 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifier-Based Text Simplification for Improved Machine Translation
Jul 12, 2015



Machine Translation is one of the research fields of Computational Linguistics. The objective of many MT Researchers is to develop an MT System that produce good quality and high accuracy output translations and which also covers maximum language pairs. As internet and Globalization is increasing day by day, we need a way that improves the quality of translation. For this reason, we have developed a Classifier based Text Simplification Model for English-Hindi Machine Translation Systems. We have used support vector machines and Na\"ive Bayes Classifier to develop this model. We have also evaluated the performance of these classifiers.
Quality Estimation Of Machine Translation Outputs Through Stemming
Jul 10, 2014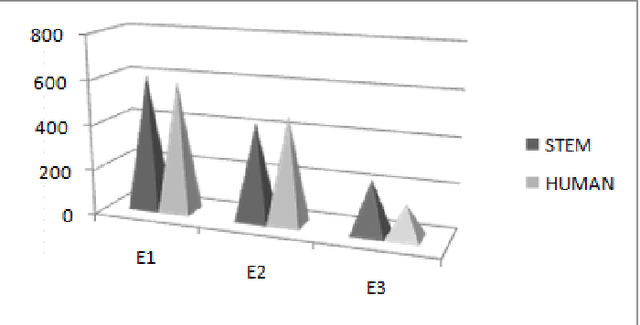
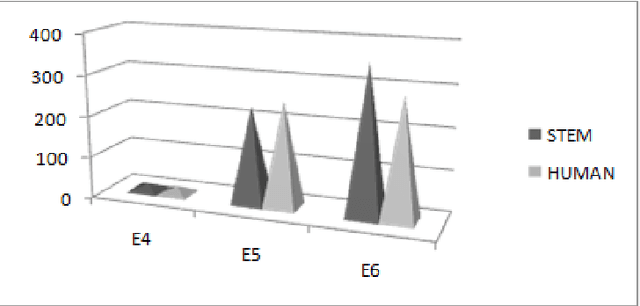

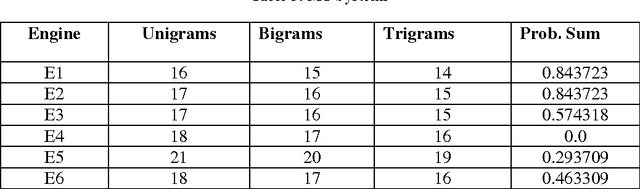
Machine Translation is the challenging problem for Indian languages. Every day we can see some machine translators being developed, but getting a high quality automatic translation is still a very distant dream . The correct translated sentence for Hindi language is rarely found. In this paper, we are emphasizing on English-Hindi language pair, so in order to preserve the correct MT output we present a ranking system, which employs some machine learning techniques and morphological features. In ranking no human intervention is required. We have also validated our results by comparing it with human ranking.
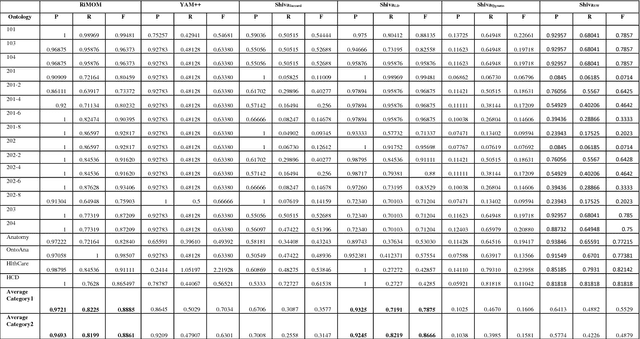
Shiva++: An Enhanced Graph based Ontology Matcher
Apr 19, 2014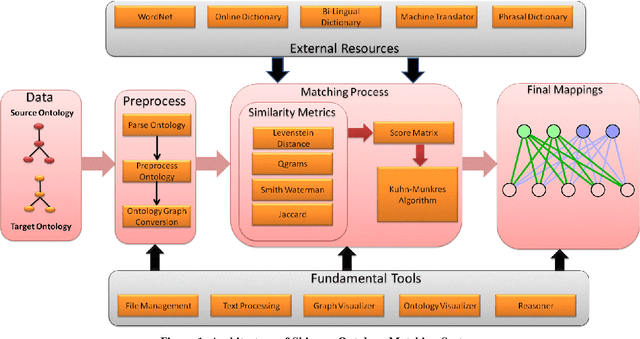
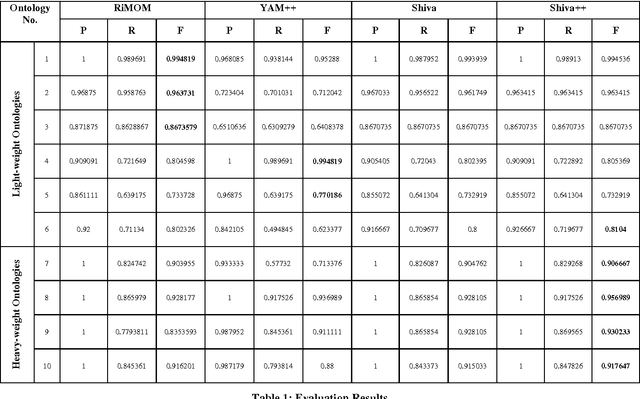
With the web getting bigger and assimilating knowledge about different concepts and domains, it is becoming very difficult for simple database driven applications to capture the data for a domain. Thus developers have come out with ontology based systems which can store large amount of information and can apply reasoning and produce timely information. Thus facilitating effective knowledge management. Though this approach has made our lives easier, but at the same time has given rise to another problem. Two different ontologies assimilating same knowledge tend to use different terms for the same concepts. This creates confusion among knowledge engineers and workers, as they do not know which is a better term then the other. Thus we need to merge ontologies working on same domain so that the engineers can develop a better application over it. This paper shows the development of one such matcher which merges the concepts available in two ontologies at two levels; 1) at string level and 2) at semantic level; thus producing better merged ontologies. We have used a graph matching technique which works at the core of the system. We have also evaluated the system and have tested its performance with its predecessor which works only on string matching. Thus current approach produces better results.
* arXiv admin note: text overlap with arXiv:1403.7465
Shiva: A Framework for Graph Based Ontology Matching
Mar 28, 2014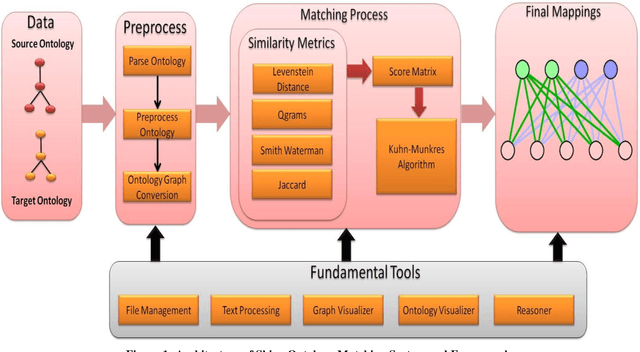
Since long, corporations are looking for knowledge sources which can provide structured description of data and can focus on meaning and shared understanding. Structures which can facilitate open world assumptions and can be flexible enough to incorporate and recognize more than one name for an entity. A source whose major purpose is to facilitate human communication and interoperability. Clearly, databases fail to provide these features and ontologies have emerged as an alternative choice, but corporations working on same domain tend to make different ontologies. The problem occurs when they want to share their data/knowledge. Thus we need tools to merge ontologies into one. This task is termed as ontology matching. This is an emerging area and still we have to go a long way in having an ideal matcher which can produce good results. In this paper we have shown a framework to matching ontologies using graphs.
Quality Estimation of English-Hindi Outputs using Naive Bayes Classifier
Dec 27, 2013



In this paper we present an approach for estimating the quality of machine translation system. There are various methods for estimating the quality of output sentences, but in this paper we focus on Na\"ive Bayes classifier to build model using features which are extracted from the input sentences. These features are used for finding the likelihood of each of the sentences of the training data which are then further used for determining the scores of the test data. On the basis of these scores we determine the class labels of the test data.
Automatic Ranking of MT Outputs using Approximations
Nov 22, 2013

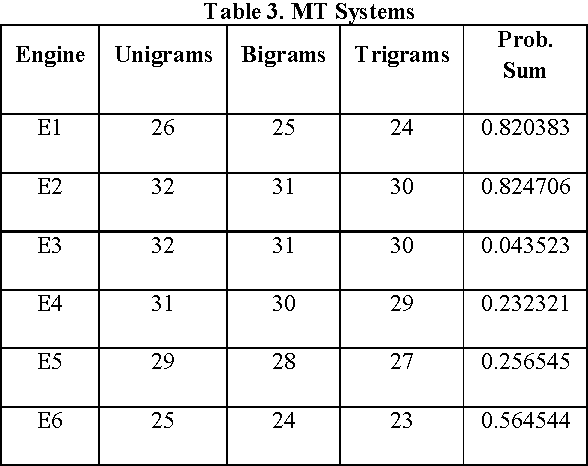
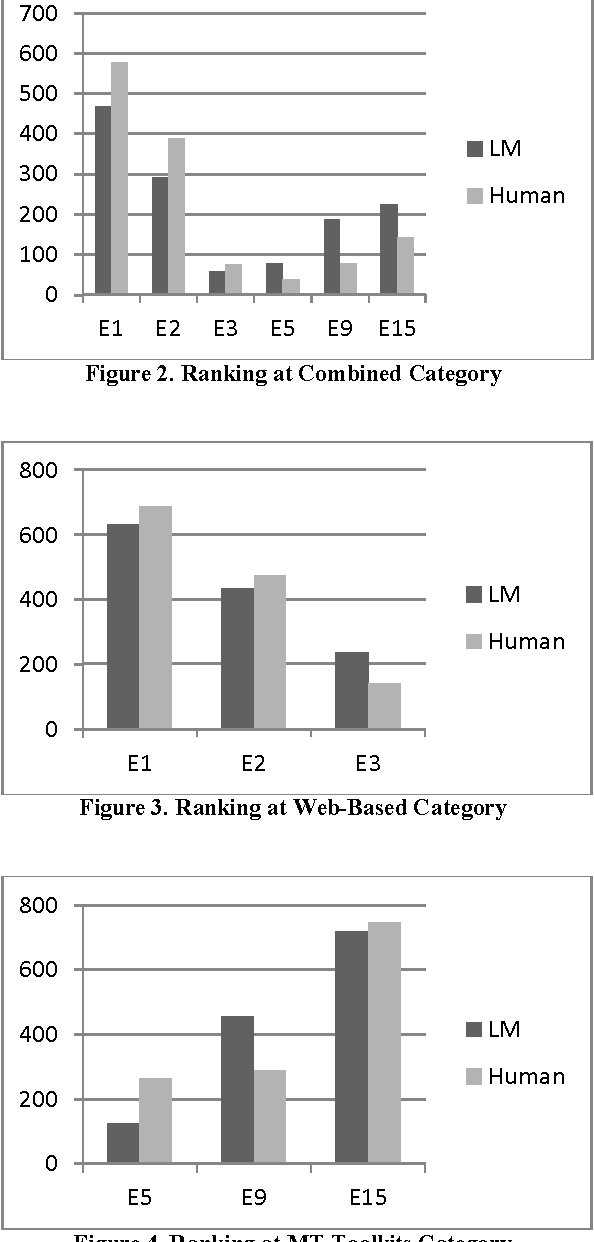
Since long, research on machine translation has been ongoing. Still, we do not get good translations from MT engines so developed. Manual ranking of these outputs tends to be very time consuming and expensive. Identifying which one is better or worse than the others is a very taxing task. In this paper, we show an approach which can provide automatic ranks to MT outputs (translations) taken from different MT Engines and which is based on N-gram approximations. We provide a solution where no human intervention is required for ranking systems. Further we also show the evaluations of our results which show equivalent results as that of human ranking.
HEVAL: Yet Another Human Evaluation Metric
Nov 15, 2013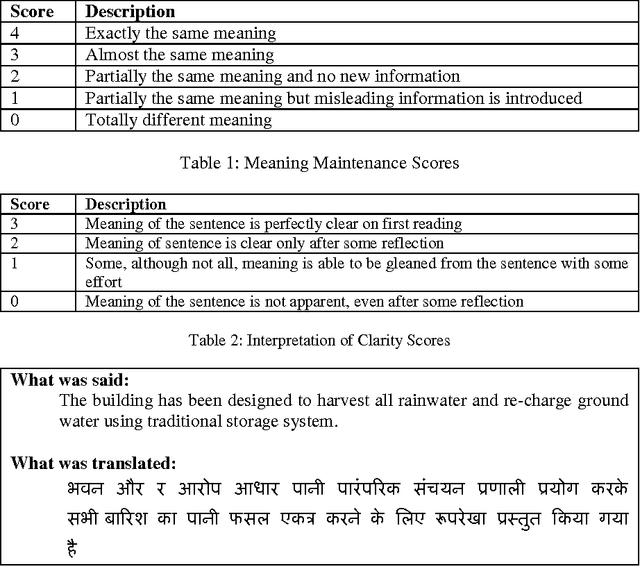
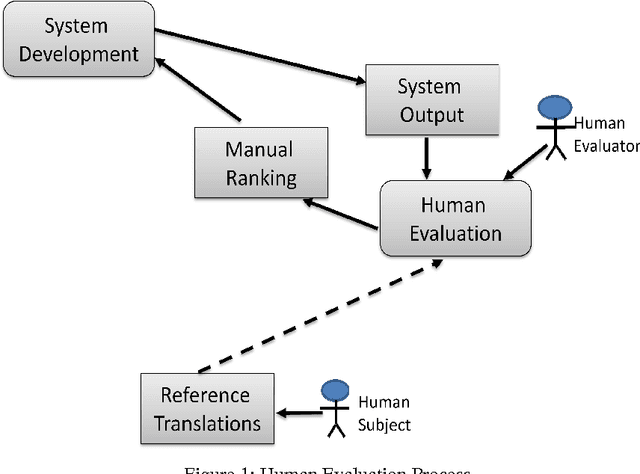
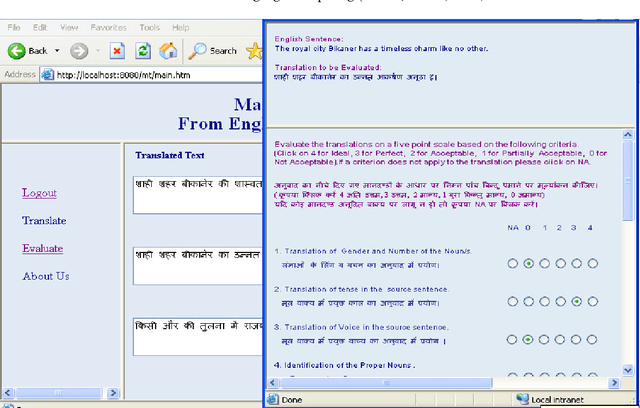
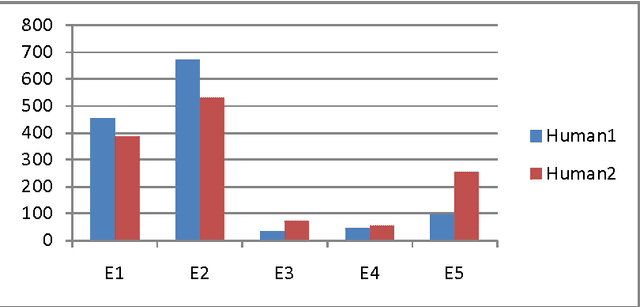
Machine translation evaluation is a very important activity in machine translation development. Automatic evaluation metrics proposed in literature are inadequate as they require one or more human reference translations to compare them with output produced by machine translation. This does not always give accurate results as a text can have several different translations. Human evaluation metrics, on the other hand, lacks inter-annotator agreement and repeatability. In this paper we have proposed a new human evaluation metric which addresses these issues. Moreover this metric also provides solid grounds for making sound assumptions on the quality of the text produced by a machine translation.
Development of Marathi Part of Speech Tagger Using Statistical Approach
Oct 09, 2013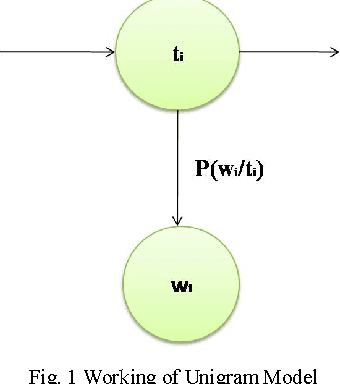



Part-of-speech (POS) tagging is a process of assigning the words in a text corresponding to a particular part of speech. A fundamental version of POS tagging is the identification of words as nouns, verbs, adjectives etc. For processing natural languages, Part of Speech tagging is a prominent tool. It is one of the simplest as well as most constant and statistical model for many NLP applications. POS Tagging is an initial stage of linguistics, text analysis like information retrieval, machine translator, text to speech synthesis, information extraction etc. In POS Tagging we assign a Part of Speech tag to each word in a sentence and literature. Various approaches have been proposed to implement POS taggers. In this paper we present a Marathi part of speech tagger. It is morphologically rich language. Marathi is spoken by the native people of Maharashtra. The general approach used for development of tagger is statistical using Unigram, Bigram, Trigram and HMM Methods. It presents a clear idea about all the algorithms with suitable examples. It also introduces a tag set for Marathi which can be used for tagging Marathi text. In this paper we have shown the development of the tagger as well as compared to check the accuracy of taggers output. The three Marathi POS taggers viz. Unigram, Bigram, Trigram and HMM gives the accuracy of 77.38%, 90.30%, 91.46% and 93.82% respectively.
Rule Based Stemmer in Urdu
Oct 02, 2013



Urdu is a combination of several languages like Arabic, Hindi, English, Turkish, Sanskrit etc. It has a complex and rich morphology. This is the reason why not much work has been done in Urdu language processing. Stemming is used to convert a word into its respective root form. In stemming, we separate the suffix and prefix from the word. It is useful in search engines, natural language processing and word processing, spell checkers, word parsing, word frequency and count studies. This paper presents a rule based stemmer for Urdu. The stemmer that we have discussed here is used in information retrieval. We have also evaluated our results by verifying it with a human expert.
Subjective and Objective Evaluation of English to Urdu Machine Translation
Oct 02, 2013



Machine translation is research based area where evaluation is very important phenomenon for checking the quality of MT output. The work is based on the evaluation of English to Urdu Machine translation. In this research work we have evaluated the translation quality of Urdu language which has been translated by using different Machine Translation systems like Google, Babylon and Ijunoon. The evaluation process is done by using two approaches - Human evaluation and Automatic evaluation. We have worked for both the approaches where in human evaluation emphasis is given to scales and parameters while in automatic evaluation emphasis is given to some automatic metric such as BLEU, GTM, METEOR and ATEC.