 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-efficient End-to-end Information Extraction for Statistical Legal Analysis
Nov 03, 2022



Legal practitioners often face a vast amount of documents. Lawyers, for instance, search for appropriate precedents favorable to their clients, while the number of legal precedents is ever-growing. Although legal search engines can assist finding individual target documents and narrowing down the number of candidates, retrieved information is often presented as unstructured text and users have to examine each document thoroughly which could lead to information overloading. This also makes their statistical analysis challenging. Here, we present an end-to-end information extraction (IE) system for legal documents. By formulating IE as a generation task, our system can be easily applied to various tasks without domain-specific engineering effort. The experimental results of four IE tasks on Korean precedents shows that our IE system can achieve competent scores (-2.3 on average) compared to the rule-based baseline with as few as 50 training examples per task and higher score (+5.4 on average) with 200 examples. Finally, our statistical analysis on two case categories--drunk driving and fraud--with 35k precedents reveals the resulting structured information from our IE system faithfully reflects the macroscopic features of Korean legal system.
A Multi-Task Benchmark for Korean Legal Language Understanding and Judgement Prediction
Jun 10, 2022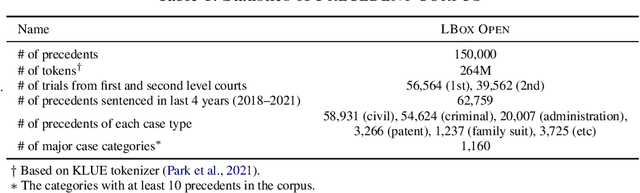
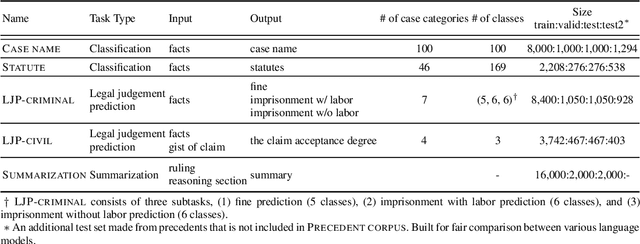
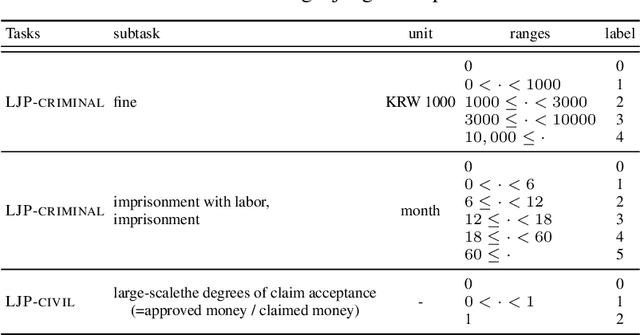
The recent advances of deep learning have dramatically changed how machine learning, especially in the domain of natural language processing, can be applied to legal domain. However, this shift to the data-driven approaches calls for larger and more diverse datasets, which are nevertheless still small in number, especially in non-English languages. Here we present the first large-scale benchmark of Korean legal AI datasets, LBox Open, that consists of one legal corpus, two classification tasks, two legal judgement prediction (LJP) tasks, and one summarization task. The legal corpus consists of 150k Korean precedents (264M tokens), of which 63k are sentenced in last 4 years and 96k are from the first and the second level courts in which factual issues are reviewed. The two classification tasks are case names (10k) and statutes (3k) prediction from the factual description of individual cases. The LJP tasks consist of (1) 11k criminal examples where the model is asked to predict fine amount, imprisonment with labor, and imprisonment without labor ranges for the given facts, and (2) 5k civil examples where the inputs are facts and claim for relief and outputs are the degrees of claim acceptance. The summarization task consists of the Supreme Court precedents and the corresponding summaries. We also release LCube, the first Korean legal language model trained on the legal corpus from this study. Given the uniqueness of the Law of South Korea and the diversity of the legal tasks covered in this work, we believe that LBox Open contributes to the multilinguality of global legal research. LBox Open and LCube will be publicly available.