 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Video Captioning using Graph-based Sentence Summarization
Jun 25, 2025Recently, dense video captioning has made attractive progress in detecting and captioning all events in a long untrimmed video. Despite promising results were achieved, most existing methods do not sufficiently explore the scene evolution within an event temporal proposal for captioning, and therefore perform less satisfactorily when the scenes and objects change over a relatively long proposal. To address this problem, we propose a graph-based partition-and-summarization (GPaS) framework for dense video captioning within two stages. For the ``partition" stage, a whole event proposal is split into short video segments for captioning at a finer level. For the ``summarization" stage, the generated sentences carrying rich description information for each segment are summarized into one sentence to describe the whole event. We particularly focus on the ``summarization" stage, and propose a framework that effectively exploits the relationship between semantic words for summarization. We achieve this goal by treating semantic words as nodes in a graph and learning their interactions by coupling Graph Convolutional Network (GCN) and Long Short Term Memory (LSTM), with the aid of visual cues. Two schemes of GCN-LSTM Interaction (GLI) modules are proposed for seamless integration of GCN and LSTM. The effectiveness of our approach is demonstrated via an extensive comparison with the state-of-the-arts methods on the two benchmarks ActivityNet Captions dataset and YouCook II dataset.
Show, Tell and Summarize: Dense Video Captioning Using Visual Cue Aided Sentence Summarization
Jun 25, 2025In this work, we propose a division-and-summarization (DaS) framework for dense video captioning. After partitioning each untrimmed long video as multiple event proposals, where each event proposal consists of a set of short video segments, we extract visual feature (e.g., C3D feature) from each segment and use the existing image/video captioning approach to generate one sentence description for this segment. Considering that the generated sentences contain rich semantic descriptions about the whole event proposal, we formulate the dense video captioning task as a visual cue aided sentence summarization problem and propose a new two stage Long Short Term Memory (LSTM) approach equipped with a new hierarchical attention mechanism to summarize all generated sentences as one descriptive sentence with the aid of visual features. Specifically, the first-stage LSTM network takes all semantic words from the generated sentences and the visual features from all segments within one event proposal as the input, and acts as the encoder to effectively summarize both semantic and visual information related to this event proposal. The second-stage LSTM network takes the output from the first-stage LSTM network and the visual features from all video segments within one event proposal as the input, and acts as the decoder to generate one descriptive sentence for this event proposal. Our comprehensive experiments on the ActivityNet Captions dataset demonstrate the effectiveness of our newly proposed DaS framework for dense video captioning.
FastMap: Fast Queries Initialization Based Vectorized HD Map Reconstruction Framework
Mar 07, 2025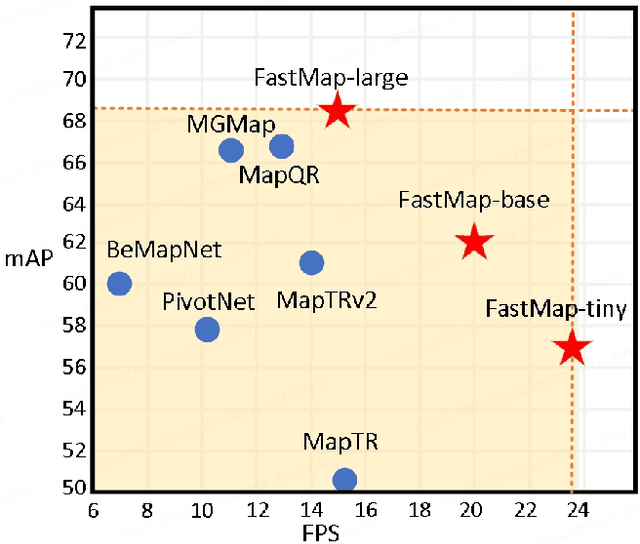
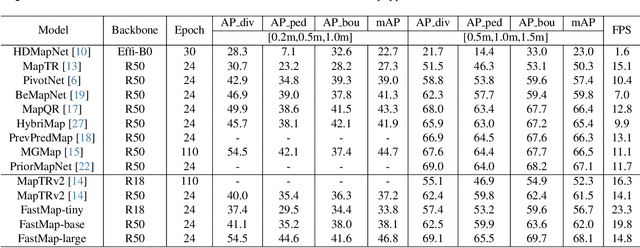
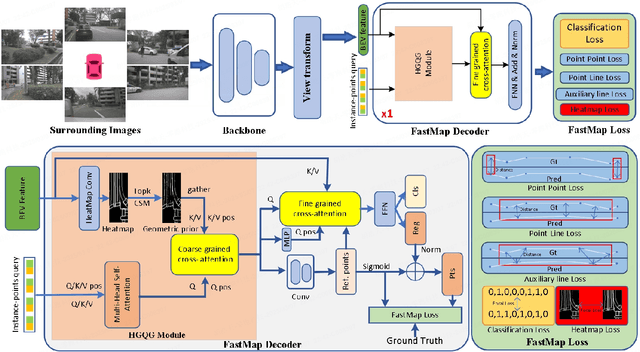
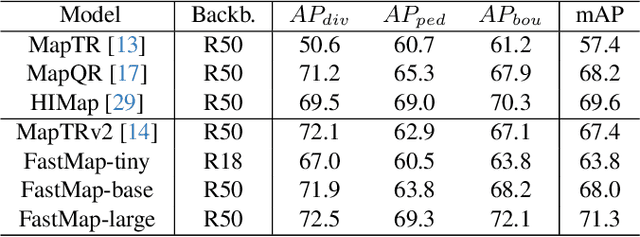
Reconstruction of high-definition maps is a crucial task in perceiving the autonomous driving environment, as its accuracy directly impacts the reliability of prediction and planning capabilities in downstream modules. Current vectorized map reconstruction methods based on the DETR framework encounter limitations due to the redundancy in the decoder structure, necessitating the stacking of six decoder layers to maintain performance, which significantly hampers computational efficiency. To tackle this issue, we introduce FastMap, an innovative framework designed to reduce decoder redundancy in existing approaches. FastMap optimizes the decoder architecture by employing a single-layer, two-stage transformer that achieves multilevel representation capabilities. Our framework eliminates the conventional practice of randomly initializing queries and instead incorporates a heatmap-guided query generation module during the decoding phase, which effectively maps image features into structured query vectors using learnable positional encoding. Additionally, we propose a geometry-constrained point-to-line loss mechanism for FastMap, which adeptly addresses the challenge of distinguishing highly homogeneous features that often arise in traditional point-to-point loss computations. Extensive experiments demonstrate that FastMap achieves state-of-the-art performance in both nuScenes and Argoverse2 datasets, with its decoder operating 3.2 faster than the baseline. Code and more demos are available at https://github.com/hht1996ok/FastMap.
LoopAnimate: Loopable Salient Object Animation
Apr 14, 2024Research on diffusion model-based video generation has advanced rapidly. However, limitations in object fidelity and generation length hinder its practical applications. Additionally, specific domains like animated wallpapers require seamless looping, where the first and last frames of the video match seamlessly. To address these challenges, this paper proposes LoopAnimate, a novel method for generating videos with consistent start and end frames. To enhance object fidelity, we introduce a framework that decouples multi-level image appearance and textual semantic information. Building upon an image-to-image diffusion model, our approach incorporates both pixel-level and feature-level information from the input image, injecting image appearance and textual semantic embeddings at different positions of the diffusion model. Existing UNet-based video generation models require to input the entire videos during training to encode temporal and positional information at once. However, due to limitations in GPU memory, the number of frames is typically restricted to 16. To address this, this paper proposes a three-stage training strategy with progressively increasing frame numbers and reducing fine-tuning modules. Additionally, we introduce the Temporal E nhanced Motion Module(TEMM) to extend the capacity for encoding temporal and positional information up to 36 frames. The proposed LoopAnimate, which for the first time extends the single-pass generation length of UNet-based video generation models to 35 frames while maintaining high-quality video generation. Experiments demonstrate that LoopAnimate achieves state-of-the-art performance in both objective metrics, such as fidelity and temporal consistency, and subjective evaluation results.
ADMap: Anti-disturbance framework for reconstructing online vectorized HD map
Jan 24, 2024



In the field of autonomous driving, online high-definition (HD) map reconstruction is crucial for planning tasks. Recent research has developed several high-performance HD map reconstruction models to meet this necessity. However, the point sequences within the instance vectors may be jittery or jagged due to prediction bias, which can impact subsequent tasks. Therefore, this paper proposes the Anti-disturbance Map reconstruction framework (ADMap). To mitigate point-order jitter, the framework consists of three modules: Multi-Scale Perception Neck, Instance Interactive Attention (IIA), and Vector Direction Difference Loss (VDDL). By exploring the point-order relationships between and within instances in a cascading manner, the model can monitor the point-order prediction process more effectively. ADMap achieves state-of-the-art performance on the nuScenes and Argoverse2 datasets. Extensive results demonstrate its ability to produce stable and reliable map elements in complex and changing driving scenarios. Code and more demos are available at https://github.com/hht1996ok/ADMap.
GAM : Gradient Attention Module of Optimization for Point Clouds Analysis
Mar 21, 2023In point cloud analysis tasks, the existing local feature aggregation descriptors (LFAD) are unable to fully utilize information in the neighborhood of central points. Previous methods rely solely on Euclidean distance to constrain the local aggregation process, which can be easily affected by abnormal points and cannot adequately fit with the original geometry of the point cloud. We believe that fine-grained geometric information (FGGI) is significant for the aggregation of local features. Therefore, we propose a gradient-based local attention module, termed as Gradient Attention Module (GAM), to address the aforementioned problem. Our proposed GAM simplifies the process that extracts gradient information in the neighborhood and uses the Zenith Angle matrix and Azimuth Angle matrix as explicit representation, which accelerates the module by 35X. Comprehensive experiments were conducted on five benchmark datasets to demonstrate the effectiveness and generalization capability of the proposed GAM for 3D point cloud analysis. Especially on S3DIS dataset, GAM achieves the best performance among current point-based models with mIoU/OA/mAcc of 74.4%/90.6%/83.2%, respectively.
* In AAAI, 2023
CM-MLP: Cascade Multi-scale MLP with Axial Context Relation Encoder for Edge Segmentation of Medical Image
Aug 23, 2022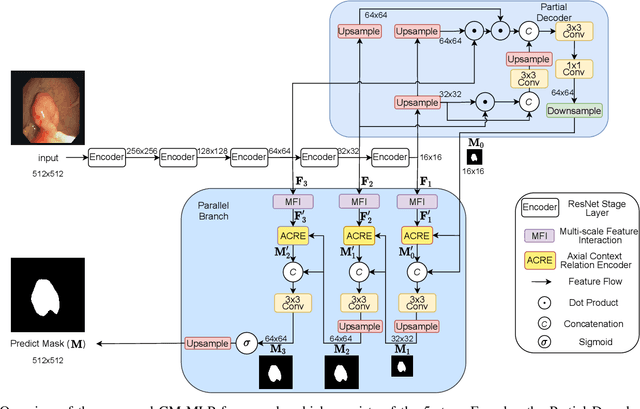
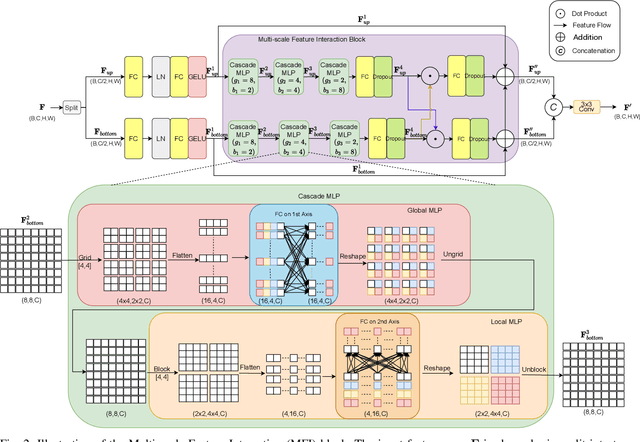
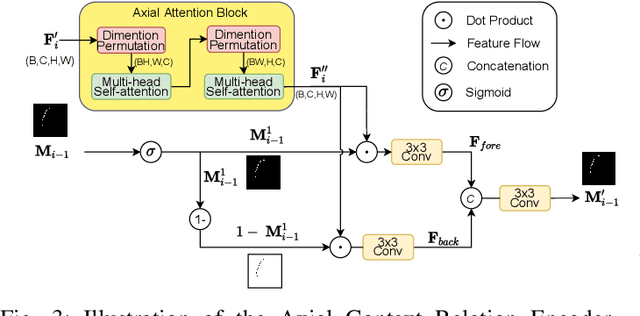
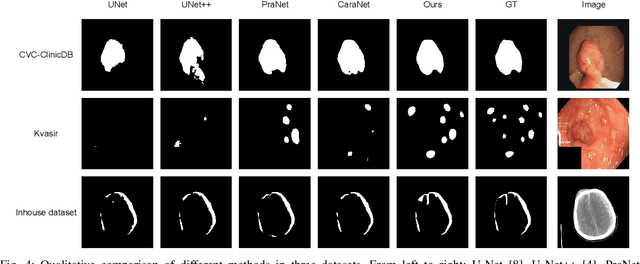
The convolutional-based methods provide good segmentation performance in the medical image segmentation task. However, those methods have the following challenges when dealing with the edges of the medical images: (1) Previous convolutional-based methods do not focus on the boundary relationship between foreground and background around the segmentation edge, which leads to the degradation of segmentation performance when the edge changes complexly. (2) The inductive bias of the convolutional layer cannot be adapted to complex edge changes and the aggregation of multiple-segmented areas, resulting in its performance improvement mostly limited to segmenting the body of segmented areas instead of the edge. To address these challenges, we propose the CM-MLP framework on MFI (Multi-scale Feature Interaction) block and ACRE (Axial Context Relation Encoder) block for accurate segmentation of the edge of medical image. In the MFI block, we propose the cascade multi-scale MLP (Cascade MLP) to process all local information from the deeper layers of the network simultaneously and utilize a cascade multi-scale mechanism to fuse discrete local information gradually. Then, the ACRE block is used to make the deep supervision focus on exploring the boundary relationship between foreground and background to modify the edge of the medical image. The segmentation accuracy (Dice) of our proposed CM-MLP framework reaches 96.96%, 96.76%, and 82.54% on three benchmark datasets: CVC-ClinicDB dataset, sub-Kvasir dataset, and our in-house dataset, respectively, which significantly outperform the state-of-the-art method. The source code and trained models will be available at https://github.com/ProgrammerHyy/CM-MLP.