 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNESTLE: a No-Code Tool for Statistical Analysis of Legal Corpus
Sep 08, 2023



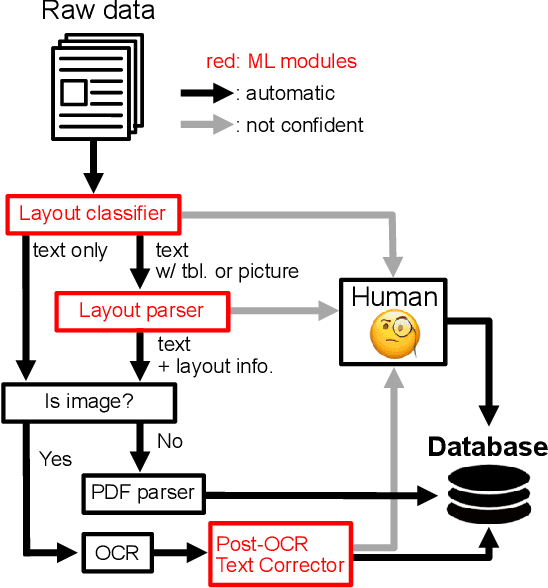
The statistical analysis of large scale legal corpus can provide valuable legal insights. For such analysis one needs to (1) select a subset of the corpus using document retrieval tools, (2) structuralize text using information extraction (IE) systems, and (3) visualize the data for the statistical analysis. Each process demands either specialized tools or programming skills whereas no comprehensive unified "no-code" tools have been available. Especially for IE, if the target information is not predefined in the ontology of the IE system, one needs to build their own system. Here we provide NESTLE, a no code tool for large-scale statistical analysis of legal corpus. With NESTLE, users can search target documents, extract information, and visualize the structured data all via the chat interface with accompanying auxiliary GUI for the fine-level control. NESTLE consists of three main components: a search engine, an end-to-end IE system, and a Large Language Model (LLM) that glues the whole components together and provides the chat interface. Powered by LLM and the end-to-end IE system, NESTLE can extract any type of information that has not been predefined in the IE system opening up the possibility of unlimited customizable statistical analysis of the corpus without writing a single line of code. The use of the custom end-to-end IE system also enables faster and low-cost IE on large scale corpus. We validate our system on 15 Korean precedent IE tasks and 3 legal text classification tasks from LEXGLUE. The comprehensive experiments reveal NESTLE can achieve GPT-4 comparable performance by training the internal IE module with 4 human-labeled, and 192 LLM-labeled examples. The detailed analysis provides the insight on the trade-off between accuracy, time, and cost in building such system.
A Multi-Task Benchmark for Korean Legal Language Understanding and Judgement Prediction
Jun 10, 2022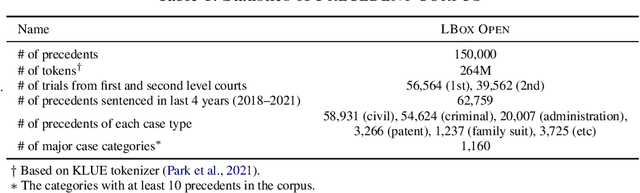
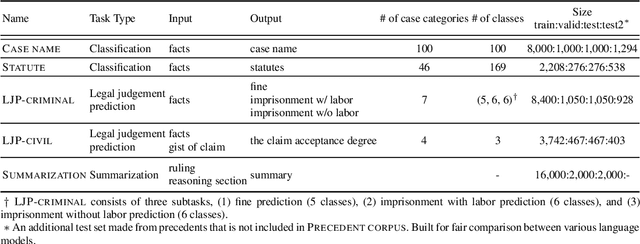
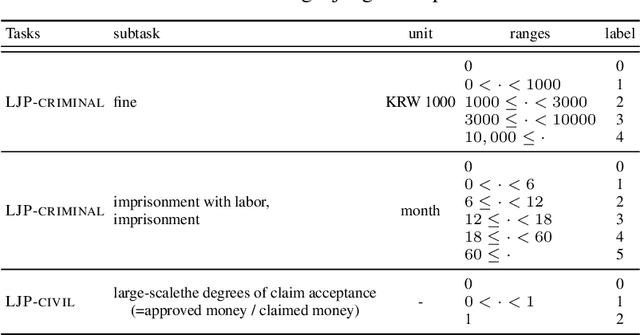
The recent advances of deep learning have dramatically changed how machine learning, especially in the domain of natural language processing, can be applied to legal domain. However, this shift to the data-driven approaches calls for larger and more diverse datasets, which are nevertheless still small in number, especially in non-English languages. Here we present the first large-scale benchmark of Korean legal AI datasets, LBox Open, that consists of one legal corpus, two classification tasks, two legal judgement prediction (LJP) tasks, and one summarization task. The legal corpus consists of 150k Korean precedents (264M tokens), of which 63k are sentenced in last 4 years and 96k are from the first and the second level courts in which factual issues are reviewed. The two classification tasks are case names (10k) and statutes (3k) prediction from the factual description of individual cases. The LJP tasks consist of (1) 11k criminal examples where the model is asked to predict fine amount, imprisonment with labor, and imprisonment without labor ranges for the given facts, and (2) 5k civil examples where the inputs are facts and claim for relief and outputs are the degrees of claim acceptance. The summarization task consists of the Supreme Court precedents and the corresponding summaries. We also release LCube, the first Korean legal language model trained on the legal corpus from this study. Given the uniqueness of the Law of South Korea and the diversity of the legal tasks covered in this work, we believe that LBox Open contributes to the multilinguality of global legal research. LBox Open and LCube will be publicly available.