 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifficulty-guided Sampling: Bridging the Target Gap between Dataset Distillation and Downstream Tasks
Jan 15, 2026In this paper, we propose difficulty-guided sampling (DGS) to bridge the target gap between the distillation objective and the downstream task, therefore improving the performance of dataset distillation. Deep neural networks achieve remarkable performance but have time and storage-consuming training processes. Dataset distillation is proposed to generate compact, high-quality distilled datasets, enabling effective model training while maintaining downstream performance. Existing approaches typically focus on features extracted from the original dataset, overlooking task-specific information, which leads to a target gap between the distillation objective and the downstream task. We propose leveraging characteristics that benefit the downstream training into data distillation to bridge this gap. Focusing on the downstream task of image classification, we introduce the concept of difficulty and propose DGS as a plug-in post-stage sampling module. Following the specific target difficulty distribution, the final distilled dataset is sampled from image pools generated by existing methods. We also propose difficulty-aware guidance (DAG) to explore the effect of difficulty in the generation process. Extensive experiments across multiple settings demonstrate the effectiveness of the proposed methods. It also highlights the broader potential of difficulty for diverse downstream tasks.
Region-Wise Correspondence Prediction between Manga Line Art Images
Sep 11, 2025



Understanding region-wise correspondence between manga line art images is a fundamental task in manga processing, enabling downstream applications such as automatic line art colorization and in-between frame generation. However, this task remains largely unexplored, especially in realistic scenarios without pre-existing segmentation or annotations. In this paper, we introduce a novel and practical task: predicting region-wise correspondence between raw manga line art images without any pre-existing labels or masks. To tackle this problem, we divide each line art image into a set of patches and propose a Transformer-based framework that learns patch-level similarities within and across images. We then apply edge-aware clustering and a region matching algorithm to convert patch-level predictions into coherent region-level correspondences. To support training and evaluation, we develop an automatic annotation pipeline and manually refine a subset of the data to construct benchmark datasets. Experiments on multiple datasets demonstrate that our method achieves high patch-level accuracy (e.g., 96.34%) and generates consistent region-level correspondences, highlighting its potential for real-world manga applications.
Noisy Label Refinement with Semantically Reliable Synthetic Images
Sep 04, 2025Semantic noise in image classification datasets, where visually similar categories are frequently mislabeled, poses a significant challenge to conventional supervised learning approaches. In this paper, we explore the potential of using synthetic images generated by advanced text-to-image models to address this issue. Although these high-quality synthetic images come with reliable labels, their direct application in training is limited by domain gaps and diversity constraints. Unlike conventional approaches, we propose a novel method that leverages synthetic images as reliable reference points to identify and correct mislabeled samples in noisy datasets. Extensive experiments across multiple benchmark datasets show that our approach significantly improves classification accuracy under various noise conditions, especially in challenging scenarios with semantic label noise. Additionally, since our method is orthogonal to existing noise-robust learning techniques, when combined with state-of-the-art noise-robust training methods, it achieves superior performance, improving accuracy by 30% on CIFAR-10 and by 11% on CIFAR-100 under 70% semantic noise, and by 24% on ImageNet-100 under real-world noise conditions.
Exploring Palette based Color Guidance in Diffusion Models
Aug 12, 2025With the advent of diffusion models, Text-to-Image (T2I) generation has seen substantial advancements. Current T2I models allow users to specify object colors using linguistic color names, and some methods aim to personalize color-object association through prompt learning. However, existing models struggle to provide comprehensive control over the color schemes of an entire image, especially for background elements and less prominent objects not explicitly mentioned in prompts. This paper proposes a novel approach to enhance color scheme control by integrating color palettes as a separate guidance mechanism alongside prompt instructions. We investigate the effectiveness of palette guidance by exploring various palette representation methods within a diffusion-based image colorization framework. To facilitate this exploration, we construct specialized palette-text-image datasets and conduct extensive quantitative and qualitative analyses. Our results demonstrate that incorporating palette guidance significantly improves the model's ability to generate images with desired color schemes, enabling a more controlled and refined colorization process.
Diversity-Driven Generative Dataset Distillation Based on Diffusion Model with Self-Adaptive Memory
May 26, 2025Dataset distillation enables the training of deep neural networks with comparable performance in significantly reduced time by compressing large datasets into small and representative ones. Although the introduction of generative models has made great achievements in this field, the distributions of their distilled datasets are not diverse enough to represent the original ones, leading to a decrease in downstream validation accuracy. In this paper, we present a diversity-driven generative dataset distillation method based on a diffusion model to solve this problem. We introduce self-adaptive memory to align the distribution between distilled and real datasets, assessing the representativeness. The degree of alignment leads the diffusion model to generate more diverse datasets during the distillation process. Extensive experiments show that our method outperforms existing state-of-the-art methods in most situations, proving its ability to tackle dataset distillation tasks.
Training Data Synthesis with Difficulty Controlled Diffusion Model
Nov 27, 2024



Semi-supervised learning (SSL) can improve model performance by leveraging unlabeled images, which can be collected from public image sources with low costs. In recent years, synthetic images have become increasingly common in public image sources due to rapid advances in generative models. Therefore, it is becoming inevitable to include existing synthetic images in the unlabeled data for SSL. How this kind of contamination will affect SSL remains unexplored. In this paper, we introduce a new task, Real-Synthetic Hybrid SSL (RS-SSL), to investigate the impact of unlabeled data contaminated by synthetic images for SSL. First, we set up a new RS-SSL benchmark to evaluate current SSL methods and found they struggled to improve by unlabeled synthetic images, sometimes even negatively affected. To this end, we propose RSMatch, a novel SSL method specifically designed to handle the challenges of RS-SSL. RSMatch effectively identifies unlabeled synthetic data and further utilizes them for improvement. Extensive experimental results show that RSMatch can transfer synthetic unlabeled data from `obstacles' to `resources.' The effectiveness is further verified through ablation studies and visualization.
Reward Incremental Learning in Text-to-Image Generation
Nov 26, 2024The recent success of denoising diffusion models has significantly advanced text-to-image generation. While these large-scale pretrained models show excellent performance in general image synthesis, downstream objectives often require fine-tuning to meet specific criteria such as aesthetics or human preference. Reward gradient-based strategies are promising in this context, yet existing methods are limited to single-reward tasks, restricting their applicability in real-world scenarios that demand adapting to multiple objectives introduced incrementally over time. In this paper, we first define this more realistic and unexplored problem, termed Reward Incremental Learning (RIL), where models are desired to adapt to multiple downstream objectives incrementally. Additionally, while the models adapt to the ever-emerging new objectives, we observe a unique form of catastrophic forgetting in diffusion model fine-tuning, affecting both metric-wise and visual structure-wise image quality. To address this catastrophic forgetting challenge, we propose Reward Incremental Distillation (RID), a method that mitigates forgetting with minimal computational overhead, enabling stable performance across sequential reward tasks. The experimental results demonstrate the efficacy of RID in achieving consistent, high-quality generation in RIL scenarios. The source code of our work will be publicly available upon acceptance.
Dealing with Synthetic Data Contamination in Online Continual Learning
Nov 21, 2024

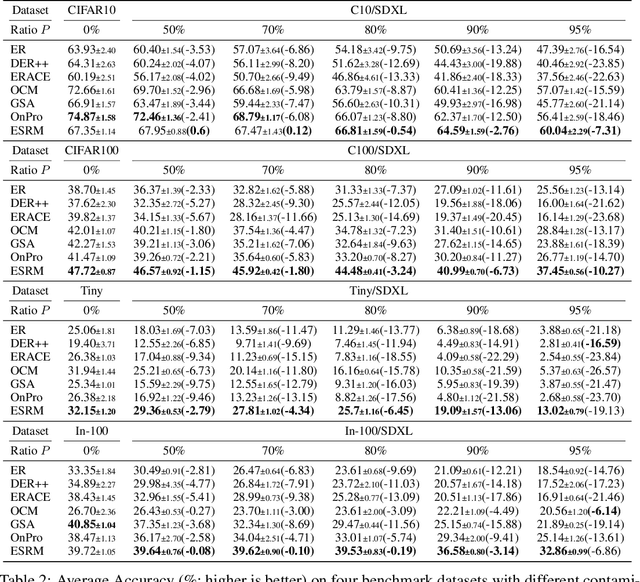

Image generation has shown remarkable results in generating high-fidelity realistic images, in particular with the advancement of diffusion-based models. However, the prevalence of AI-generated images may have side effects for the machine learning community that are not clearly identified. Meanwhile, the success of deep learning in computer vision is driven by the massive dataset collected on the Internet. The extensive quantity of synthetic data being added to the Internet would become an obstacle for future researchers to collect "clean" datasets without AI-generated content. Prior research has shown that using datasets contaminated by synthetic images may result in performance degradation when used for training. In this paper, we investigate the potential impact of contaminated datasets on Online Continual Learning (CL) research. We experimentally show that contaminated datasets might hinder the training of existing online CL methods. Also, we propose Entropy Selection with Real-synthetic similarity Maximization (ESRM), a method to alleviate the performance deterioration caused by synthetic images when training online CL models. Experiments show that our method can significantly alleviate performance deterioration, especially when the contamination is severe. For reproducibility, the source code of our work is available at https://github.com/maorong-wang/ESRM.
SCOMatch: Alleviating Overtrusting in Open-set Semi-supervised Learning
Sep 26, 2024



Open-set semi-supervised learning (OSSL) leverages practical open-set unlabeled data, comprising both in-distribution (ID) samples from seen classes and out-of-distribution (OOD) samples from unseen classes, for semi-supervised learning (SSL). Prior OSSL methods initially learned the decision boundary between ID and OOD with labeled ID data, subsequently employing self-training to refine this boundary. These methods, however, suffer from the tendency to overtrust the labeled ID data: the scarcity of labeled data caused the distribution bias between the labeled samples and the entire ID data, which misleads the decision boundary to overfit. The subsequent self-training process, based on the overfitted result, fails to rectify this problem. In this paper, we address the overtrusting issue by treating OOD samples as an additional class, forming a new SSL process. Specifically, we propose SCOMatch, a novel OSSL method that 1) selects reliable OOD samples as new labeled data with an OOD memory queue and a corresponding update strategy and 2) integrates the new SSL process into the original task through our Simultaneous Close-set and Open-set self-training. SCOMatch refines the decision boundary of ID and OOD classes across the entire dataset, thereby leading to improved results. Extensive experimental results show that SCOMatch significantly outperforms the state-of-the-art methods on various benchmarks. The effectiveness is further verified through ablation studies and visualization.
Training-Free Sketch-Guided Diffusion with Latent Optimization
Aug 31, 2024



Based on recent advanced diffusion models, Text-to-image (T2I) generation models have demonstrated their capabilities in generating diverse and high-quality images. However, leveraging their potential for real-world content creation, particularly in providing users with precise control over the image generation result, poses a significant challenge. In this paper, we propose an innovative training-free pipeline that extends existing text-to-image generation models to incorporate a sketch as an additional condition. To generate new images with a layout and structure closely resembling the input sketch, we find that these core features of a sketch can be tracked with the cross-attention maps of diffusion models. We introduce latent optimization, a method that refines the noisy latent at each intermediate step of the generation process using cross-attention maps to ensure that the generated images closely adhere to the desired structure outlined in the reference sketch. Through latent optimization, our method enhances the fidelity and accuracy of image generation, offering users greater control and customization options in content creation.