 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Normalization for Low-Resource Languages of Africa
Mar 29, 2021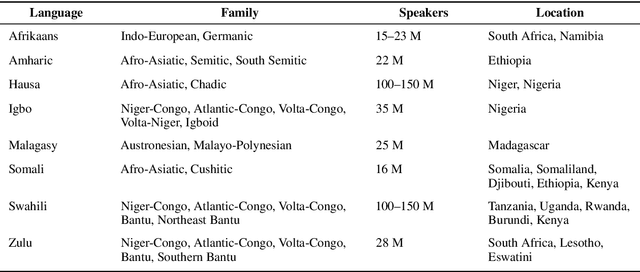
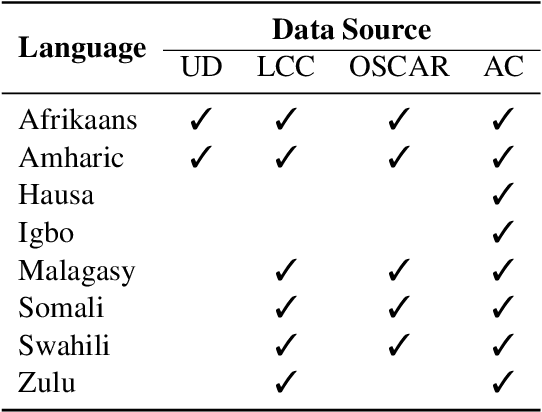

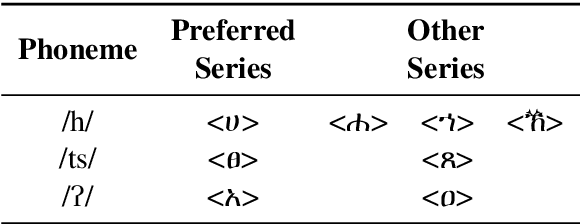
Training data for machine learning models can come from many different sources, which can be of dubious quality. For resource-rich languages like English, there is a lot of data available, so we can afford to throw out the dubious data. For low-resource languages where there is much less data available, we can't necessarily afford to throw out the dubious data, in case we end up with a training set which is too small to train a model. In this study, we examine the effects of text normalization and data set quality for a set of low-resource languages of Africa -- Afrikaans, Amharic, Hausa, Igbo, Malagasy, Somali, Swahili, and Zulu. We describe our text normalizer which we built in the Pynini framework, a Python library for finite state transducers, and our experiments in training language models for African languages using the Natural Language Toolkit (NLTK), an open-source Python library for NLP.
Writing Across the World's Languages: Deep Internationalization for Gboard, the Google Keyboard
Dec 03, 2019This technical report describes our deep internationalization program for Gboard, the Google Keyboard. Today, Gboard supports 900+ language varieties across 70+ writing systems, and this report describes how and why we have been adding support for hundreds of language varieties from around the globe. Many languages of the world are increasingly used in writing on an everyday basis, and we describe the trends we see. We cover technological and logistical challenges in scaling up a language technology product like Gboard to hundreds of language varieties, and describe how we built systems and processes to operate at scale. Finally, we summarize the key take-aways from user studies we ran with speakers of hundreds of languages from around the world.