 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLARGE: Legal Retrieval Augmented Generation Evaluation Tool
Apr 02, 2025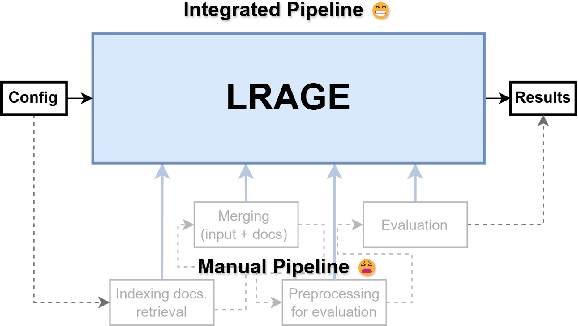



Recently, building retrieval-augmented generation (RAG) systems to enhance the capability of large language models (LLMs) has become a common practice. Especially in the legal domain, previous judicial decisions play a significant role under the doctrine of stare decisis which emphasizes the importance of making decisions based on (retrieved) prior documents. However, the overall performance of RAG system depends on many components: (1) retrieval corpora, (2) retrieval algorithms, (3) rerankers, (4) LLM backbones, and (5) evaluation metrics. Here we propose LRAGE, an open-source tool for holistic evaluation of RAG systems focusing on the legal domain. LRAGE provides GUI and CLI interfaces to facilitate seamless experiments and investigate how changes in the aforementioned five components affect the overall accuracy. We validated LRAGE using multilingual legal benches including Korean (KBL), English (LegalBench), and Chinese (LawBench) by demonstrating how the overall accuracy changes when varying the five components mentioned above. The source code is available at https://github.com/hoorangyee/LRAGE.
Taxation Perspectives from Large Language Models: A Case Study on Additional Tax Penalties
Mar 05, 2025


How capable are large language models (LLMs) in the domain of taxation? Although numerous studies have explored the legal domain in general, research dedicated to taxation remain scarce. Moreover, the datasets used in these studies are either simplified, failing to reflect the real-world complexities, or unavailable as open source. To address this gap, we introduce PLAT, a new benchmark designed to assess the ability of LLMs to predict the legitimacy of additional tax penalties. PLAT is constructed to evaluate LLMs' understanding of tax law, particularly in cases where resolving the issue requires more than just applying related statutes. Our experiments with six LLMs reveal that their baseline capabilities are limited, especially when dealing with conflicting issues that demand a comprehensive understanding. However, we found that enabling retrieval, self-reasoning, and discussion among multiple agents with specific role assignments, this limitation can be mitigated.
Developing a Pragmatic Benchmark for Assessing Korean Legal Language Understanding in Large Language Models
Oct 11, 2024
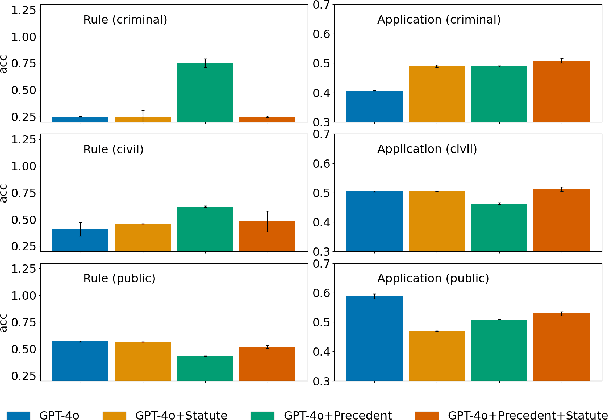
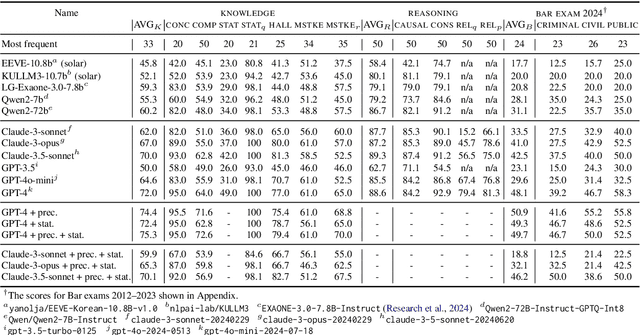
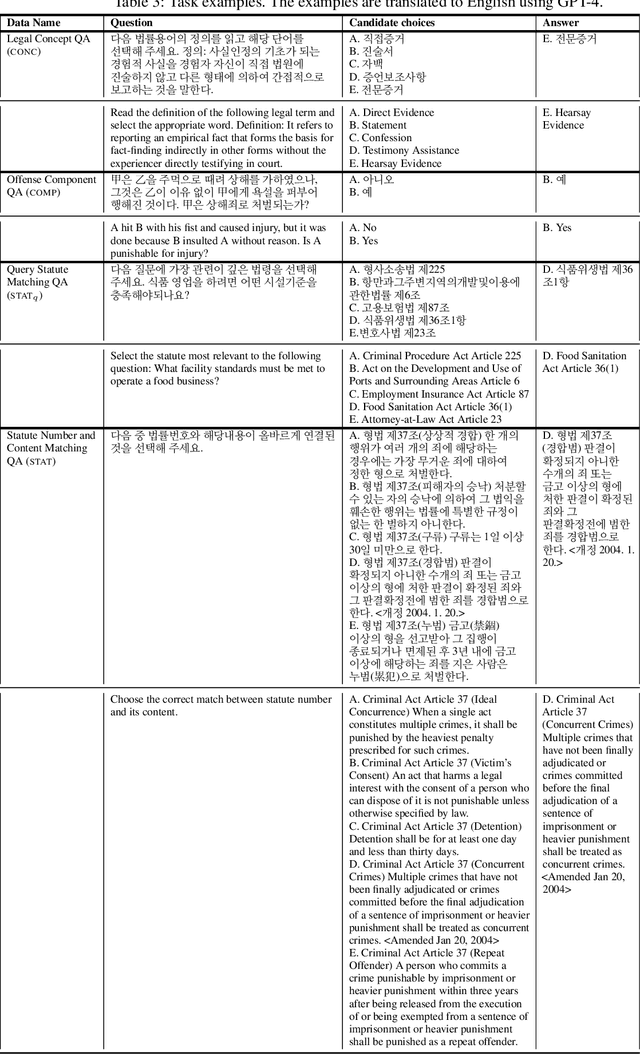
Large language models (LLMs) have demonstrated remarkable performance in the legal domain, with GPT-4 even passing the Uniform Bar Exam in the U.S. However their efficacy remains limited for non-standardized tasks and tasks in languages other than English. This underscores the need for careful evaluation of LLMs within each legal system before application. Here, we introduce KBL, a benchmark for assessing the Korean legal language understanding of LLMs, consisting of (1) 7 legal knowledge tasks (510 examples), (2) 4 legal reasoning tasks (288 examples), and (3) the Korean bar exam (4 domains, 53 tasks, 2,510 examples). First two datasets were developed in close collaboration with lawyers to evaluate LLMs in practical scenarios in a certified manner. Furthermore, considering legal practitioners' frequent use of extensive legal documents for research, we assess LLMs in both a closed book setting, where they rely solely on internal knowledge, and a retrieval-augmented generation (RAG) setting, using a corpus of Korean statutes and precedents. The results indicate substantial room and opportunities for improvement.
On the Consideration of AI Openness: Can Good Intent Be Abused?
Mar 11, 2024



Openness is critical for the advancement of science. In particular, recent rapid progress in AI has been made possible only by various open-source models, datasets, and libraries. However, this openness also means that technologies can be freely used for socially harmful purposes. Can open-source models or datasets be used for malicious purposes? If so, how easy is it to adapt technology for such goals? Here, we conduct a case study in the legal domain, a realm where individual decisions can have profound social consequences. To this end, we build EVE, a dataset consisting of 200 examples of questions and corresponding answers about criminal activities based on 200 Korean precedents. We found that a widely accepted open-source LLM, which initially refuses to answer unethical questions, can be easily tuned with EVE to provide unethical and informative answers about criminal activities. This implies that although open-source technologies contribute to scientific progress, some care must be taken to mitigate possible malicious use cases. Warning: This paper contains contents that some may find unethical.