme (G2P) mapping. 54 of these languages do not have easily findable G2P mappings online otherwise. We turned the information from Wikipedia into a structured, machine-readable TSV format, and make the resulting data set publicly available so it can be improved further and used in a variety of applications involving low-resource languages.