 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Prototypes and Class-Wise Hypergradients for Online Continual Learning with Pre-Trained Models
Feb 26, 2025Continual Learning (CL) addresses the problem of learning from a data sequence where the distribution changes over time. Recently, efficient solutions leveraging Pre-Trained Models (PTM) have been widely explored in the offline CL (offCL) scenario, where the data corresponding to each incremental task is known beforehand and can be seen multiple times. However, such solutions often rely on 1) prior knowledge regarding task changes and 2) hyper-parameter search, particularly regarding the learning rate. Both assumptions remain unavailable in online CL (onCL) scenarios, where incoming data distribution is unknown and the model can observe each datum only once. Therefore, existing offCL strategies fall largely behind performance-wise in onCL, with some proving difficult or impossible to adapt to the online scenario. In this paper, we tackle both problems by leveraging Online Prototypes (OP) and Class-Wise Hypergradients (CWH). OP leverages stable output representations of PTM by updating its value on the fly to act as replay samples without requiring task boundaries or storing past data. CWH learns class-dependent gradient coefficients during training to improve over sub-optimal learning rates. We show through experiments that both introduced strategies allow for a consistent gain in accuracy when integrated with existing approaches. We will make the code fully available upon acceptance.
Enhancing Multirotor Drone Efficiency: Exploring Minimum Energy Consumption Rate of Forward Flight under Varying Payload
Jan 06, 2025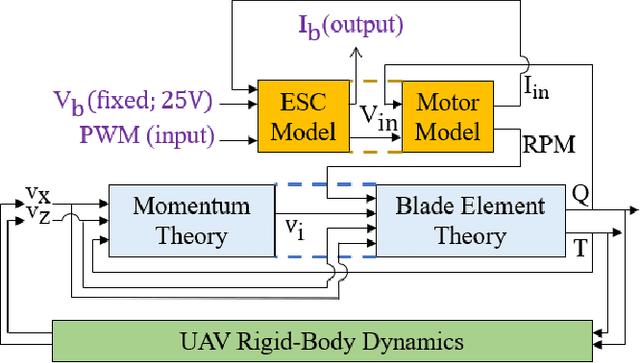
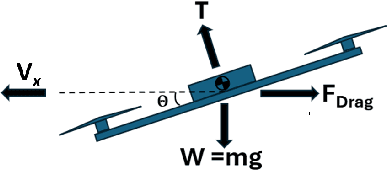
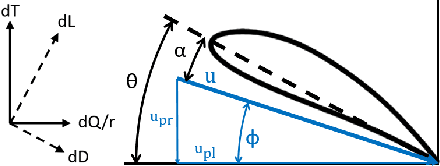
Multirotor unmanned aerial vehicle is a prevailing type of aircraft with wide real-world applications. Energy efficiency is a critical aspect of its performance, determining the range and duration of the missions that can be performed. In this study, we show both analytically and numerically that the optimum of a key energy efficiency index in forward flight, namely energy per meter traveled per unit mass, is a constant under different vehicle mass (including payload). Note that this relationship is only true under the optimal forward velocity that minimizes the energy consumption (under different mass), but not under arbitrary velocity. The study is based on a previously developed model capturing the first-principle energy dynamics of the multirotor, and a key step is to prove that the pitch angle under optimal velocity is a constant. By employing both analytical derivation and validation studies, the research provides critical insights into the optimization of multirotor energy efficiency, and facilitate the development of flight control strategies to extend mission duration and range.
* https://arc.aiaa.org/doi/10.2514/6.2025-2187
Dealing with Synthetic Data Contamination in Online Continual Learning
Nov 21, 2024

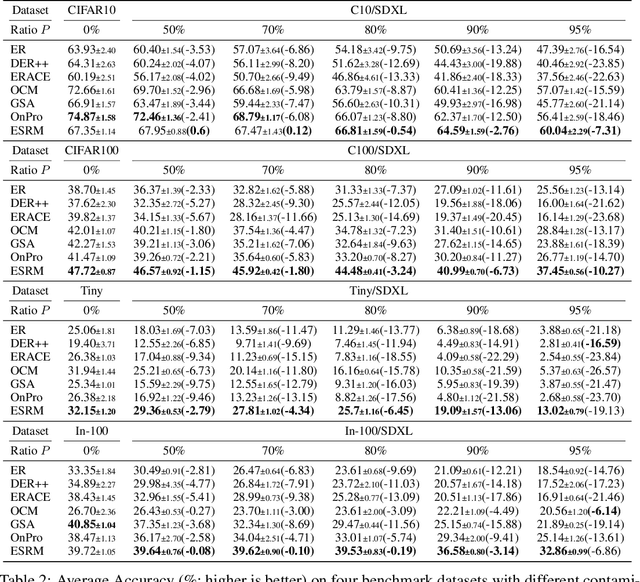

Image generation has shown remarkable results in generating high-fidelity realistic images, in particular with the advancement of diffusion-based models. However, the prevalence of AI-generated images may have side effects for the machine learning community that are not clearly identified. Meanwhile, the success of deep learning in computer vision is driven by the massive dataset collected on the Internet. The extensive quantity of synthetic data being added to the Internet would become an obstacle for future researchers to collect "clean" datasets without AI-generated content. Prior research has shown that using datasets contaminated by synthetic images may result in performance degradation when used for training. In this paper, we investigate the potential impact of contaminated datasets on Online Continual Learning (CL) research. We experimentally show that contaminated datasets might hinder the training of existing online CL methods. Also, we propose Entropy Selection with Real-synthetic similarity Maximization (ESRM), a method to alleviate the performance deterioration caused by synthetic images when training online CL models. Experiments show that our method can significantly alleviate performance deterioration, especially when the contamination is severe. For reproducibility, the source code of our work is available at https://github.com/maorong-wang/ESRM.
Energy-Optimal Planning of Waypoint-Based UAV Missions -- Does Minimum Distance Mean Minimum Energy?
Oct 23, 2024Multirotor unmanned aerial vehicle is a prevailing type of aerial robots with wide real-world applications. The energy efficiency of the robot is a critical aspect of its performance, determining the range and duration of the missions that can be performed. This paper studies the energy-optimal planning of the multirotor, which aims at finding the optimal ordering of waypoints with the minimum energy consumption for missions in 3D space. The study is performed based on a previously developed model capturing first-principle energy dynamics of the multirotor. We found that in majority of the cases (up to 95%) the solutions of the energy-optimal planning are different from those of the traditional traveling salesman problem which minimizes the total distance. The difference can be as high as 14.9%, with the average at 1.6%-3.3% and 90th percentile at 3.7%-6.5% depending on the range and number of waypoints in the mission. We then identified and explained the key features of the minimum-energy order by correlating to the underlying flight energy dynamics. It is shown that instead of minimizing the distance, coordination of vertical and horizontal motion to promote aerodynamic efficiency is the key to optimizing energy consumption.
Improving Plasticity in Online Continual Learning via Collaborative Learning
Dec 01, 2023Online Continual Learning (CL) solves the problem of learning the ever-emerging new classification tasks from a continuous data stream. Unlike its offline counterpart, in online CL, the training data can only be seen once. Most existing online CL research regards catastrophic forgetting (i.e., model stability) as almost the only challenge. In this paper, we argue that the model's capability to acquire new knowledge (i.e., model plasticity) is another challenge in online CL. While replay-based strategies have been shown to be effective in alleviating catastrophic forgetting, there is a notable gap in research attention toward improving model plasticity. To this end, we propose Collaborative Continual Learning (CCL), a collaborative learning based strategy to improve the model's capability in acquiring new concepts. Additionally, we introduce Distillation Chain (DC), a novel collaborative learning scheme to boost the training of the models. We adapted CCL-DC to existing representative online CL works. Extensive experiments demonstrate that even if the learners are well-trained with state-of-the-art online CL methods, our strategy can still improve model plasticity dramatically, and thereby improve the overall performance by a large margin.
Domain-Aware Augmentations for Unsupervised Online General Continual Learning
Sep 13, 2023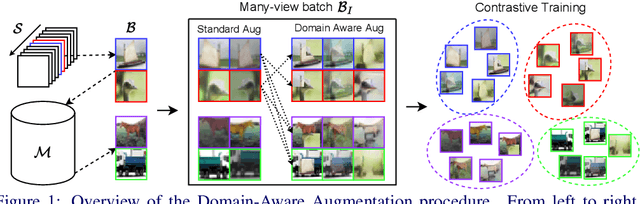
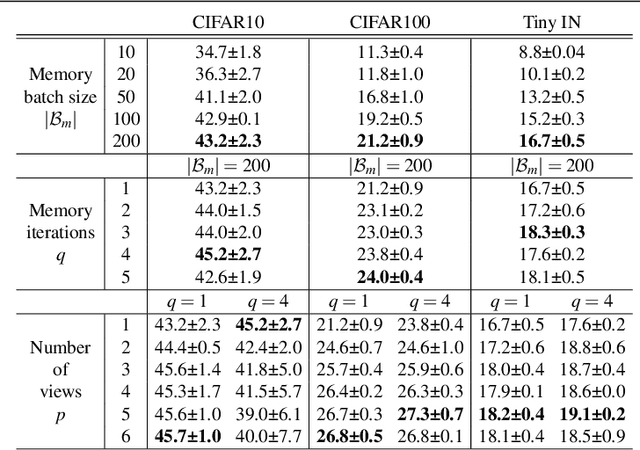
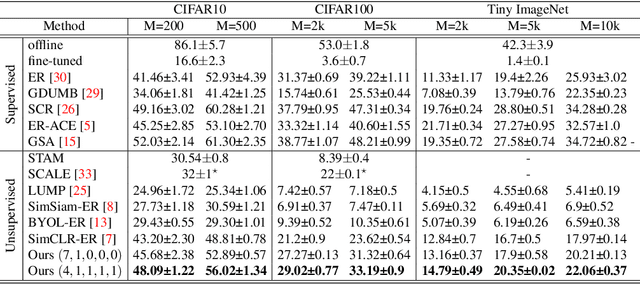
Continual Learning has been challenging, especially when dealing with unsupervised scenarios such as Unsupervised Online General Continual Learning (UOGCL), where the learning agent has no prior knowledge of class boundaries or task change information. While previous research has focused on reducing forgetting in supervised setups, recent studies have shown that self-supervised learners are more resilient to forgetting. This paper proposes a novel approach that enhances memory usage for contrastive learning in UOGCL by defining and using stream-dependent data augmentations together with some implementation tricks. Our proposed method is simple yet effective, achieves state-of-the-art results compared to other unsupervised approaches in all considered setups, and reduces the gap between supervised and unsupervised continual learning. Our domain-aware augmentation procedure can be adapted to other replay-based methods, making it a promising strategy for continual learning.
Rethinking Momentum Knowledge Distillation in Online Continual Learning
Sep 06, 2023Online Continual Learning (OCL) addresses the problem of training neural networks on a continuous data stream where multiple classification tasks emerge in sequence. In contrast to offline Continual Learning, data can be seen only once in OCL. In this context, replay-based strategies have achieved impressive results and most state-of-the-art approaches are heavily depending on them. While Knowledge Distillation (KD) has been extensively used in offline Continual Learning, it remains under-exploited in OCL, despite its potential. In this paper, we theoretically analyze the challenges in applying KD to OCL. We introduce a direct yet effective methodology for applying Momentum Knowledge Distillation (MKD) to many flagship OCL methods and demonstrate its capabilities to enhance existing approaches. In addition to improving existing state-of-the-arts accuracy by more than $10\%$ points on ImageNet100, we shed light on MKD internal mechanics and impacts during training in OCL. We argue that similar to replay, MKD should be considered a central component of OCL.
New metrics for analyzing continual learners
Sep 01, 2023
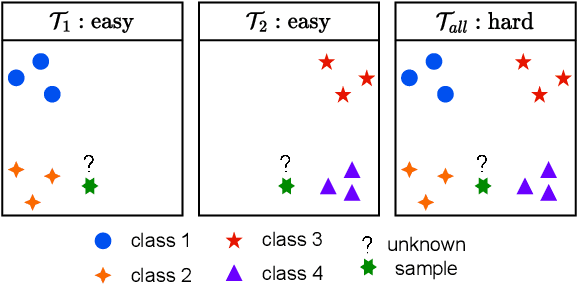
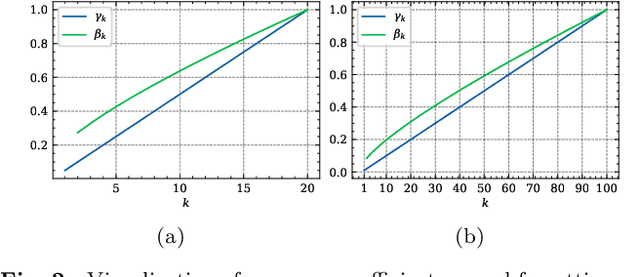
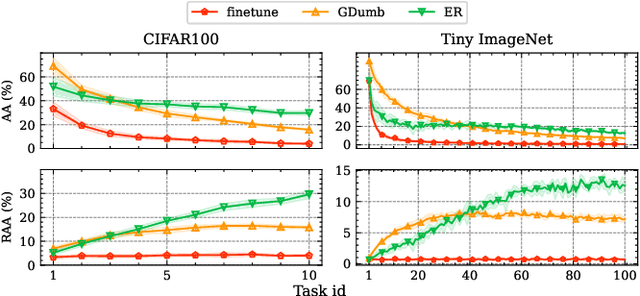
Deep neural networks have shown remarkable performance when trained on independent and identically distributed data from a fixed set of classes. However, in real-world scenarios, it can be desirable to train models on a continuous stream of data where multiple classification tasks are presented sequentially. This scenario, known as Continual Learning (CL) poses challenges to standard learning algorithms which struggle to maintain knowledge of old tasks while learning new ones. This stability-plasticity dilemma remains central to CL and multiple metrics have been proposed to adequately measure stability and plasticity separately. However, none considers the increasing difficulty of the classification task, which inherently results in performance loss for any model. In that sense, we analyze some limitations of current metrics and identify the presence of setup-induced forgetting. Therefore, we propose new metrics that account for the task's increasing difficulty. Through experiments on benchmark datasets, we demonstrate that our proposed metrics can provide new insights into the stability-plasticity trade-off achieved by models in the continual learning environment.
Learning Representations on the Unit Sphere: Application to Online Continual Learning
Jun 06, 2023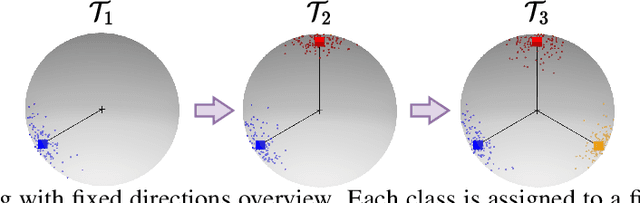
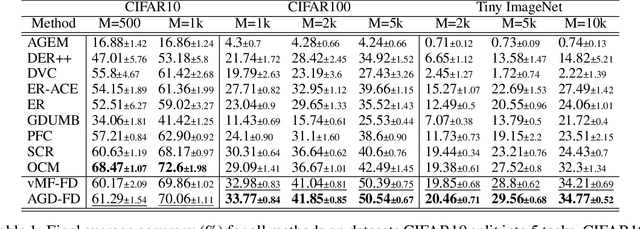
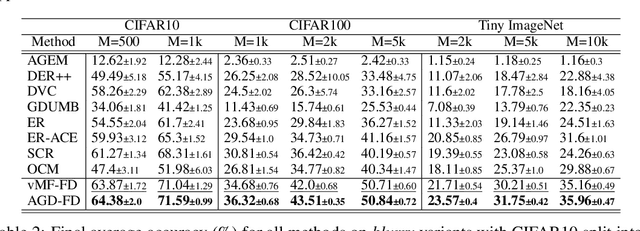
We use the maximum a posteriori estimation principle for learning representations distributed on the unit sphere. We derive loss functions for the von Mises-Fisher distribution and the angular Gaussian distribution, both designed for modeling symmetric directional data. A noteworthy feature of our approach is that the learned representations are pushed toward fixed directions, allowing for a learning strategy that is resilient to data drift. This makes it suitable for online continual learning, which is the problem of training neural networks on a continuous data stream, where multiple classification tasks are presented sequentially so that data from past tasks are no longer accessible, and data from the current task can be seen only once. To address this challenging scenario, we propose a memory-based representation learning technique equipped with our new loss functions. Our approach does not require negative data or knowledge of task boundaries and performs well with smaller batch sizes while being computationally efficient. We demonstrate with extensive experiments that the proposed method outperforms the current state-of-the-art methods on both standard evaluation scenarios and realistic scenarios with blurry task boundaries. For reproducibility, we use the same training pipeline for every compared method and share the code at https://t.ly/SQTj.
Contrastive Learning for Online Semi-Supervised General Continual Learning
Jul 12, 2022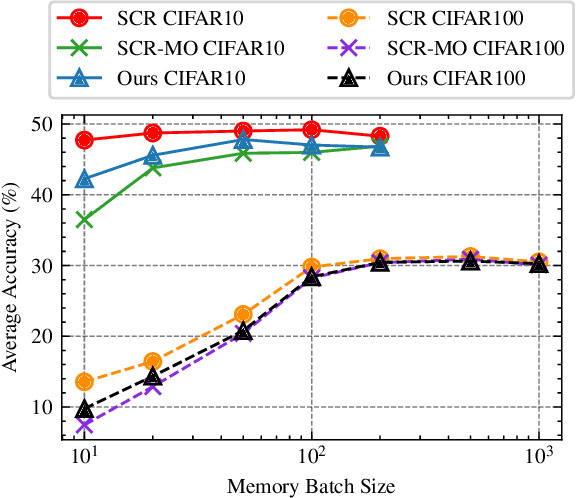

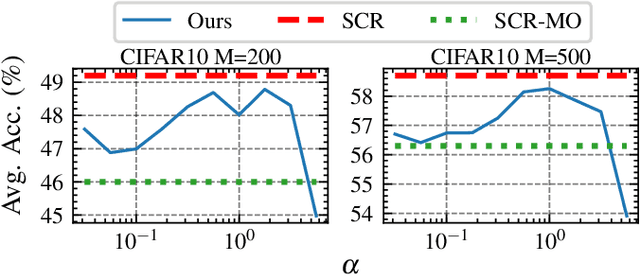
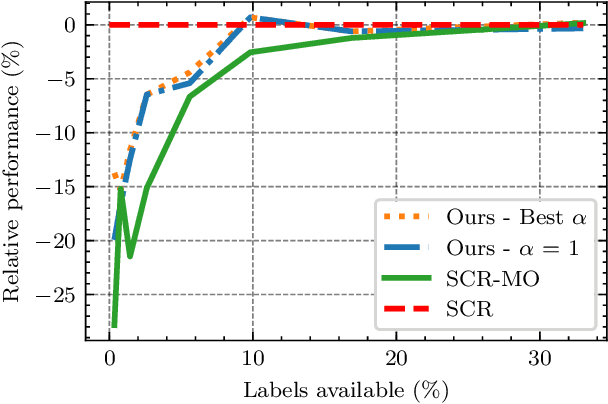
We study Online Continual Learning with missing labels and propose SemiCon, a new contrastive loss designed for partly labeled data. We demonstrate its efficiency by devising a memory-based method trained on an unlabeled data stream, where every data added to memory is labeled using an oracle. Our approach outperforms existing semi-supervised methods when few labels are available, and obtain similar results to state-of-the-art supervised methods while using only 2.6% of labels on Split-CIFAR10 and 10% of labels on Split-CIFAR100.