 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRawlsian Fair Adaptation of Deep Learning Classifiers
May 31, 2021



Group-fairness in classification aims for equality of a predictive utility across different sensitive sub-populations, e.g., race or gender. Equality or near-equality constraints in group-fairness often worsen not only the aggregate utility but also the utility for the least advantaged sub-population. In this paper, we apply the principles of Pareto-efficiency and least-difference to the utility being accuracy, as an illustrative example, and arrive at the Rawls classifier that minimizes the error rate on the worst-off sensitive sub-population. Our mathematical characterization shows that the Rawls classifier uniformly applies a threshold to an ideal score of features, in the spirit of fair equality of opportunity. In practice, such a score or a feature representation is often computed by a black-box model that has been useful but unfair. Our second contribution is practical Rawlsian fair adaptation of any given black-box deep learning model, without changing the score or feature representation it computes. Given any score function or feature representation and only its second-order statistics on the sensitive sub-populations, we seek a threshold classifier on the given score or a linear threshold classifier on the given feature representation that achieves the Rawls error rate restricted to this hypothesis class. Our technical contribution is to formulate the above problems using ambiguous chance constraints, and to provide efficient algorithms for Rawlsian fair adaptation, along with provable upper bounds on the Rawls error rate. Our empirical results show significant improvement over state-of-the-art group-fair algorithms, even without retraining for fairness.
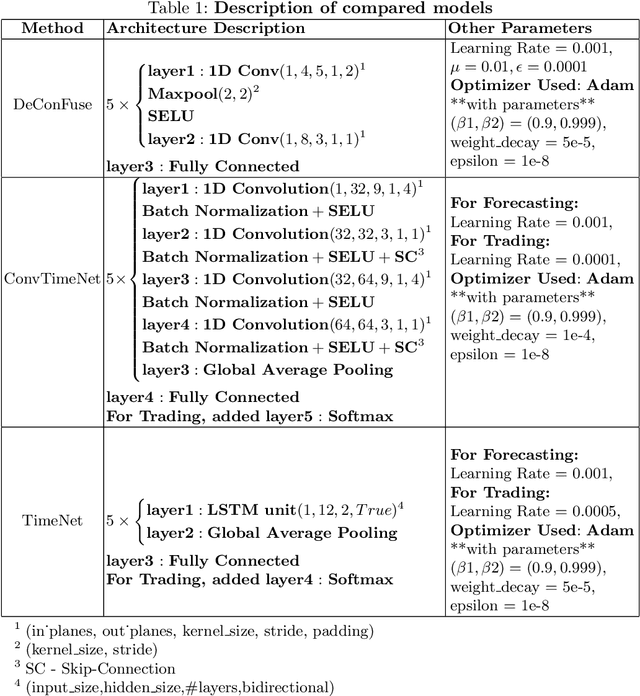
SuperDeConFuse: A Supervised Deep Convolutional Transform based Fusion Framework for Financial Trading Systems
Nov 09, 2020
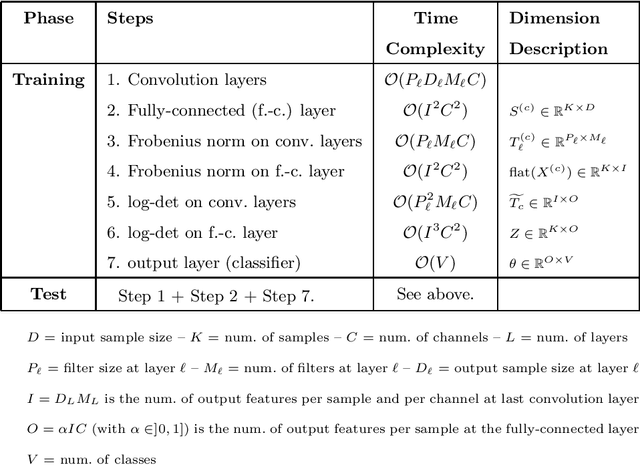
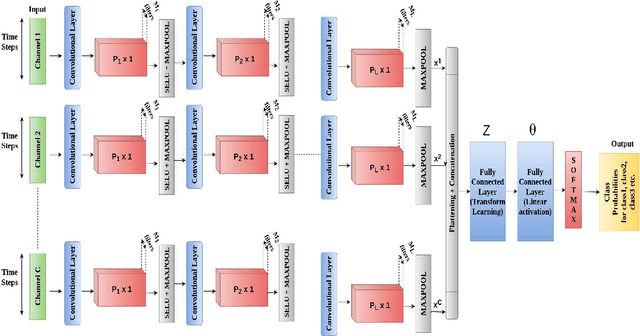
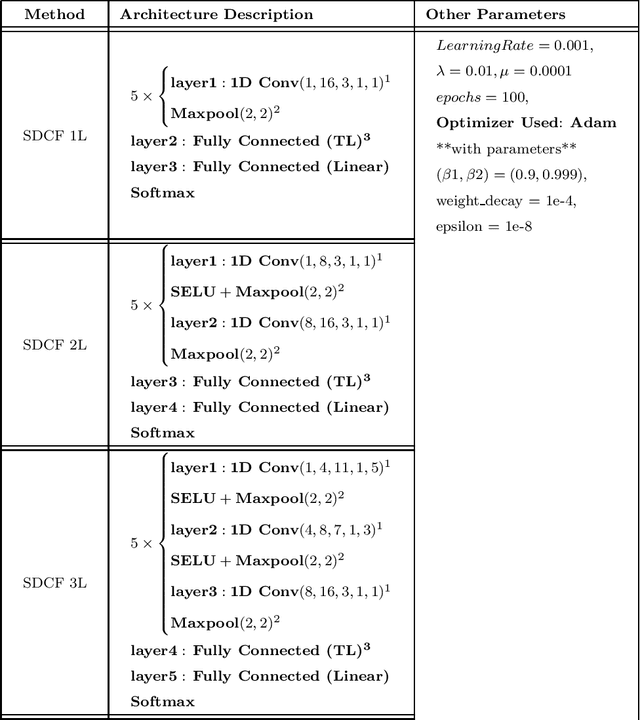
This work proposes a supervised multi-channel time-series learning framework for financial stock trading. Although many deep learning models have recently been proposed in this domain, most of them treat the stock trading time-series data as 2-D image data, whereas its true nature is 1-D time-series data. Since the stock trading systems are multi-channel data, many existing techniques treating them as 1-D time-series data are not suggestive of any technique to effectively fusion the information carried by the multiple channels. To contribute towards both of these shortcomings, we propose an end-to-end supervised learning framework inspired by the previously established (unsupervised) convolution transform learning framework. Our approach consists of processing the data channels through separate 1-D convolution layers, then fusing the outputs with a series of fully-connected layers, and finally applying a softmax classification layer. The peculiarity of our framework - SuperDeConFuse (SDCF), is that we remove the nonlinear activation located between the multi-channel convolution layers and the fully-connected layers, as well as the one located between the latter and the output layer. We compensate for this removal by introducing a suitable regularization on the aforementioned layer outputs and filters during the training phase. Specifically, we apply a logarithm determinant regularization on the layer filters to break symmetry and force diversity in the learnt transforms, whereas we enforce the non-negativity constraint on the layer outputs to mitigate the issue of dead neurons. This results in the effective learning of a richer set of features and filters with respect to a standard convolutional neural network. Numerical experiments confirm that the proposed model yields considerably better results than state-of-the-art deep learning techniques for real-world problem of stock trading.
DeConFuse : A Deep Convolutional Transform based Unsupervised Fusion Framework
Nov 09, 2020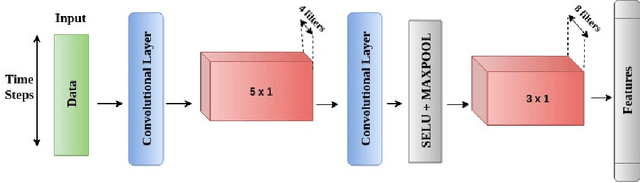
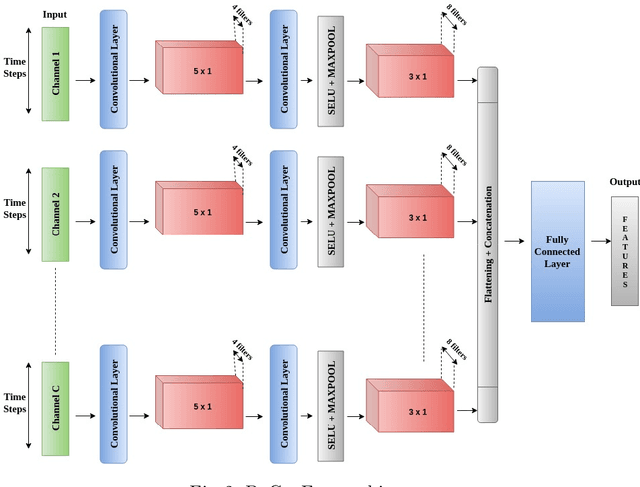
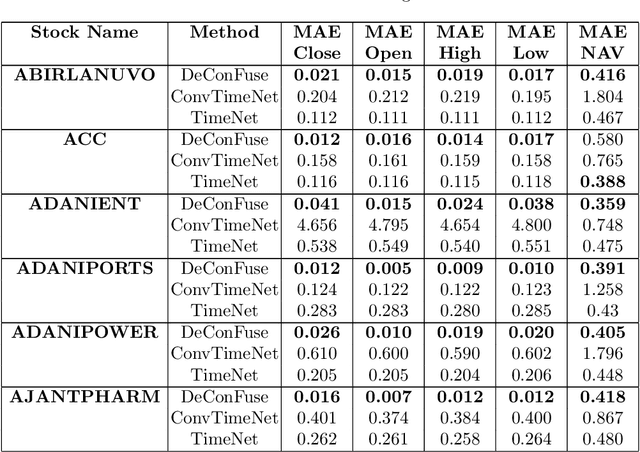
This work proposes an unsupervised fusion framework based on deep convolutional transform learning. The great learning ability of convolutional filters for data analysis is well acknowledged. The success of convolutive features owes to convolutional neural network (CNN). However, CNN cannot perform learning tasks in an unsupervised fashion. In a recent work, we show that such shortcoming can be addressed by adopting a convolutional transform learning (CTL) approach, where convolutional filters are learnt in an unsupervised fashion. The present paper aims at (i) proposing a deep version of CTL; (ii) proposing an unsupervised fusion formulation taking advantage of the proposed deep CTL representation; (iii) developing a mathematically sounded optimization strategy for performing the learning task. We apply the proposed technique, named DeConFuse, on the problem of stock forecasting and trading. Comparison with state-of-the-art methods (based on CNN and long short-term memory network) shows the superiority of our method for performing a reliable feature extraction.
ConFuse: Convolutional Transform Learning Fusion Framework For Multi-Channel Data Analysis
Nov 09, 2020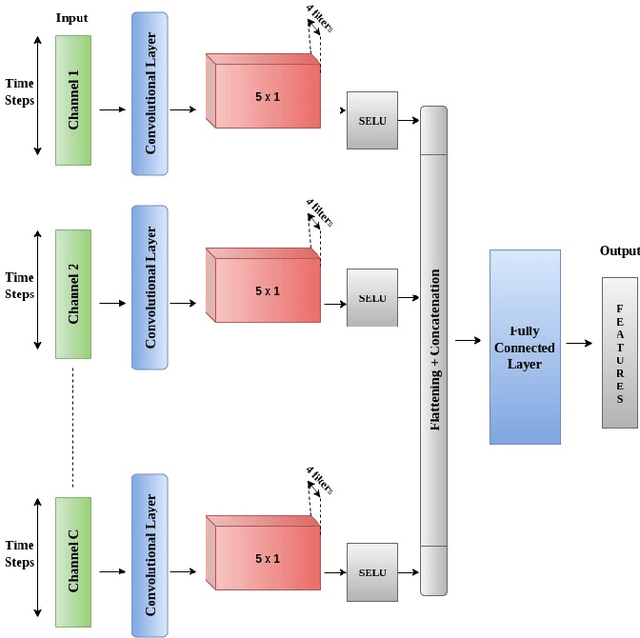
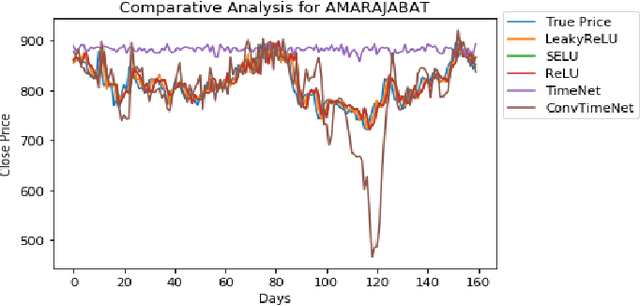

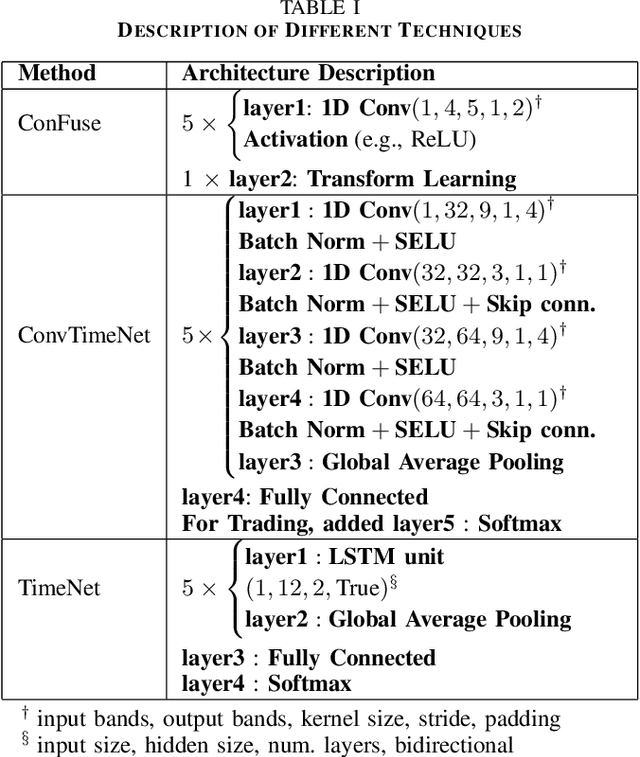
This work addresses the problem of analyzing multi-channel time series data %. In this paper, we by proposing an unsupervised fusion framework based on %the recently proposed convolutional transform learning. Each channel is processed by a separate 1D convolutional transform; the output of all the channels are fused by a fully connected layer of transform learning. The training procedure takes advantage of the proximal interpretation of activation functions. We apply the developed framework to multi-channel financial data for stock forecasting and trading. We compare our proposed formulation with benchmark deep time series analysis networks. The results show that our method yields considerably better results than those compared against.
Quality Estimation Of Machine Translation Outputs Through Stemming
Jul 10, 2014

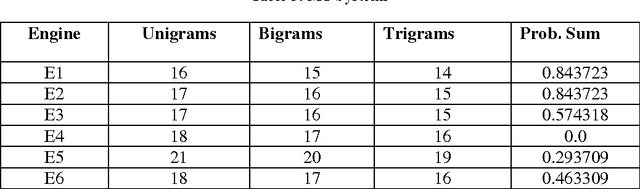
Machine Translation is the challenging problem for Indian languages. Every day we can see some machine translators being developed, but getting a high quality automatic translation is still a very distant dream . The correct translated sentence for Hindi language is rarely found. In this paper, we are emphasizing on English-Hindi language pair, so in order to preserve the correct MT output we present a ranking system, which employs some machine learning techniques and morphological features. In ranking no human intervention is required. We have also validated our results by comparing it with human ranking.
Automatic Ranking of MT Outputs using Approximations
Nov 22, 2013

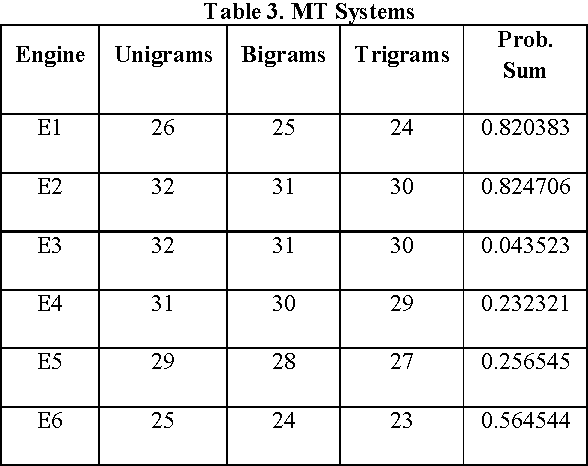
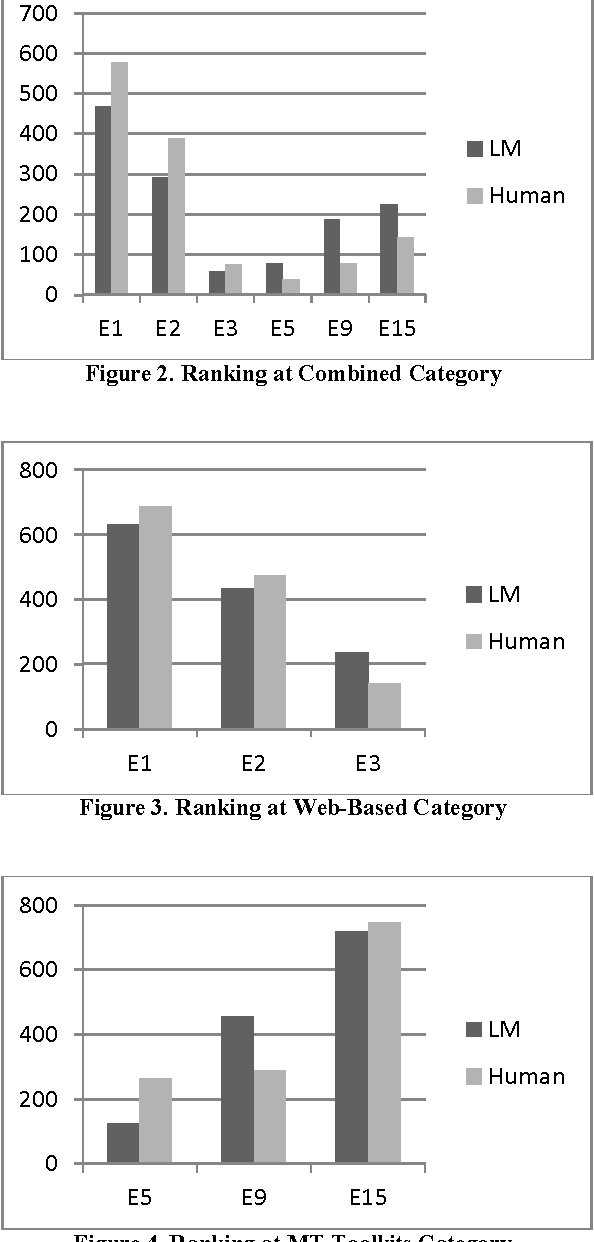
Since long, research on machine translation has been ongoing. Still, we do not get good translations from MT engines so developed. Manual ranking of these outputs tends to be very time consuming and expensive. Identifying which one is better or worse than the others is a very taxing task. In this paper, we show an approach which can provide automatic ranks to MT outputs (translations) taken from different MT Engines and which is based on N-gram approximations. We provide a solution where no human intervention is required for ranking systems. Further we also show the evaluations of our results which show equivalent results as that of human ranking.