 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph based Question Answering System
Dec 05, 2018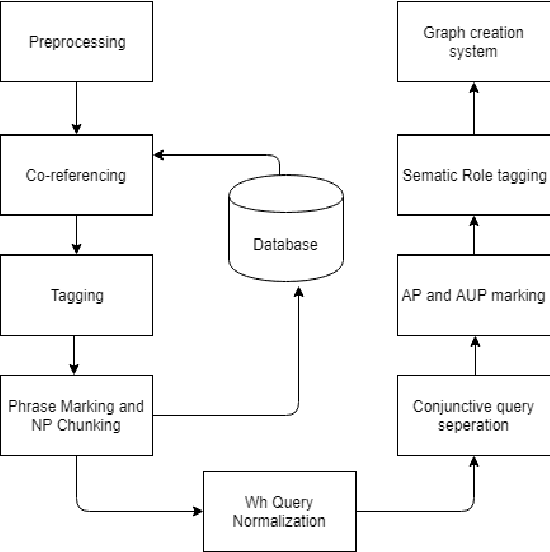
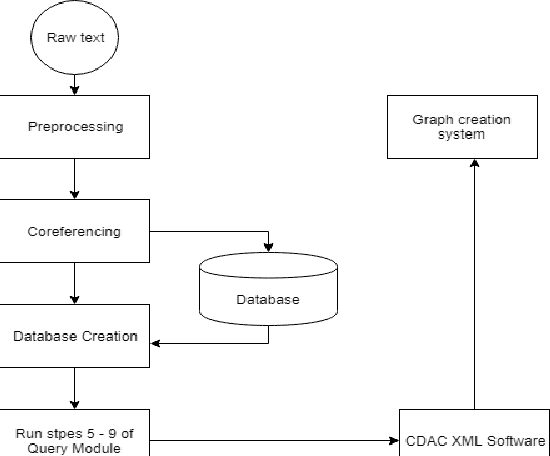
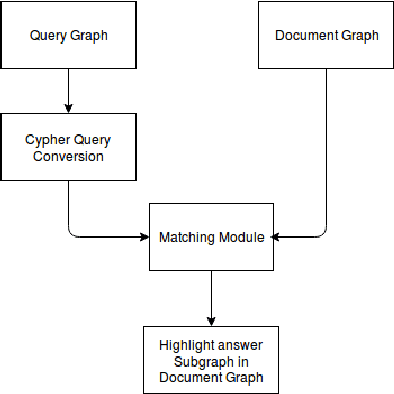
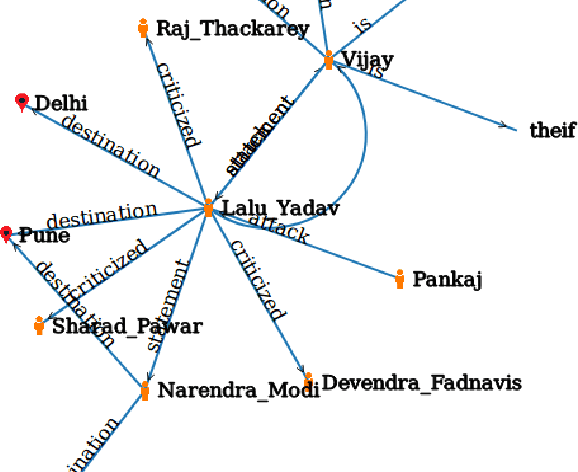
In today's digital age in the dawning era of big data analytics it is not the information but the linking of information through entities and actions which defines the discourse. Any textual data either available on the Internet off off-line (like newspaper data, Wikipedia dump, etc) is basically connect information which cannot be treated isolated for its wholesome semantics. There is a need for an automated retrieval process with proper information extraction to structure the data for relevant and fast text analytics. The first big challenge is the conversion of unstructured textual data to structured data. Unlike other databases, graph databases handle relationships and connections elegantly. Our project aims at developing a graph-based information extraction and retrieval system.
Hindi to English Transfer Based Machine Translation System
Jul 08, 2015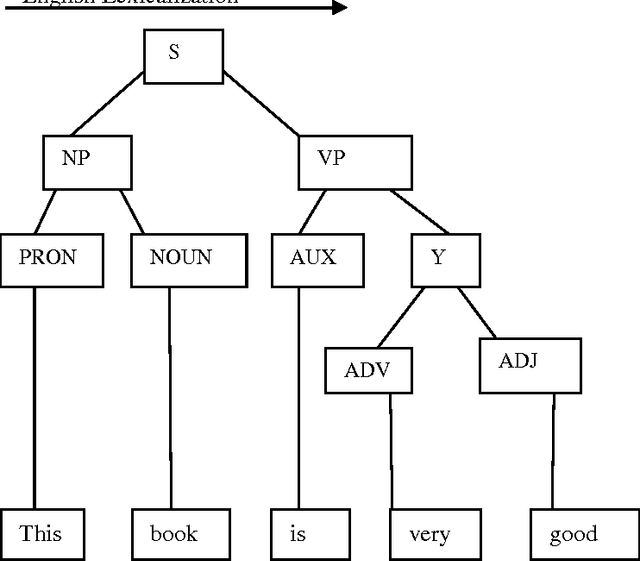

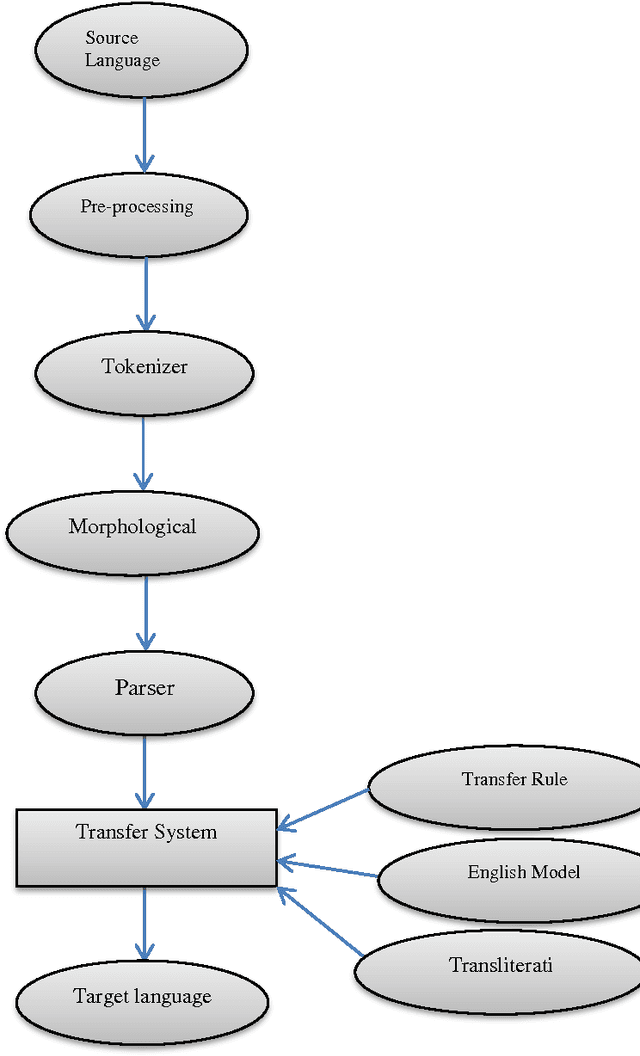
In large societies like India there is a huge demand to convert one human language into another. Lots of work has been done in this area. Many transfer based MTS have developed for English to other languages, as MANTRA CDAC Pune, MATRA CDAC Pune, SHAKTI IISc Bangalore and IIIT Hyderabad. Still there is a little work done for Hindi to other languages. Currently we are working on it. In this paper we focus on designing a system, that translate the document from Hindi to English by using transfer based approach. This system takes an input text check its structure through parsing. Reordering rules are used to generate the text in target language. It is better than Corpus Based MTS because Corpus Based MTS require large amount of word aligned data for translation that is not available for many languages while Transfer Based MTS requires only knowledge of both the languages(source language and target language) to make transfer rules. We get correct translation for simple assertive sentences and almost correct for complex and compound sentences.
Shiva++: An Enhanced Graph based Ontology Matcher
Apr 19, 2014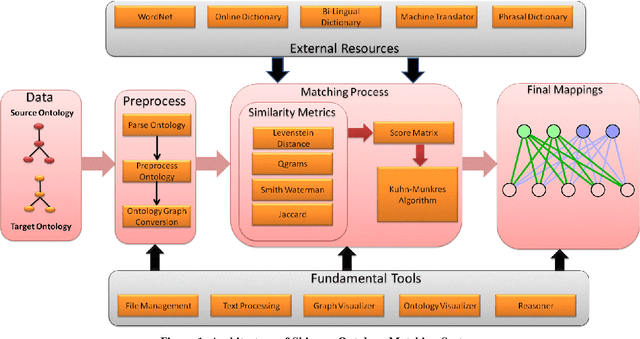
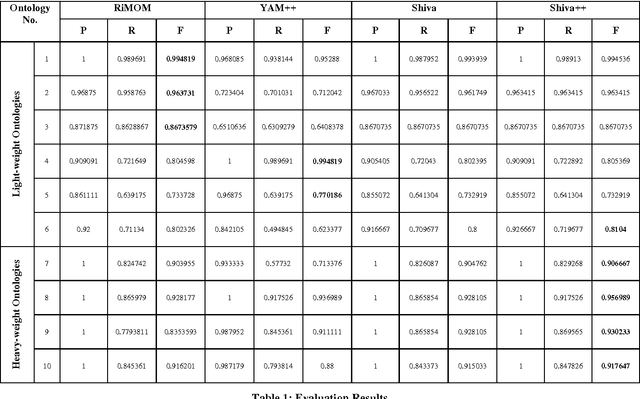
With the web getting bigger and assimilating knowledge about different concepts and domains, it is becoming very difficult for simple database driven applications to capture the data for a domain. Thus developers have come out with ontology based systems which can store large amount of information and can apply reasoning and produce timely information. Thus facilitating effective knowledge management. Though this approach has made our lives easier, but at the same time has given rise to another problem. Two different ontologies assimilating same knowledge tend to use different terms for the same concepts. This creates confusion among knowledge engineers and workers, as they do not know which is a better term then the other. Thus we need to merge ontologies working on same domain so that the engineers can develop a better application over it. This paper shows the development of one such matcher which merges the concepts available in two ontologies at two levels; 1) at string level and 2) at semantic level; thus producing better merged ontologies. We have used a graph matching technique which works at the core of the system. We have also evaluated the system and have tested its performance with its predecessor which works only on string matching. Thus current approach produces better results.
* arXiv admin note: text overlap with arXiv:1403.7465
Assessing the Quality of MT Systems for Hindi to English Translation
Apr 15, 2014

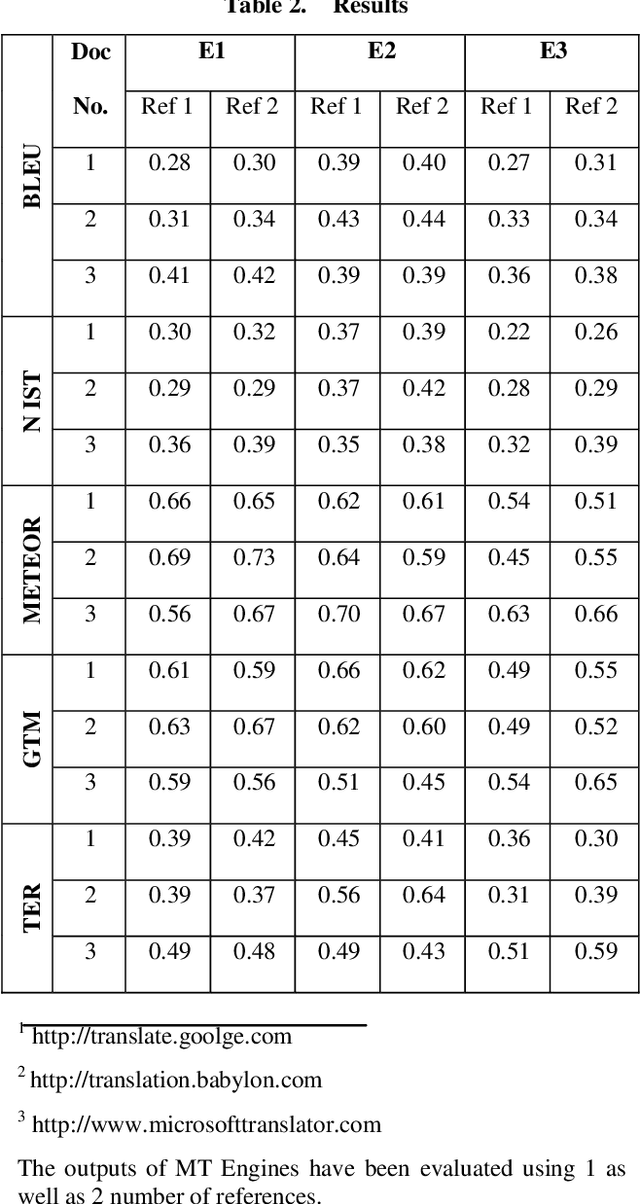
Evaluation plays a vital role in checking the quality of MT output. It is done either manually or automatically. Manual evaluation is very time consuming and subjective, hence use of automatic metrics is done most of the times. This paper evaluates the translation quality of different MT Engines for Hindi-English (Hindi data is provided as input and English is obtained as output) using various automatic metrics like BLEU, METEOR etc. Further the comparison automatic evaluation results with Human ranking have also been given.
Evaluation and Ranking of Machine Translated Output in Hindi Language using Precision and Recall Oriented Metrics
Apr 07, 2014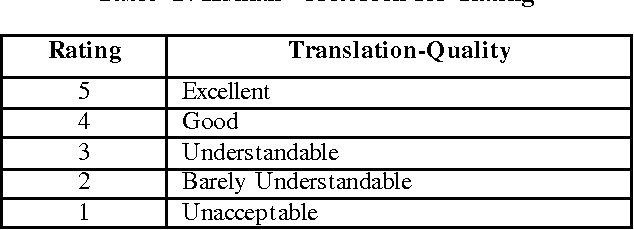
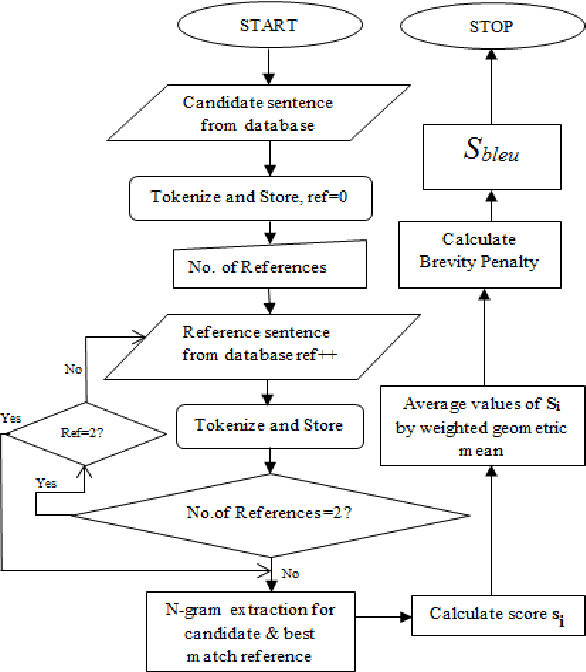
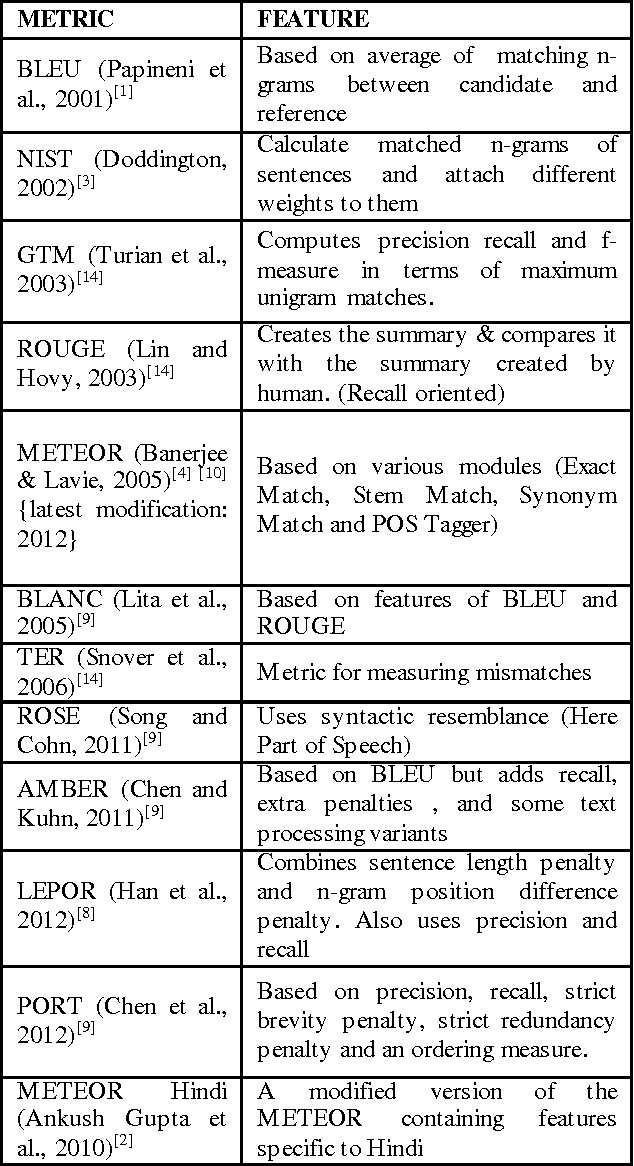
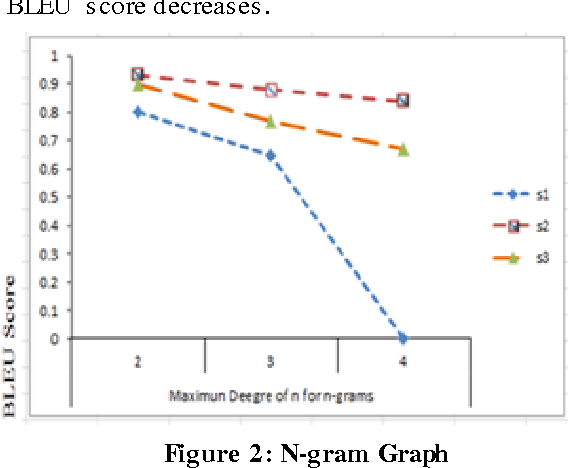
Evaluation plays a crucial role in development of Machine translation systems. In order to judge the quality of an existing MT system i.e. if the translated output is of human translation quality or not, various automatic metrics exist. We here present the implementation results of different metrics when used on Hindi language along with their comparisons, illustrating how effective are these metrics on languages like Hindi (free word order language).
Shiva: A Framework for Graph Based Ontology Matching
Mar 28, 2014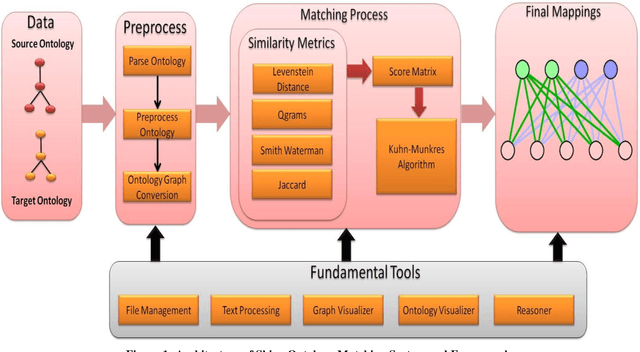
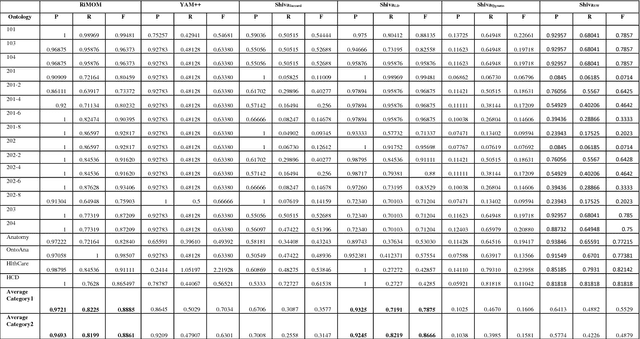
Since long, corporations are looking for knowledge sources which can provide structured description of data and can focus on meaning and shared understanding. Structures which can facilitate open world assumptions and can be flexible enough to incorporate and recognize more than one name for an entity. A source whose major purpose is to facilitate human communication and interoperability. Clearly, databases fail to provide these features and ontologies have emerged as an alternative choice, but corporations working on same domain tend to make different ontologies. The problem occurs when they want to share their data/knowledge. Thus we need tools to merge ontologies into one. This task is termed as ontology matching. This is an emerging area and still we have to go a long way in having an ideal matcher which can produce good results. In this paper we have shown a framework to matching ontologies using graphs.
HEVAL: Yet Another Human Evaluation Metric
Nov 15, 2013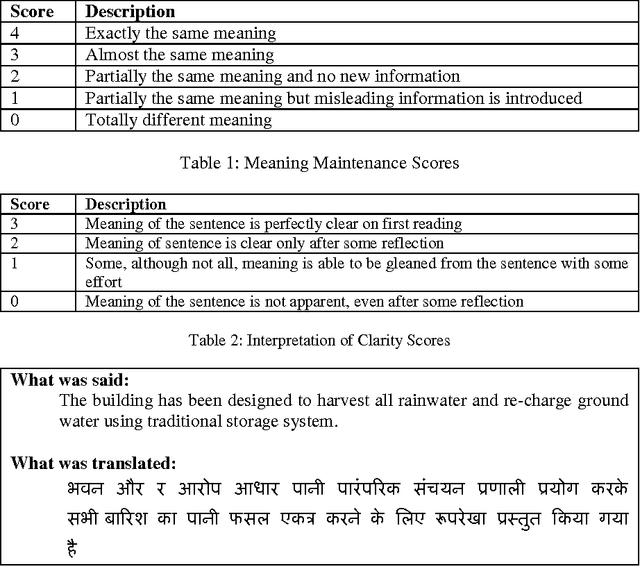
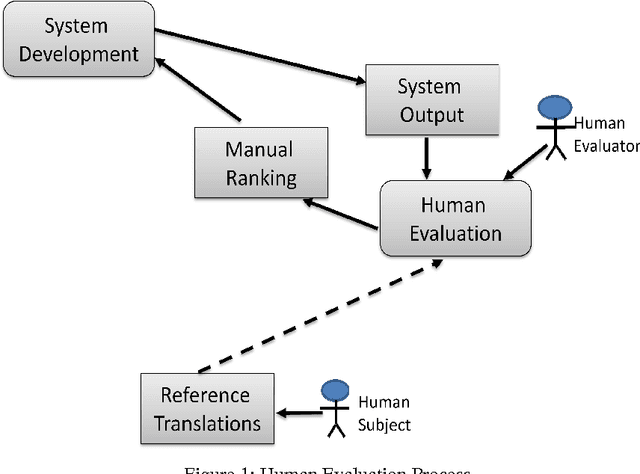
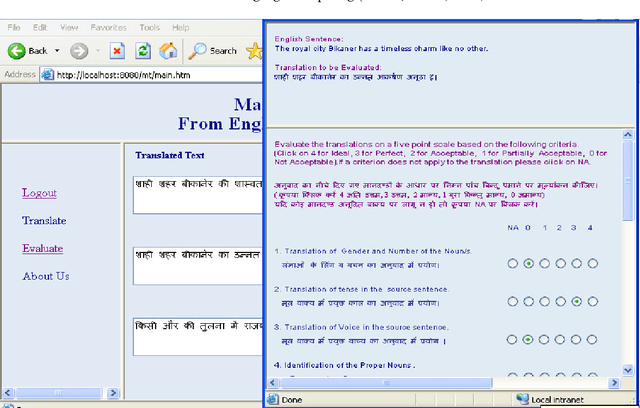
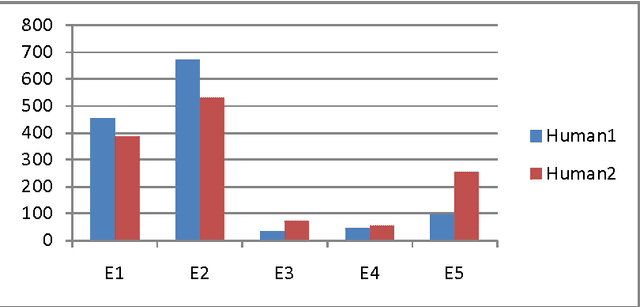
Machine translation evaluation is a very important activity in machine translation development. Automatic evaluation metrics proposed in literature are inadequate as they require one or more human reference translations to compare them with output produced by machine translation. This does not always give accurate results as a text can have several different translations. Human evaluation metrics, on the other hand, lacks inter-annotator agreement and repeatability. In this paper we have proposed a new human evaluation metric which addresses these issues. Moreover this metric also provides solid grounds for making sound assumptions on the quality of the text produced by a machine translation.