 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Matching for Text-to-Image Synthesis via Generative Adversarial Networks
Paper and Code
Aug 20, 2022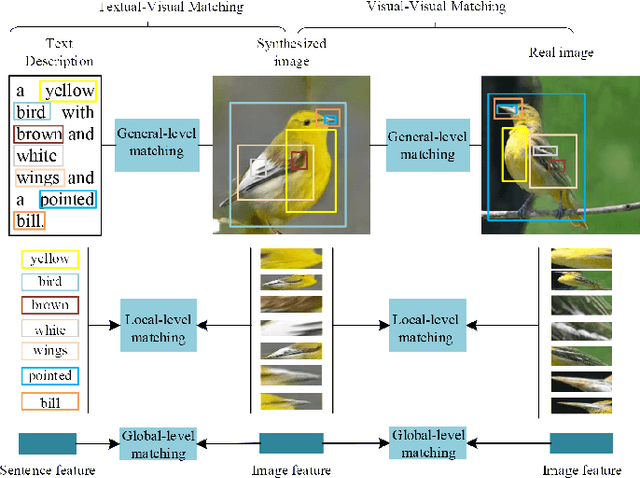
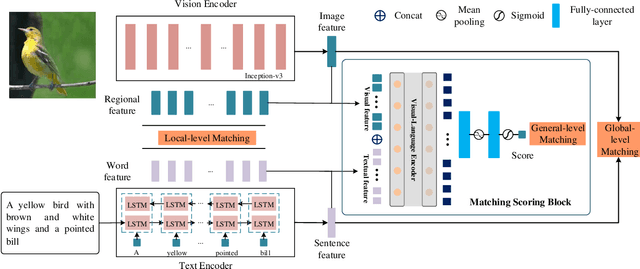
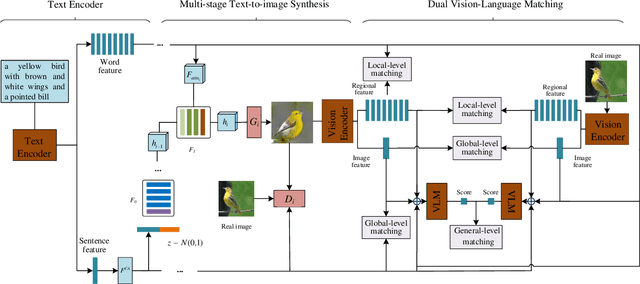

Text-to-image synthesis aims to generate a photo-realistic and semantic consistent image from a specific text description. The images synthesized by off-the-shelf models usually contain limited components compared with the corresponding image and text description, which decreases the image quality and the textual-visual consistency. To address this issue, we propose a novel Vision-Language Matching strategy for text-to-image synthesis, named VLMGAN*, which introduces a dual vision-language matching mechanism to strengthen the image quality and semantic consistency. The dual vision-language matching mechanism considers textual-visual matching between the generated image and the corresponding text description, and visual-visual consistent constraints between the synthesized image and the real image. Given a specific text description, VLMGAN* firstly encodes it into textual features and then feeds them to a dual vision-language matching-based generative model to synthesize a photo-realistic and textual semantic consistent image. Besides, the popular evaluation metrics for text-to-image synthesis are borrowed from simple image generation, which mainly evaluates the reality and diversity of the synthesized images. Therefore, we introduce a metric named Vision-Language Matching Score (VLMS) to evaluate the performance of text-to-image synthesis which can consider both the image quality and the semantic consistency between synthesized image and the description. The proposed dual multi-level vision-language matching strategy can be applied to other text-to-image synthesis methods. We implement this strategy on two popular baselines, which are marked with ${\text{VLMGAN}_{+\text{AttnGAN}}}$ and ${\text{VLMGAN}_{+\text{DFGAN}}}$. The experimental results on two widely-used datasets show that the model achieves significant improvements over other state-of-the-art methods.