 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoGuard: An Extensible Agentic RL-based Framework for Practical and Evolving AI-Generated Image Detection
Mar 18, 2026The rapid proliferation of AI-Generated Images (AIGIs) has introduced severe risks of misinformation, making AIGI detection a critical yet challenging task. While traditional detection paradigms mainly rely on low-level features, recent research increasingly focuses on leveraging the general understanding ability of Multimodal Large Language Models (MLLMs) to achieve better generalization, but still suffer from limited extensibility and expensive training data annotations. To better address complex and dynamic real-world environments, we propose EvoGuard, a novel agentic framework for AIGI detection. It encapsulates various state-of-the-art (SOTA) off-the-shelf MLLM and non-MLLM detectors as callable tools, and coordinates them through a capability-aware dynamic orchestration mechanism. Empowered by the agent's capacities for autonomous planning and reflection, it intelligently selects suitable tools for given samples, reflects intermediate results, and decides the next action, reaching a final conclusion through multi-turn invocation and reasoning. This design effectively exploits the complementary strengths among heterogeneous detectors, transcending the limits of any single model. Furthermore, optimized by a GRPO-based Agentic Reinforcement Learning algorithm using only low-cost binary labels, it eliminates the reliance on fine-grained annotations. Extensive experiments demonstrate that EvoGuard achieves SOTA accuracy while mitigating the bias between positive and negative samples. More importantly, it allows the plug-and-play integration of new detectors to boost overall performance in a train-free manner, offering a highly practical, long-term solution to ever-evolving AIGI threats. Source code will be publicly available upon acceptance.
Online Prototypes and Class-Wise Hypergradients for Online Continual Learning with Pre-Trained Models
Feb 26, 2025Continual Learning (CL) addresses the problem of learning from a data sequence where the distribution changes over time. Recently, efficient solutions leveraging Pre-Trained Models (PTM) have been widely explored in the offline CL (offCL) scenario, where the data corresponding to each incremental task is known beforehand and can be seen multiple times. However, such solutions often rely on 1) prior knowledge regarding task changes and 2) hyper-parameter search, particularly regarding the learning rate. Both assumptions remain unavailable in online CL (onCL) scenarios, where incoming data distribution is unknown and the model can observe each datum only once. Therefore, existing offCL strategies fall largely behind performance-wise in onCL, with some proving difficult or impossible to adapt to the online scenario. In this paper, we tackle both problems by leveraging Online Prototypes (OP) and Class-Wise Hypergradients (CWH). OP leverages stable output representations of PTM by updating its value on the fly to act as replay samples without requiring task boundaries or storing past data. CWH learns class-dependent gradient coefficients during training to improve over sub-optimal learning rates. We show through experiments that both introduced strategies allow for a consistent gain in accuracy when integrated with existing approaches. We will make the code fully available upon acceptance.
Reward Incremental Learning in Text-to-Image Generation
Nov 26, 2024The recent success of denoising diffusion models has significantly advanced text-to-image generation. While these large-scale pretrained models show excellent performance in general image synthesis, downstream objectives often require fine-tuning to meet specific criteria such as aesthetics or human preference. Reward gradient-based strategies are promising in this context, yet existing methods are limited to single-reward tasks, restricting their applicability in real-world scenarios that demand adapting to multiple objectives introduced incrementally over time. In this paper, we first define this more realistic and unexplored problem, termed Reward Incremental Learning (RIL), where models are desired to adapt to multiple downstream objectives incrementally. Additionally, while the models adapt to the ever-emerging new objectives, we observe a unique form of catastrophic forgetting in diffusion model fine-tuning, affecting both metric-wise and visual structure-wise image quality. To address this catastrophic forgetting challenge, we propose Reward Incremental Distillation (RID), a method that mitigates forgetting with minimal computational overhead, enabling stable performance across sequential reward tasks. The experimental results demonstrate the efficacy of RID in achieving consistent, high-quality generation in RIL scenarios. The source code of our work will be publicly available upon acceptance.
Dealing with Synthetic Data Contamination in Online Continual Learning
Nov 21, 2024

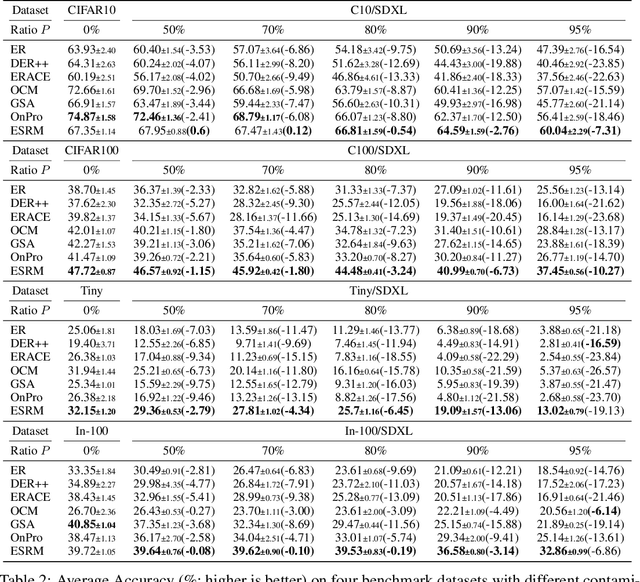

Image generation has shown remarkable results in generating high-fidelity realistic images, in particular with the advancement of diffusion-based models. However, the prevalence of AI-generated images may have side effects for the machine learning community that are not clearly identified. Meanwhile, the success of deep learning in computer vision is driven by the massive dataset collected on the Internet. The extensive quantity of synthetic data being added to the Internet would become an obstacle for future researchers to collect "clean" datasets without AI-generated content. Prior research has shown that using datasets contaminated by synthetic images may result in performance degradation when used for training. In this paper, we investigate the potential impact of contaminated datasets on Online Continual Learning (CL) research. We experimentally show that contaminated datasets might hinder the training of existing online CL methods. Also, we propose Entropy Selection with Real-synthetic similarity Maximization (ESRM), a method to alleviate the performance deterioration caused by synthetic images when training online CL models. Experiments show that our method can significantly alleviate performance deterioration, especially when the contamination is severe. For reproducibility, the source code of our work is available at https://github.com/maorong-wang/ESRM.
Improving Plasticity in Online Continual Learning via Collaborative Learning
Dec 01, 2023Online Continual Learning (CL) solves the problem of learning the ever-emerging new classification tasks from a continuous data stream. Unlike its offline counterpart, in online CL, the training data can only be seen once. Most existing online CL research regards catastrophic forgetting (i.e., model stability) as almost the only challenge. In this paper, we argue that the model's capability to acquire new knowledge (i.e., model plasticity) is another challenge in online CL. While replay-based strategies have been shown to be effective in alleviating catastrophic forgetting, there is a notable gap in research attention toward improving model plasticity. To this end, we propose Collaborative Continual Learning (CCL), a collaborative learning based strategy to improve the model's capability in acquiring new concepts. Additionally, we introduce Distillation Chain (DC), a novel collaborative learning scheme to boost the training of the models. We adapted CCL-DC to existing representative online CL works. Extensive experiments demonstrate that even if the learners are well-trained with state-of-the-art online CL methods, our strategy can still improve model plasticity dramatically, and thereby improve the overall performance by a large margin.
Rethinking Momentum Knowledge Distillation in Online Continual Learning
Sep 06, 2023Online Continual Learning (OCL) addresses the problem of training neural networks on a continuous data stream where multiple classification tasks emerge in sequence. In contrast to offline Continual Learning, data can be seen only once in OCL. In this context, replay-based strategies have achieved impressive results and most state-of-the-art approaches are heavily depending on them. While Knowledge Distillation (KD) has been extensively used in offline Continual Learning, it remains under-exploited in OCL, despite its potential. In this paper, we theoretically analyze the challenges in applying KD to OCL. We introduce a direct yet effective methodology for applying Momentum Knowledge Distillation (MKD) to many flagship OCL methods and demonstrate its capabilities to enhance existing approaches. In addition to improving existing state-of-the-arts accuracy by more than $10\%$ points on ImageNet100, we shed light on MKD internal mechanics and impacts during training in OCL. We argue that similar to replay, MKD should be considered a central component of OCL.
MetaMixer: A Regularization Strategy for Online Knowledge Distillation
Mar 14, 2023



Online knowledge distillation (KD) has received increasing attention in recent years. However, while most existing online KD methods focus on developing complicated model structures and training strategies to improve the distillation of high-level knowledge like probability distribution, the effects of the multi-level knowledge in the online KD are greatly overlooked, especially the low-level knowledge. Thus, to provide a novel viewpoint to online KD, we propose MetaMixer, a regularization strategy that can strengthen the distillation by combining the low-level knowledge that impacts the localization capability of the networks, and high-level knowledge that focuses on the whole image. Experiments under different conditions show that MetaMixer can achieve significant performance gains over state-of-the-art methods.