 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Cross-Modal Knowledge Sharing Pre-training for Vision-Language Representation Learning and Retrieval
Paper and Code
Jul 08, 2022
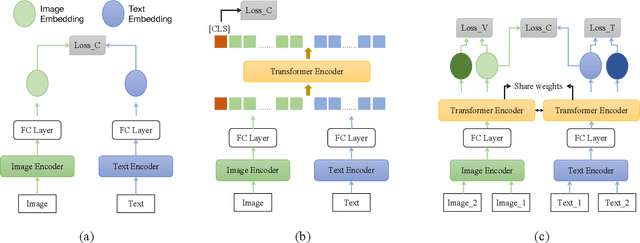


Recently, the cross-modal pre-training task has been a hotspot because of its wide application in various down-streaming researches including retrieval, captioning, question answering and so on. However, exiting methods adopt a one-stream pre-training model to explore the united vision-language representation for conducting cross-modal retrieval, which easily suffer from the calculation explosion. Moreover, although the conventional double-stream structures are quite efficient, they still lack the vital cross-modal interactions, resulting in low performances. Motivated by these challenges, we put forward a Contrastive Cross-Modal Knowledge Sharing Pre-training (COOKIE) to grasp the joint text-image representations. Structurally, COOKIE adopts the traditional double-stream structure because of the acceptable time consumption. To overcome the inherent defects of double-stream structure as mentioned above, we elaborately design two effective modules. Concretely, the first module is a weight-sharing transformer that builds on the head of the visual and textual encoders, aiming to semantically align text and image. This design enables visual and textual paths focus on the same semantics. The other one is three specially designed contrastive learning, aiming to share knowledge between different models. The shared cross-modal knowledge develops the study of unimodal representation greatly, promoting the single-modal retrieval tasks. Extensive experimental results on multi-modal matching researches that includes cross-modal retrieval, text matching, and image retrieval reveal the superiors in calculation efficiency and statistical indicators of our pre-training model.