 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Matching for Text-to-Image Synthesis via Generative Adversarial Networks
Aug 20, 2022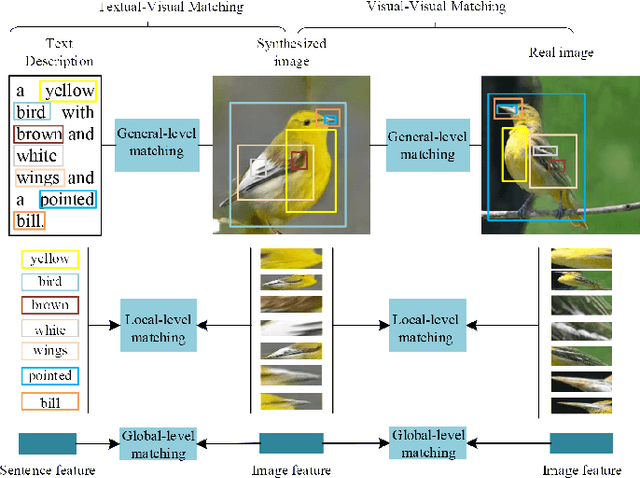
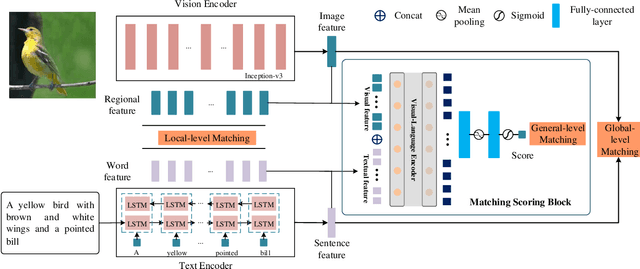
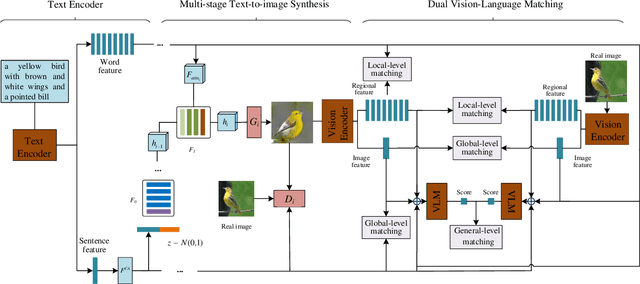

Text-to-image synthesis aims to generate a photo-realistic and semantic consistent image from a specific text description. The images synthesized by off-the-shelf models usually contain limited components compared with the corresponding image and text description, which decreases the image quality and the textual-visual consistency. To address this issue, we propose a novel Vision-Language Matching strategy for text-to-image synthesis, named VLMGAN*, which introduces a dual vision-language matching mechanism to strengthen the image quality and semantic consistency. The dual vision-language matching mechanism considers textual-visual matching between the generated image and the corresponding text description, and visual-visual consistent constraints between the synthesized image and the real image. Given a specific text description, VLMGAN* firstly encodes it into textual features and then feeds them to a dual vision-language matching-based generative model to synthesize a photo-realistic and textual semantic consistent image. Besides, the popular evaluation metrics for text-to-image synthesis are borrowed from simple image generation, which mainly evaluates the reality and diversity of the synthesized images. Therefore, we introduce a metric named Vision-Language Matching Score (VLMS) to evaluate the performance of text-to-image synthesis which can consider both the image quality and the semantic consistency between synthesized image and the description. The proposed dual multi-level vision-language matching strategy can be applied to other text-to-image synthesis methods. We implement this strategy on two popular baselines, which are marked with ${\text{VLMGAN}_{+\text{AttnGAN}}}$ and ${\text{VLMGAN}_{+\text{DFGAN}}}$. The experimental results on two widely-used datasets show that the model achieves significant improvements over other state-of-the-art methods.
A Unified Two-Stage Group Semantics Propagation and Contrastive Learning Network for Co-Saliency Detection
Aug 13, 2022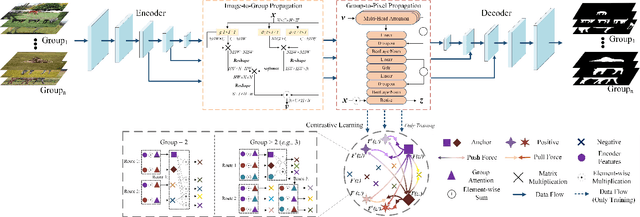
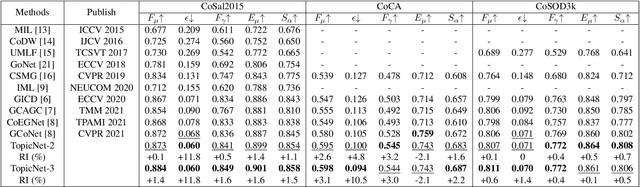


Co-saliency detection (CoSOD) aims at discovering the repetitive salient objects from multiple images. Two primary challenges are group semantics extraction and noise object suppression. In this paper, we present a unified Two-stage grOup semantics PropagatIon and Contrastive learning NETwork (TopicNet) for CoSOD. TopicNet can be decomposed into two substructures, including a two-stage group semantics propagation module (TGSP) to address the first challenge and a contrastive learning module (CLM) to address the second challenge. Concretely, for TGSP, we design an image-to-group propagation module (IGP) to capture the consensus representation of intra-group similar features and a group-to-pixel propagation module (GPP) to build the relevancy of consensus representation. For CLM, with the design of positive samples, the semantic consistency is enhanced. With the design of negative samples, the noise objects are suppressed. Experimental results on three prevailing benchmarks reveal that TopicNet outperforms other competitors in terms of various evaluation metrics.
Contrastive Cross-Modal Knowledge Sharing Pre-training for Vision-Language Representation Learning and Retrieval
Jul 08, 2022
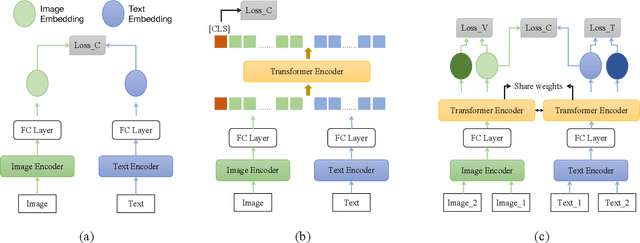


Recently, the cross-modal pre-training task has been a hotspot because of its wide application in various down-streaming researches including retrieval, captioning, question answering and so on. However, exiting methods adopt a one-stream pre-training model to explore the united vision-language representation for conducting cross-modal retrieval, which easily suffer from the calculation explosion. Moreover, although the conventional double-stream structures are quite efficient, they still lack the vital cross-modal interactions, resulting in low performances. Motivated by these challenges, we put forward a Contrastive Cross-Modal Knowledge Sharing Pre-training (COOKIE) to grasp the joint text-image representations. Structurally, COOKIE adopts the traditional double-stream structure because of the acceptable time consumption. To overcome the inherent defects of double-stream structure as mentioned above, we elaborately design two effective modules. Concretely, the first module is a weight-sharing transformer that builds on the head of the visual and textual encoders, aiming to semantically align text and image. This design enables visual and textual paths focus on the same semantics. The other one is three specially designed contrastive learning, aiming to share knowledge between different models. The shared cross-modal knowledge develops the study of unimodal representation greatly, promoting the single-modal retrieval tasks. Extensive experimental results on multi-modal matching researches that includes cross-modal retrieval, text matching, and image retrieval reveal the superiors in calculation efficiency and statistical indicators of our pre-training model.
Learning Dual Semantic Relations with Graph Attention for Image-Text Matching
Oct 22, 2020
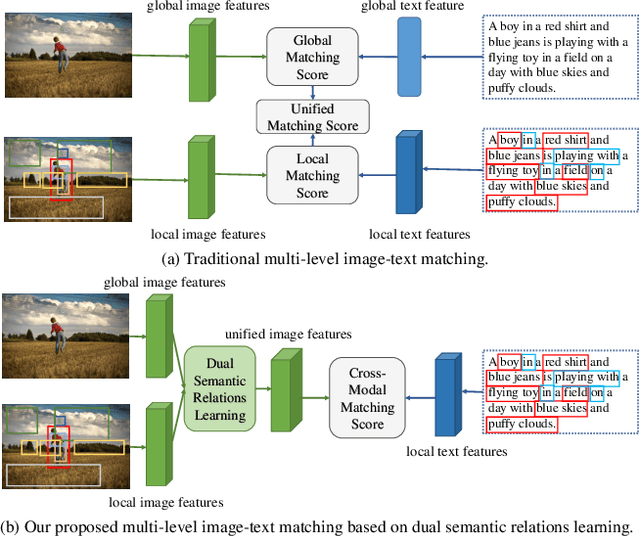
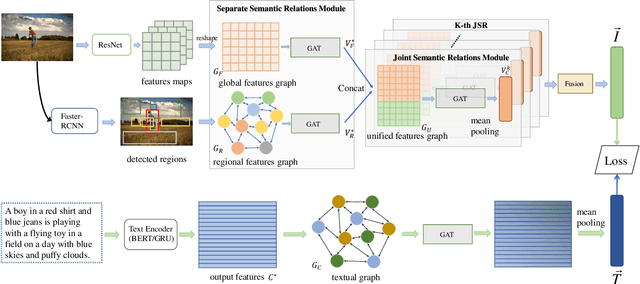
Image-Text Matching is one major task in cross-modal information processing. The main challenge is to learn the unified visual and textual representations. Previous methods that perform well on this task primarily focus on not only the alignment between region features in images and the corresponding words in sentences, but also the alignment between relations of regions and relational words. However, the lack of joint learning of regional features and global features will cause the regional features to lose contact with the global context, leading to the mismatch with those non-object words which have global meanings in some sentences. In this work, in order to alleviate this issue, it is necessary to enhance the relations between regions and the relations between regional and global concepts to obtain a more accurate visual representation so as to be better correlated to the corresponding text. Thus, a novel multi-level semantic relations enhancement approach named Dual Semantic Relations Attention Network(DSRAN) is proposed which mainly consists of two modules, separate semantic relations module and the joint semantic relations module. DSRAN performs graph attention in both modules respectively for region-level relations enhancement and regional-global relations enhancement at the same time. With these two modules, different hierarchies of semantic relations are learned simultaneously, thus promoting the image-text matching process by providing more information for the final visual representation. Quantitative experimental results have been performed on MS-COCO and Flickr30K and our method outperforms previous approaches by a large margin due to the effectiveness of the dual semantic relations learning scheme. Codes are available at https://github.com/kywen1119/DSRAN.