 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork-Wide Traffic Volume Estimation from Speed Profiles using a Spatio-Temporal Graph Neural Network with Directed Spatial Attention
Dec 15, 2025Existing traffic volume estimation methods typically address either forecasting traffic on sensor-equipped roads or spatially imputing missing volumes using nearby sensors. While forecasting models generally disregard unmonitored roads by design, spatial imputation methods explicitly address network-wide estimation; yet this approach relies on volume data at inference time, limiting its applicability in sensor-scarce cities. Unlike traffic volume data, probe vehicle speeds and static road attributes are more broadly accessible and support full coverage of road segments in most urban networks. In this work, we present the Hybrid Directed-Attention Spatio-Temporal Graph Neural Network (HDA-STGNN), an inductive deep learning framework designed to tackle the network-wide volume estimation problem. Our approach leverages speed profiles, static road attributes, and road network topology to predict daily traffic volume profiles across all road segments in the network. To evaluate the effectiveness of our approach, we perform extensive ablation studies that demonstrate the model's capacity to capture complex spatio-temporal dependencies and highlight the value of topological information for accurate network-wide traffic volume estimation without relying on volume data at inference time.
Clustering Dynamics for Improved Speed Prediction Deriving from Topographical GPS Registrations
Feb 12, 2024A persistent challenge in the field of Intelligent Transportation Systems is to extract accurate traffic insights from geographic regions with scarce or no data coverage. To this end, we propose solutions for speed prediction using sparse GPS data points and their associated topographical and road design features. Our goal is to investigate whether we can use similarities in the terrain and infrastructure to train a machine learning model that can predict speed in regions where we lack transportation data. For this we create a Temporally Orientated Speed Dictionary Centered on Topographically Clustered Roads, which helps us to provide speed correlations to selected feature configurations. Our results show qualitative and quantitative improvement over new and standard regression methods. The presented framework provides a fresh perspective on devising strategies for missing data traffic analysis.
SWMLP: Shared Weight Multilayer Perceptron for Car Trajectory Speed Prediction using Road Topographical Features
Oct 02, 2023Although traffic is one of the massively collected data, it is often only available for specific regions. One concern is that, although there are studies that give good results for these data, the data from these regions may not be sufficiently representative to describe all the traffic patterns in the rest of the world. In quest of addressing this concern, we propose a speed prediction method that is independent of large historical speed data. To predict a vehicle's speed, we use the trajectory road topographical features to fit a Shared Weight Multilayer Perceptron learning model. Our results show significant improvement, both qualitative and quantitative, over standard regression analysis. Moreover, the proposed framework sheds new light on the way to design new approaches for traffic analysis.
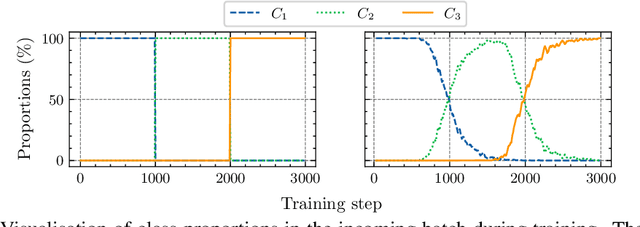
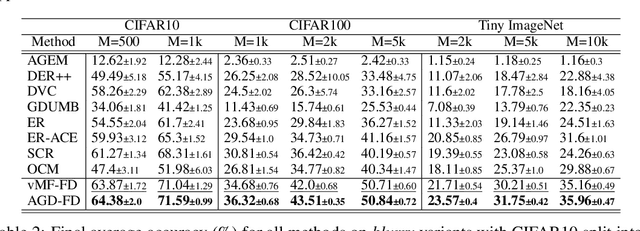
Domain-Aware Augmentations for Unsupervised Online General Continual Learning
Sep 13, 2023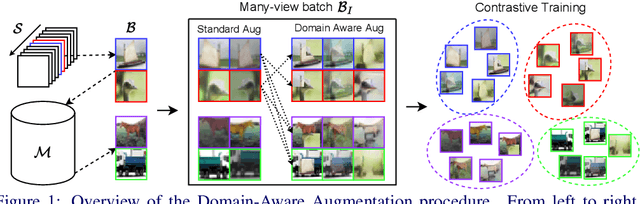
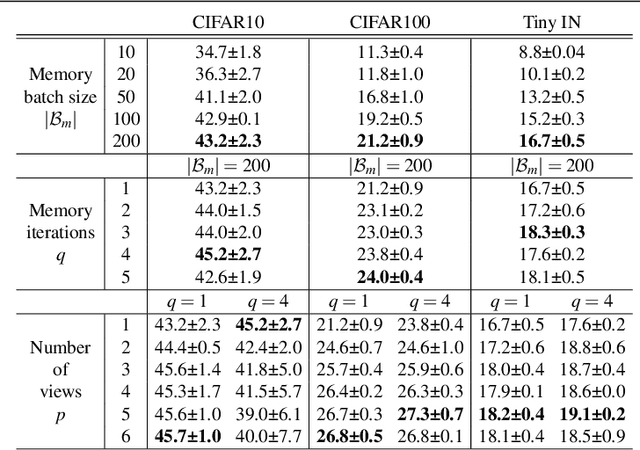
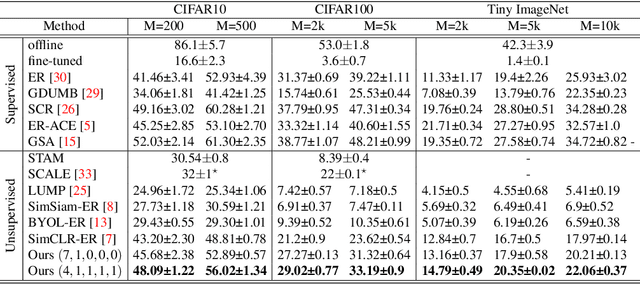
Continual Learning has been challenging, especially when dealing with unsupervised scenarios such as Unsupervised Online General Continual Learning (UOGCL), where the learning agent has no prior knowledge of class boundaries or task change information. While previous research has focused on reducing forgetting in supervised setups, recent studies have shown that self-supervised learners are more resilient to forgetting. This paper proposes a novel approach that enhances memory usage for contrastive learning in UOGCL by defining and using stream-dependent data augmentations together with some implementation tricks. Our proposed method is simple yet effective, achieves state-of-the-art results compared to other unsupervised approaches in all considered setups, and reduces the gap between supervised and unsupervised continual learning. Our domain-aware augmentation procedure can be adapted to other replay-based methods, making it a promising strategy for continual learning.
New metrics for analyzing continual learners
Sep 01, 2023
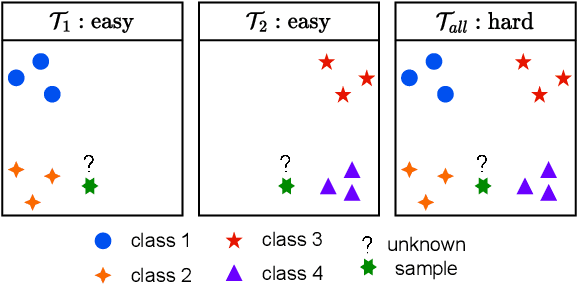
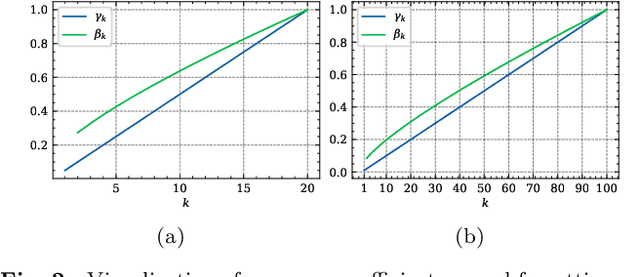
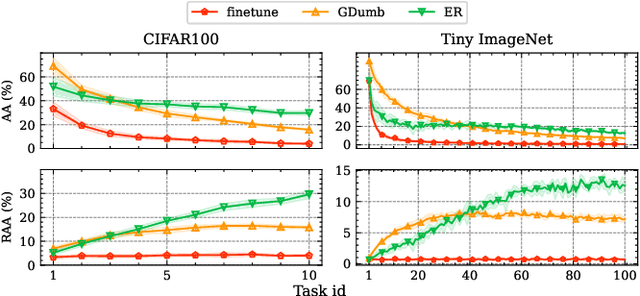
Deep neural networks have shown remarkable performance when trained on independent and identically distributed data from a fixed set of classes. However, in real-world scenarios, it can be desirable to train models on a continuous stream of data where multiple classification tasks are presented sequentially. This scenario, known as Continual Learning (CL) poses challenges to standard learning algorithms which struggle to maintain knowledge of old tasks while learning new ones. This stability-plasticity dilemma remains central to CL and multiple metrics have been proposed to adequately measure stability and plasticity separately. However, none considers the increasing difficulty of the classification task, which inherently results in performance loss for any model. In that sense, we analyze some limitations of current metrics and identify the presence of setup-induced forgetting. Therefore, we propose new metrics that account for the task's increasing difficulty. Through experiments on benchmark datasets, we demonstrate that our proposed metrics can provide new insights into the stability-plasticity trade-off achieved by models in the continual learning environment.
Learning Representations on the Unit Sphere: Application to Online Continual Learning
Jun 06, 2023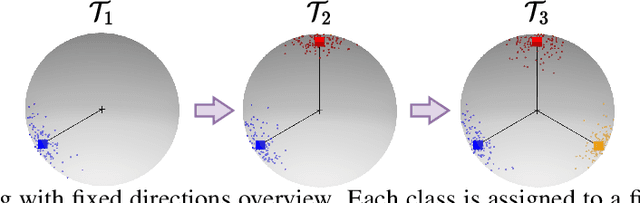
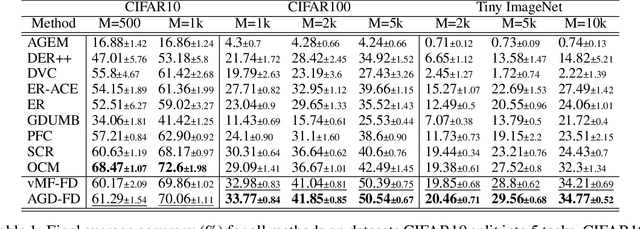
We use the maximum a posteriori estimation principle for learning representations distributed on the unit sphere. We derive loss functions for the von Mises-Fisher distribution and the angular Gaussian distribution, both designed for modeling symmetric directional data. A noteworthy feature of our approach is that the learned representations are pushed toward fixed directions, allowing for a learning strategy that is resilient to data drift. This makes it suitable for online continual learning, which is the problem of training neural networks on a continuous data stream, where multiple classification tasks are presented sequentially so that data from past tasks are no longer accessible, and data from the current task can be seen only once. To address this challenging scenario, we propose a memory-based representation learning technique equipped with our new loss functions. Our approach does not require negative data or knowledge of task boundaries and performs well with smaller batch sizes while being computationally efficient. We demonstrate with extensive experiments that the proposed method outperforms the current state-of-the-art methods on both standard evaluation scenarios and realistic scenarios with blurry task boundaries. For reproducibility, we use the same training pipeline for every compared method and share the code at https://t.ly/SQTj.
Contrastive Learning for Online Semi-Supervised General Continual Learning
Jul 12, 2022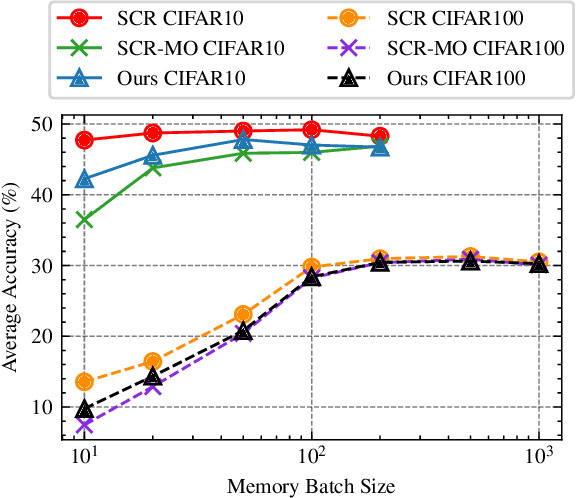

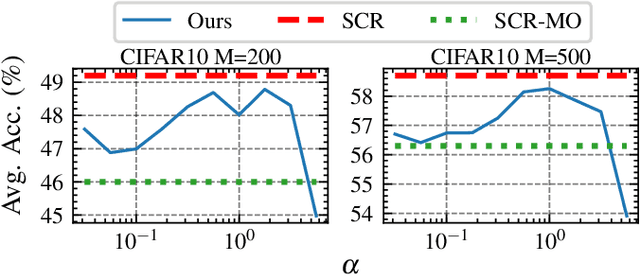
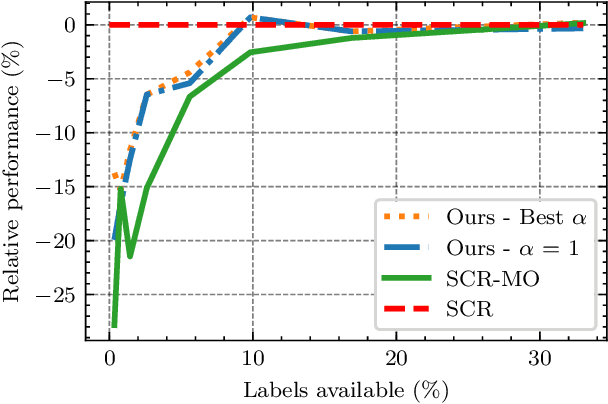
We study Online Continual Learning with missing labels and propose SemiCon, a new contrastive loss designed for partly labeled data. We demonstrate its efficiency by devising a memory-based method trained on an unlabeled data stream, where every data added to memory is labeled using an oracle. Our approach outperforms existing semi-supervised methods when few labels are available, and obtain similar results to state-of-the-art supervised methods while using only 2.6% of labels on Split-CIFAR10 and 10% of labels on Split-CIFAR100.
FGOT: Graph Distances based on Filters and Optimal Transport
Sep 11, 2021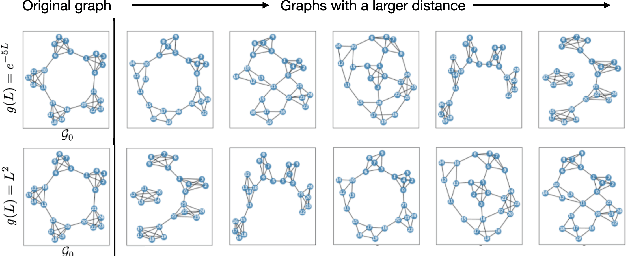
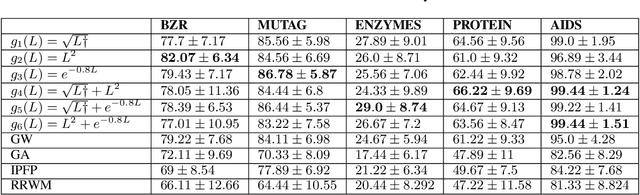
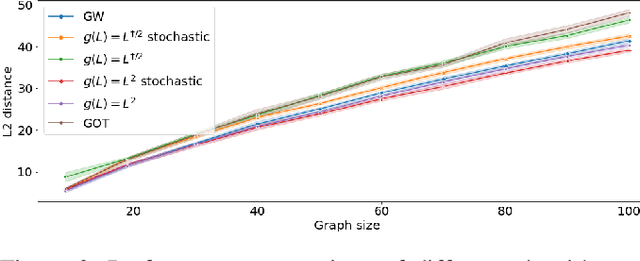
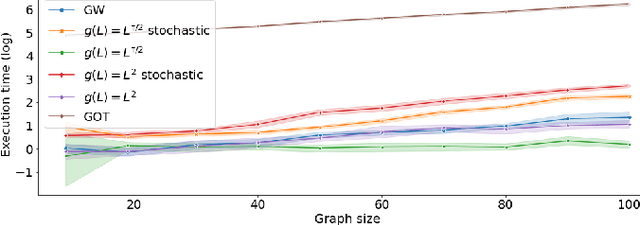
Graph comparison deals with identifying similarities and dissimilarities between graphs. A major obstacle is the unknown alignment of graphs, as well as the lack of accurate and inexpensive comparison metrics. In this work we introduce the filter graph distance. It is an optimal transport based distance which drives graph comparison through the probability distribution of filtered graph signals. This creates a highly flexible distance, capable of prioritising different spectral information in observed graphs, offering a wide range of choices for a comparison metric. We tackle the problem of graph alignment by computing graph permutations that minimise our new filter distances, which implicitly solves the graph comparison problem. We then propose a new approximate cost function that circumvents many computational difficulties inherent to graph comparison and permits the exploitation of fast algorithms such as mirror gradient descent, without grossly sacrificing the performance. We finally propose a novel algorithm derived from a stochastic version of mirror gradient descent, which accommodates the non-convexity of the alignment problem, offering a good trade-off between performance accuracy and speed. The experiments on graph alignment and classification show that the flexibility gained through filter graph distances can have a significant impact on performance, while the difference in speed offered by the approximation cost makes the framework applicable in practical settings.
SuperDeConFuse: A Supervised Deep Convolutional Transform based Fusion Framework for Financial Trading Systems
Nov 09, 2020
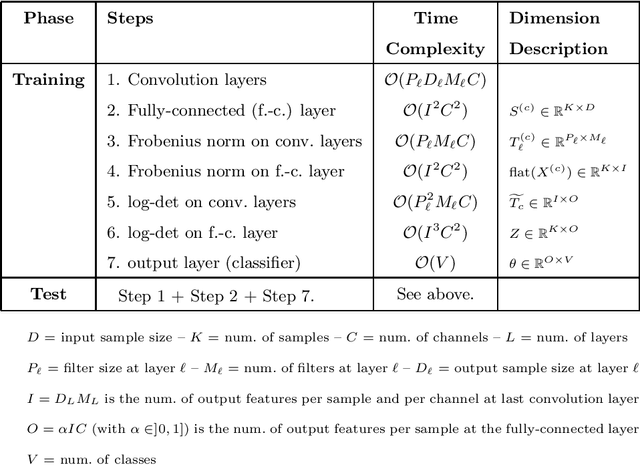
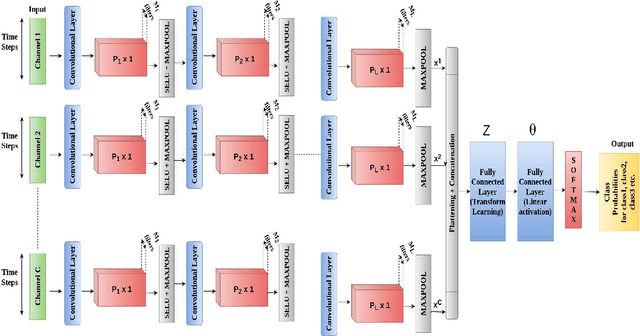
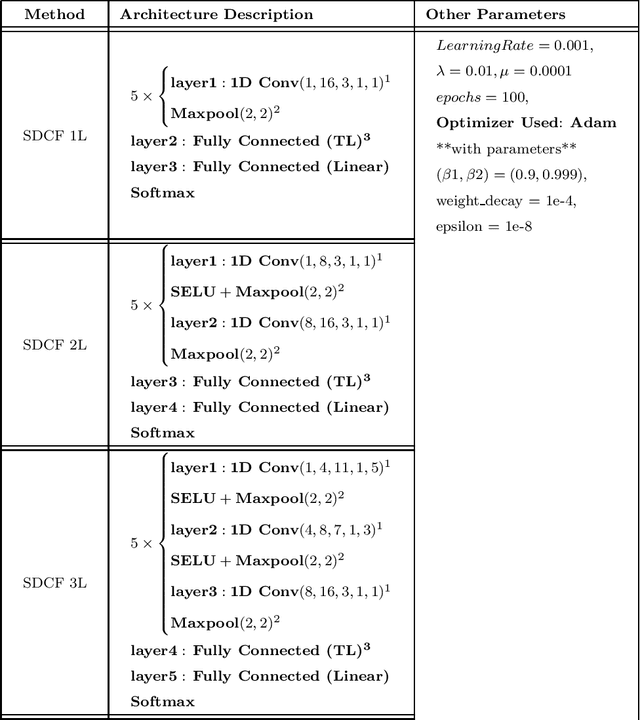
This work proposes a supervised multi-channel time-series learning framework for financial stock trading. Although many deep learning models have recently been proposed in this domain, most of them treat the stock trading time-series data as 2-D image data, whereas its true nature is 1-D time-series data. Since the stock trading systems are multi-channel data, many existing techniques treating them as 1-D time-series data are not suggestive of any technique to effectively fusion the information carried by the multiple channels. To contribute towards both of these shortcomings, we propose an end-to-end supervised learning framework inspired by the previously established (unsupervised) convolution transform learning framework. Our approach consists of processing the data channels through separate 1-D convolution layers, then fusing the outputs with a series of fully-connected layers, and finally applying a softmax classification layer. The peculiarity of our framework - SuperDeConFuse (SDCF), is that we remove the nonlinear activation located between the multi-channel convolution layers and the fully-connected layers, as well as the one located between the latter and the output layer. We compensate for this removal by introducing a suitable regularization on the aforementioned layer outputs and filters during the training phase. Specifically, we apply a logarithm determinant regularization on the layer filters to break symmetry and force diversity in the learnt transforms, whereas we enforce the non-negativity constraint on the layer outputs to mitigate the issue of dead neurons. This results in the effective learning of a richer set of features and filters with respect to a standard convolutional neural network. Numerical experiments confirm that the proposed model yields considerably better results than state-of-the-art deep learning techniques for real-world problem of stock trading.
DeConFuse : A Deep Convolutional Transform based Unsupervised Fusion Framework
Nov 09, 2020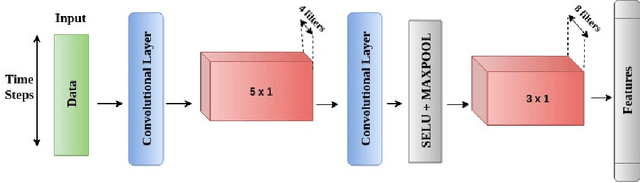
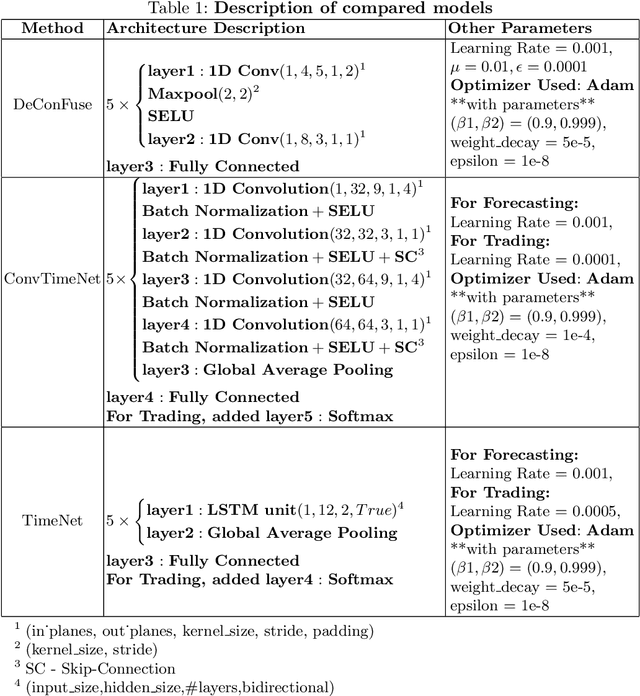
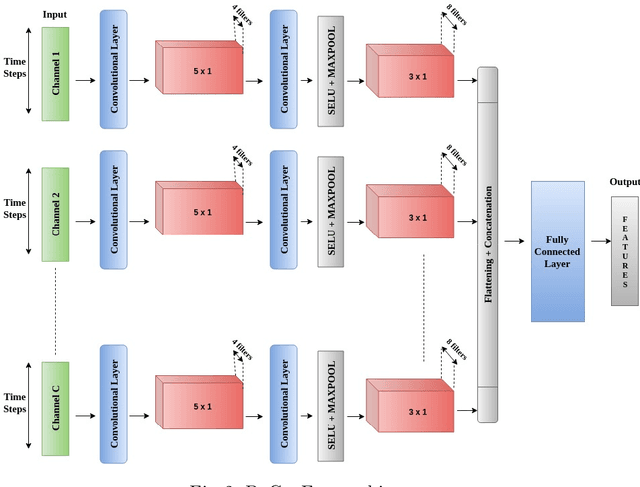
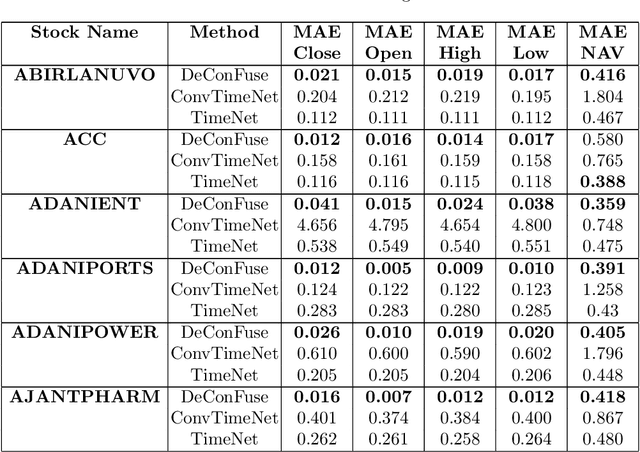
This work proposes an unsupervised fusion framework based on deep convolutional transform learning. The great learning ability of convolutional filters for data analysis is well acknowledged. The success of convolutive features owes to convolutional neural network (CNN). However, CNN cannot perform learning tasks in an unsupervised fashion. In a recent work, we show that such shortcoming can be addressed by adopting a convolutional transform learning (CTL) approach, where convolutional filters are learnt in an unsupervised fashion. The present paper aims at (i) proposing a deep version of CTL; (ii) proposing an unsupervised fusion formulation taking advantage of the proposed deep CTL representation; (iii) developing a mathematically sounded optimization strategy for performing the learning task. We apply the proposed technique, named DeConFuse, on the problem of stock forecasting and trading. Comparison with state-of-the-art methods (based on CNN and long short-term memory network) shows the superiority of our method for performing a reliable feature extraction.