 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastMap: Fast Queries Initialization Based Vectorized HD Map Reconstruction Framework
Mar 07, 2025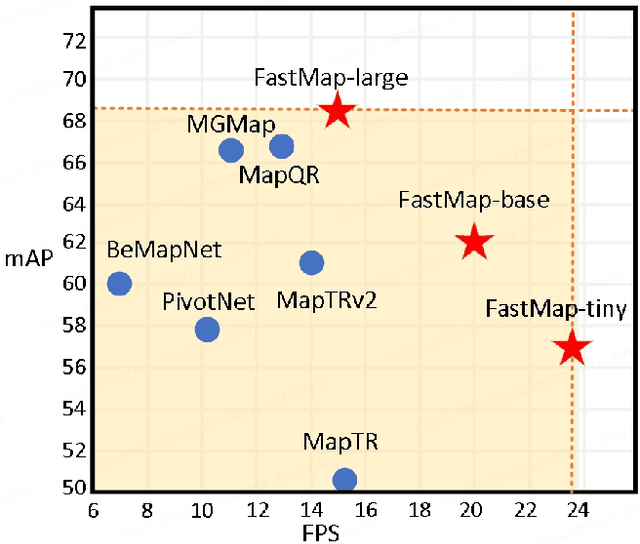
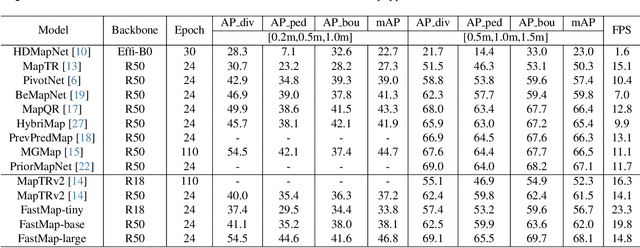
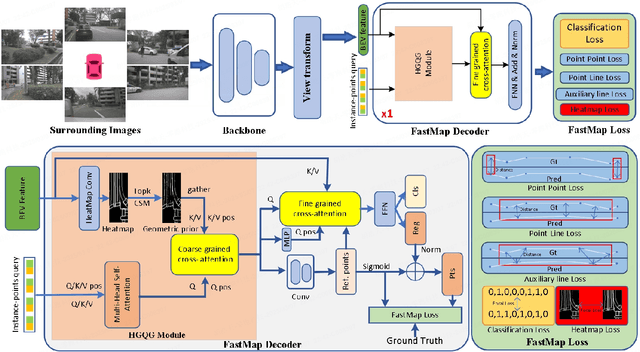
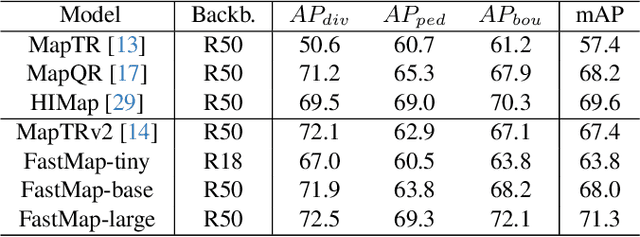
Reconstruction of high-definition maps is a crucial task in perceiving the autonomous driving environment, as its accuracy directly impacts the reliability of prediction and planning capabilities in downstream modules. Current vectorized map reconstruction methods based on the DETR framework encounter limitations due to the redundancy in the decoder structure, necessitating the stacking of six decoder layers to maintain performance, which significantly hampers computational efficiency. To tackle this issue, we introduce FastMap, an innovative framework designed to reduce decoder redundancy in existing approaches. FastMap optimizes the decoder architecture by employing a single-layer, two-stage transformer that achieves multilevel representation capabilities. Our framework eliminates the conventional practice of randomly initializing queries and instead incorporates a heatmap-guided query generation module during the decoding phase, which effectively maps image features into structured query vectors using learnable positional encoding. Additionally, we propose a geometry-constrained point-to-line loss mechanism for FastMap, which adeptly addresses the challenge of distinguishing highly homogeneous features that often arise in traditional point-to-point loss computations. Extensive experiments demonstrate that FastMap achieves state-of-the-art performance in both nuScenes and Argoverse2 datasets, with its decoder operating 3.2 faster than the baseline. Code and more demos are available at https://github.com/hht1996ok/FastMap.
MapNeXt: Revisiting Training and Scaling Practices for Online Vectorized HD Map Construction
Jan 14, 2024High-Definition (HD) maps are pivotal to autopilot navigation. Integrating the capability of lightweight HD map construction at runtime into a self-driving system recently emerges as a promising direction. In this surge, vision-only perception stands out, as a camera rig can still perceive the stereo information, let alone its appealing signature of portability and economy. The latest MapTR architecture solves the online HD map construction task in an end-to-end fashion but its potential is yet to be explored. In this work, we present a full-scale upgrade of MapTR and propose MapNeXt, the next generation of HD map learning architecture, delivering major contributions from the model training and scaling perspectives. After shedding light on the training dynamics of MapTR and exploiting the supervision from map elements thoroughly, MapNeXt-Tiny raises the mAP of MapTR-Tiny from 49.0% to 54.8%, without any architectural modifications. Enjoying the fruit of map segmentation pre-training, MapNeXt-Base further lifts the mAP up to 63.9% that has already outperformed the prior art, a multi-modality MapTR, by 1.4% while being $\sim1.8\times$ faster. Towards pushing the performance frontier to the next level, we draw two conclusions on practical model scaling: increased query favors a larger decoder network for adequate digestion; a large backbone steadily promotes the final accuracy without bells and whistles. Building upon these two rules of thumb, MapNeXt-Huge achieves state-of-the-art performance on the challenging nuScenes benchmark. Specifically, we push the mapless vision-only single-model performance to be over 78% for the first time, exceeding the best model from existing methods by 16%.