 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence-Select: Large-Scale Language Model Data Selection for Rare-Word Speech Recognition
Paper and Code
Mar 09, 2022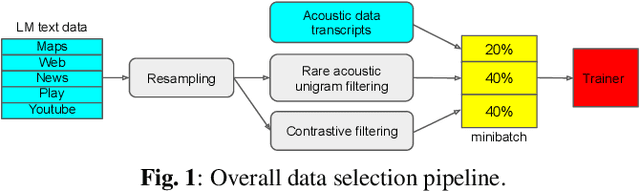
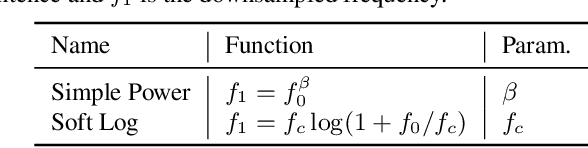
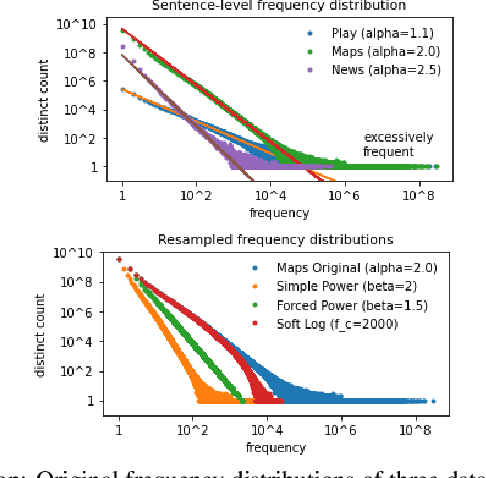
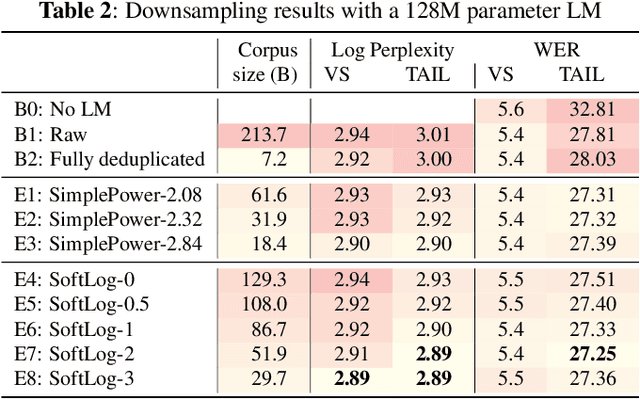
Language model fusion helps smart assistants recognize words which are rare in acoustic data but abundant in text-only corpora (typed search logs). However, such corpora have properties that hinder downstream performance, including being (1) too large, (2) beset with domain-mismatched content, and (3) heavy-headed rather than heavy-tailed (excessively many duplicate search queries such as "weather"). We show that three simple strategies for selecting language modeling data can dramatically improve rare-word recognition without harming overall performance. First, to address the heavy-headedness, we downsample the data according to a soft log function, which tunably reduces high frequency (head) sentences. Second, to encourage rare-word exposure, we explicitly filter for words rare in the acoustic data. Finally, we tackle domain-mismatch via perplexity-based contrastive selection, filtering for examples matched to the target domain. We down-select a large corpus of web search queries by a factor of 53x and achieve better LM perplexities than without down-selection. When shallow-fused with a state-of-the-art, production speech engine, our LM achieves WER reductions of up to 24% relative on rare-word sentences (without changing overall WER) compared to a baseline LM trained on the raw corpus. These gains are further validated through favorable side-by-side evaluations on live voice search traffic.