 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeConFuse : A Deep Convolutional Transform based Unsupervised Fusion Framework
Nov 09, 2020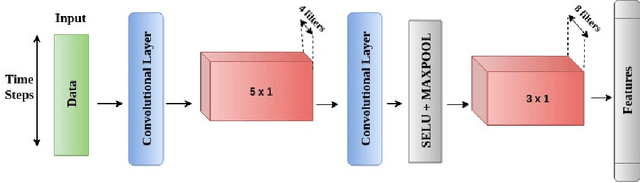
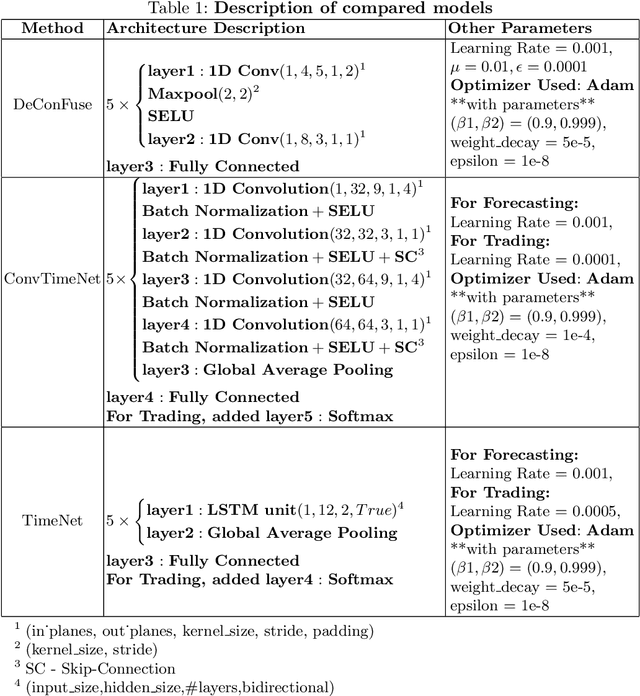
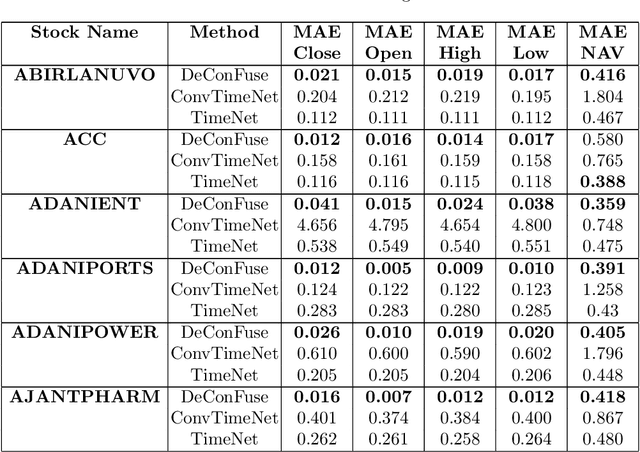
This work proposes an unsupervised fusion framework based on deep convolutional transform learning. The great learning ability of convolutional filters for data analysis is well acknowledged. The success of convolutive features owes to convolutional neural network (CNN). However, CNN cannot perform learning tasks in an unsupervised fashion. In a recent work, we show that such shortcoming can be addressed by adopting a convolutional transform learning (CTL) approach, where convolutional filters are learnt in an unsupervised fashion. The present paper aims at (i) proposing a deep version of CTL; (ii) proposing an unsupervised fusion formulation taking advantage of the proposed deep CTL representation; (iii) developing a mathematically sounded optimization strategy for performing the learning task. We apply the proposed technique, named DeConFuse, on the problem of stock forecasting and trading. Comparison with state-of-the-art methods (based on CNN and long short-term memory network) shows the superiority of our method for performing a reliable feature extraction.
ConFuse: Convolutional Transform Learning Fusion Framework For Multi-Channel Data Analysis
Nov 09, 2020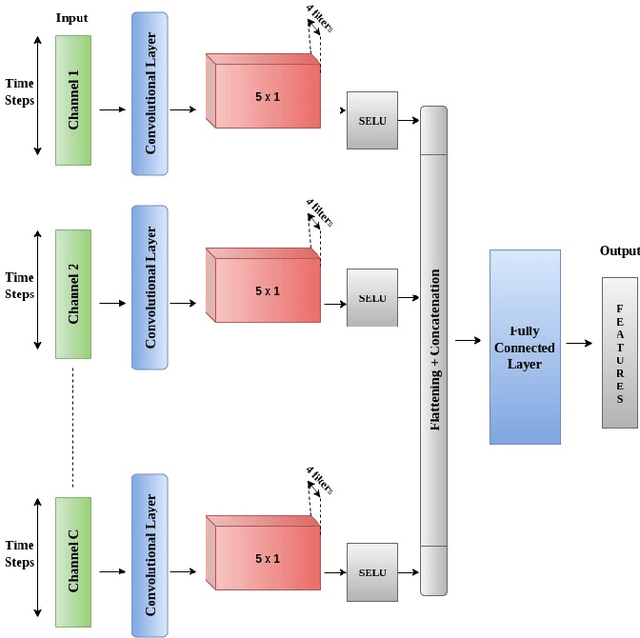
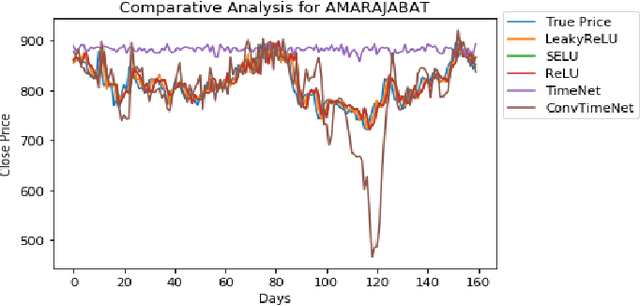

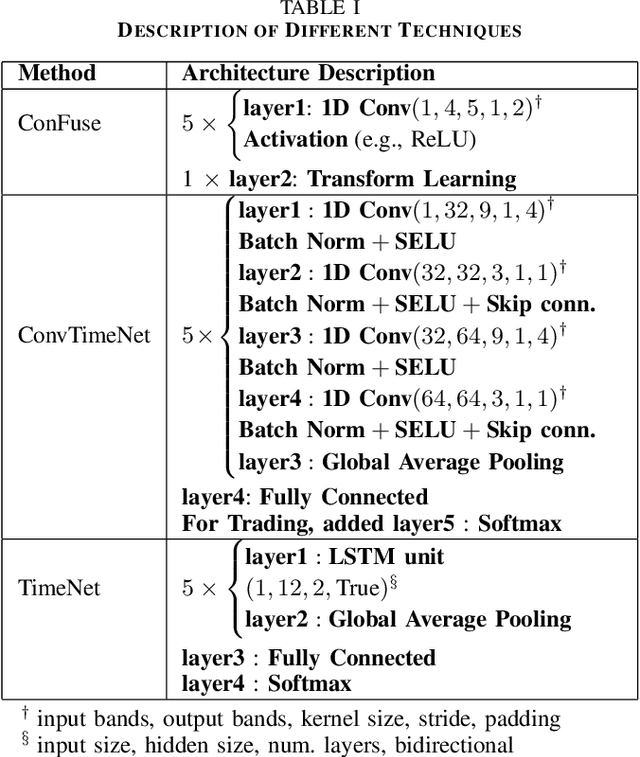
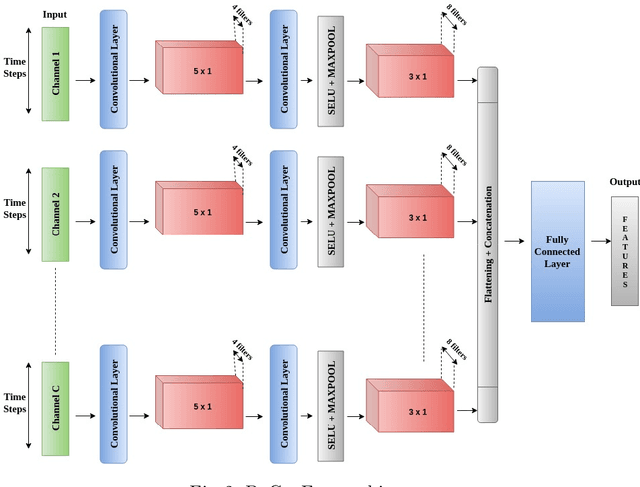
This work addresses the problem of analyzing multi-channel time series data %. In this paper, we by proposing an unsupervised fusion framework based on %the recently proposed convolutional transform learning. Each channel is processed by a separate 1D convolutional transform; the output of all the channels are fused by a fully connected layer of transform learning. The training procedure takes advantage of the proximal interpretation of activation functions. We apply the developed framework to multi-channel financial data for stock forecasting and trading. We compare our proposed formulation with benchmark deep time series analysis networks. The results show that our method yields considerably better results than those compared against.
Deep Convolutional Transform Learning -- Extended version
Oct 02, 2020

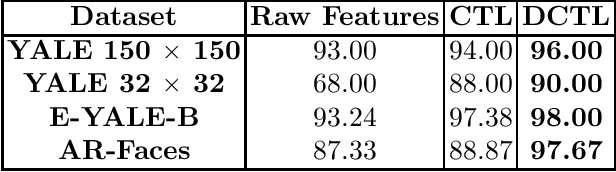

This work introduces a new unsupervised representation learning technique called Deep Convolutional Transform Learning (DCTL). By stacking convolutional transforms, our approach is able to learn a set of independent kernels at different layers. The features extracted in an unsupervised manner can then be used to perform machine learning tasks, such as classification and clustering. The learning technique relies on a well-sounded alternating proximal minimization scheme with established convergence guarantees. Our experimental results show that the proposed DCTL technique outperforms its shallow version CTL, on several benchmark datasets.
Kernel Transform Learning
Dec 11, 2019
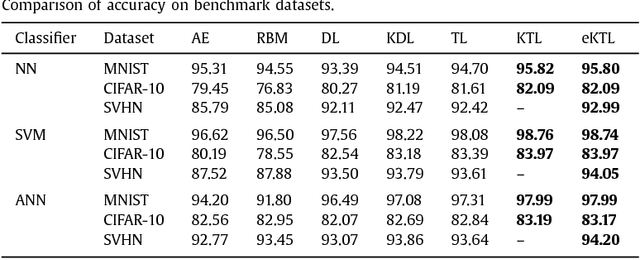
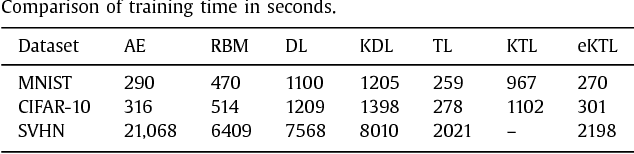
This work proposes kernel transform learning. The idea of dictionary learning is well known; it is a synthesis formulation where a basis is learnt along with the coefficients so as to generate or synthesize the data. Transform learning is its analysis equivalent; the transforms operates or analyses on the data to generate the coefficients. The concept of kernel dictionary learning has been introduced in the recent past, where the dictionary is represented as a linear combination of non-linear version of the data. Its success has been showcased in feature extraction. In this work we propose to kernelize transform learning on line similar to kernel dictionary learning. An efficient solution for kernel transform learning has been proposed especially for problems where the number of samples is much larger than the dimensionality of the input samples making the kernel matrix very high dimensional. Kernel transform learning has been compared with other representation learning tools like autoencoder, restricted Boltzmann machine as well as with dictionary learning (and its kernelized version). Our proposed kernel transform learning yields better results than all the aforesaid techniques; experiments have been carried out on benchmark databases.
Multi-echo Reconstruction from Partial K-space Scans via Adaptively Learnt Basis
Dec 11, 2019
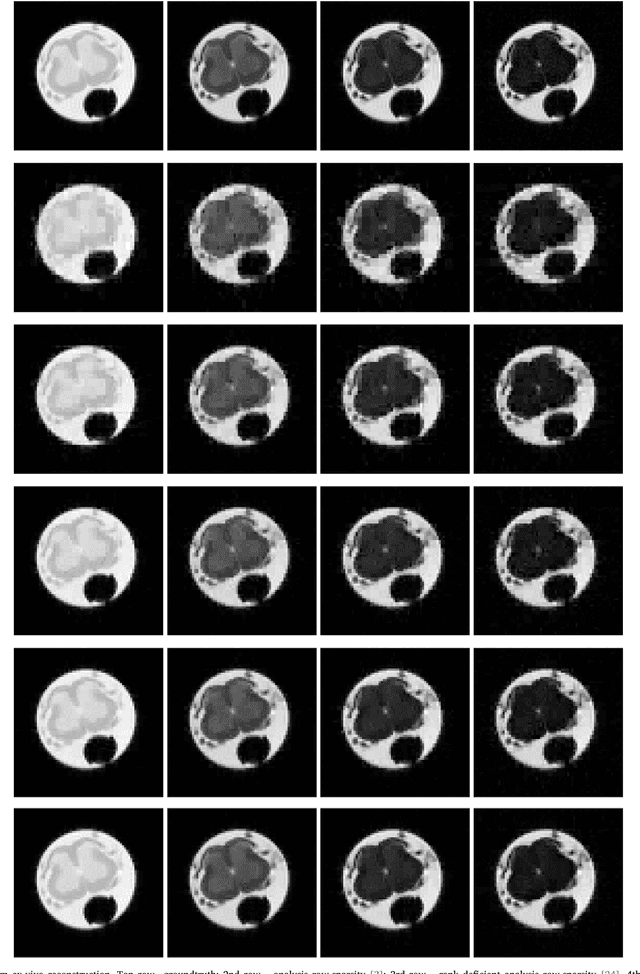

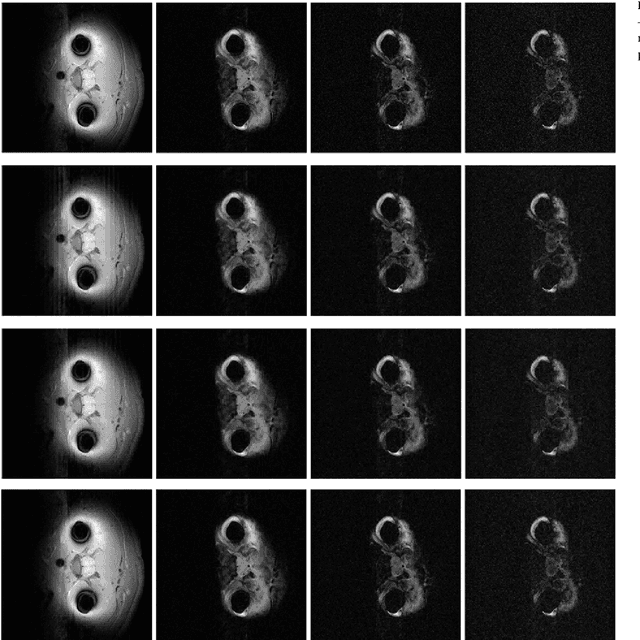
In multi echo imaging, multiple T1/T2 weighted images of the same cross section is acquired. Acquiring multiple scans is time consuming. In order to accelerate, compressed sensing based techniques have been proposed. In recent times, it has been observed in several areas of traditional compressed sensing, that instead of using fixed basis (wavelet, DCT etc.), considerably better results can be achieved by learning the basis adaptively from the data. Motivated by these studies, we propose to employ such adaptive learning techniques to improve reconstruction of multi-echo scans. This work will be based on two basis learning models synthesis (better known as dictionary learning) and analysis (known as transform learning). We modify these basic methods by incorporating structure of the multi echo scans. Our work shows that we can indeed significantly improve multi-echo imaging over compressed sensing based techniques and other unstructured adaptive sparse recovery methods.
Simultaneous Detection of Multiple Appliances from Smart-meter Measurements via Multi-Label Consistent Deep Dictionary Learning and Deep Transform Learning
Dec 11, 2019

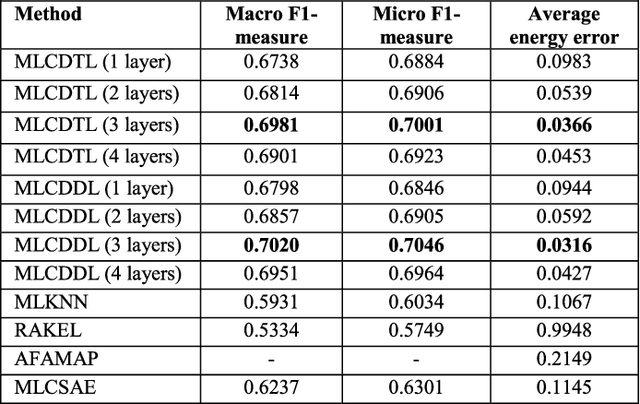
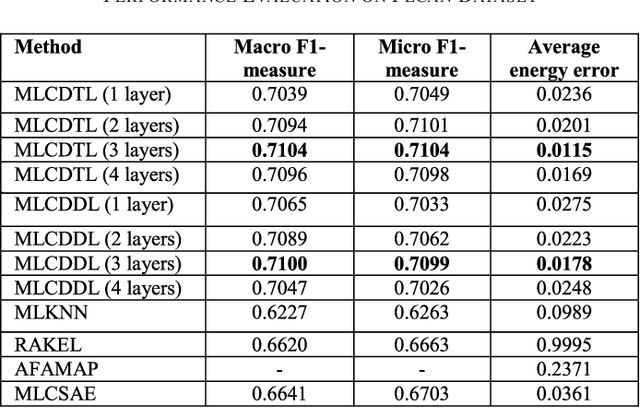
Currently there are several well-known approaches to non-intrusive appliance load monitoring rule based, stochastic finite state machines, neural networks and sparse coding. Recently several studies have proposed a new approach based on multi label classification. Different appliances are treated as separate classes, and the task is to identify the classes given the aggregate smart-meter reading. Prior studies in this area have used off the shelf algorithms like MLKNN and RAKEL to address this problem. In this work, we propose a deep learning based technique. There are hardly any studies in deep learning based multi label classification; two new deep learning techniques to solve the said problem are fundamental contributions of this work. These are deep dictionary learning and deep transform learning. Thorough experimental results on benchmark datasets show marked improvement over existing studies.
Label Consistent Transform Learning for Hyperspectral Image Classification
Dec 11, 2019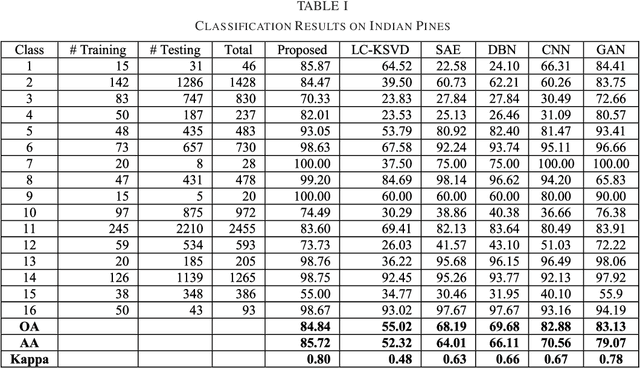


This work proposes a new image analysis tool called Label Consistent Transform Learning (LCTL). Transform learning is a recent unsupervised representation learning approach; we add supervision by incorporating a label consistency constraint. The proposed technique is especially suited for hyper-spectral image classification problems owing to its ability to learn from fewer samples. We have compared our proposed method on state-of-the-art techniques like label consistent KSVD, Stacked Autoencoder, Deep Belief Network and Convolutional Neural Network. Our method yields considerably better results (more than 0.1 improvement in Kappa coefficient) than all the aforesaid techniques.
Transformed Subspace Clustering
Dec 10, 2019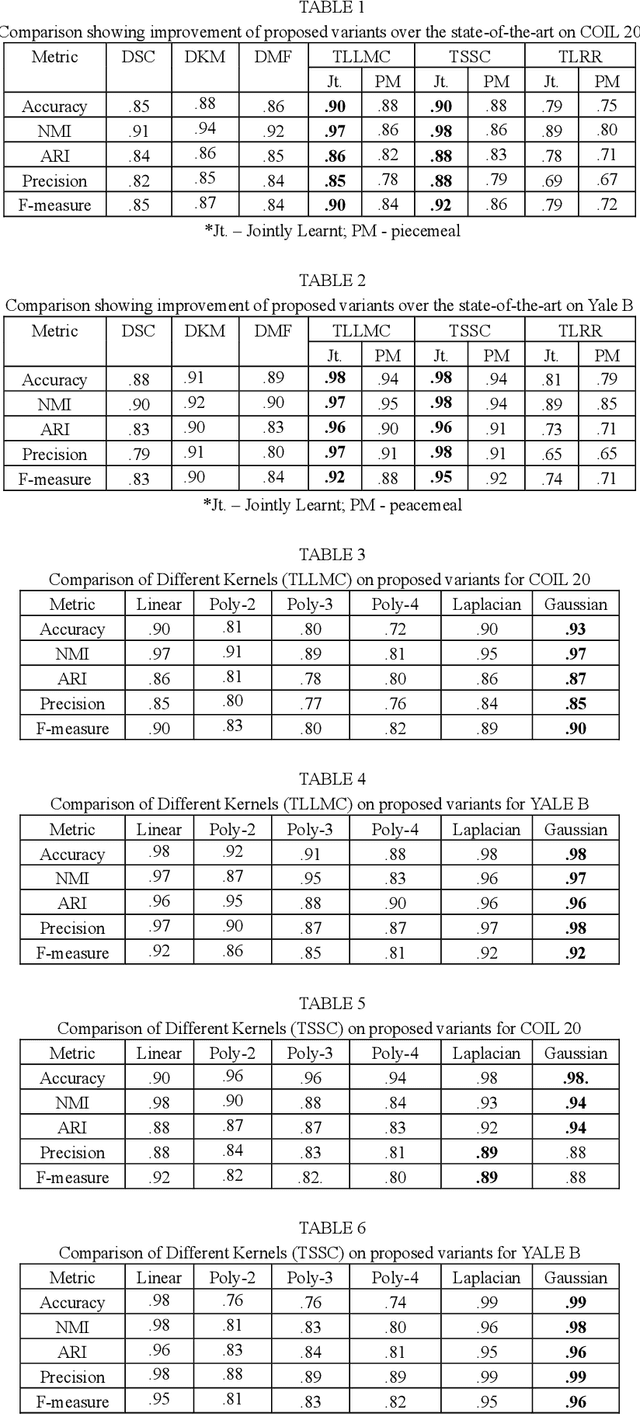
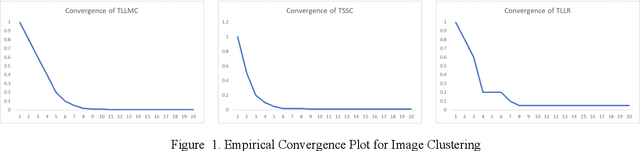
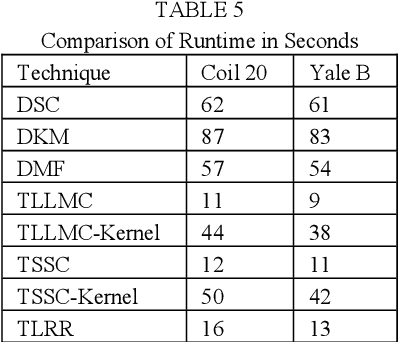
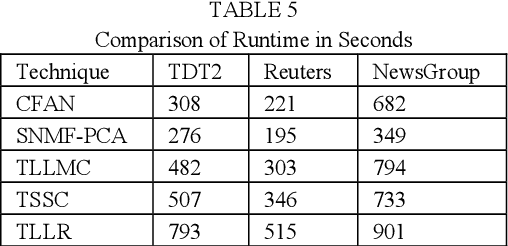
Subspace clustering assumes that the data is sepa-rable into separate subspaces. Such a simple as-sumption, does not always hold. We assume that, even if the raw data is not separable into subspac-es, one can learn a representation (transform coef-ficients) such that the learnt representation is sep-arable into subspaces. To achieve the intended goal, we embed subspace clustering techniques (locally linear manifold clustering, sparse sub-space clustering and low rank representation) into transform learning. The entire formulation is jointly learnt; giving rise to a new class of meth-ods called transformed subspace clustering (TSC). In order to account for non-linearity, ker-nelized extensions of TSC are also proposed. To test the performance of the proposed techniques, benchmarking is performed on image clustering and document clustering datasets. Comparison with state-of-the-art clustering techniques shows that our formulation improves upon them.