 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2E Segmenter: Joint Segmenting and Decoding for Long-Form ASR
Paper and Code
Apr 22, 2022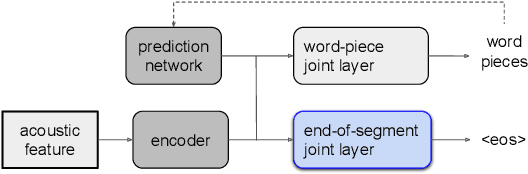
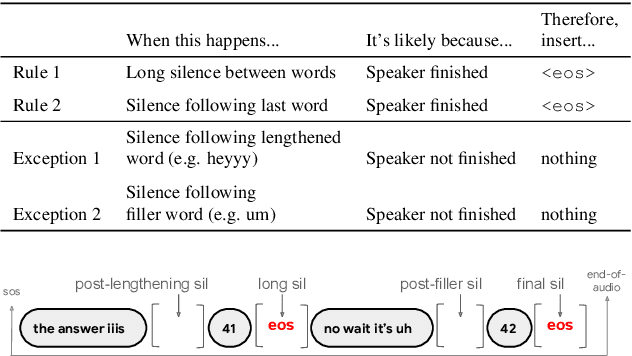
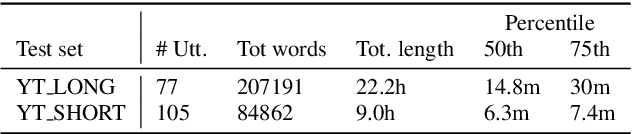
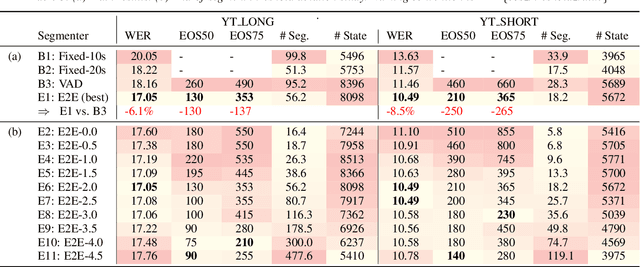
Improving the performance of end-to-end ASR models on long utterances ranging from minutes to hours in length is an ongoing challenge in speech recognition. A common solution is to segment the audio in advance using a separate voice activity detector (VAD) that decides segment boundary locations based purely on acoustic speech/non-speech information. VAD segmenters, however, may be sub-optimal for real-world speech where, e.g., a complete sentence that should be taken as a whole may contain hesitations in the middle ("set an alarm for... 5 o'clock"). We propose to replace the VAD with an end-to-end ASR model capable of predicting segment boundaries in a streaming fashion, allowing the segmentation decision to be conditioned not only on better acoustic features but also on semantic features from the decoded text with negligible extra computation. In experiments on real world long-form audio (YouTube) with lengths of up to 30 minutes, we demonstrate 8.5% relative WER improvement and 250 ms reduction in median end-of-segment latency compared to the VAD segmenter baseline on a state-of-the-art Conformer RNN-T model.