 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph based Question Answering System
Paper and Code
Dec 05, 2018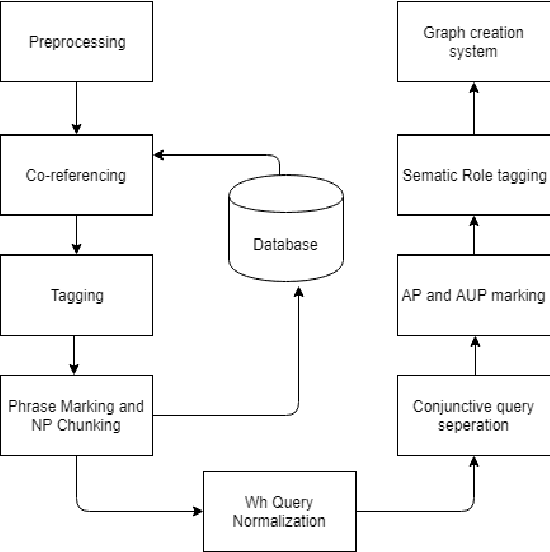
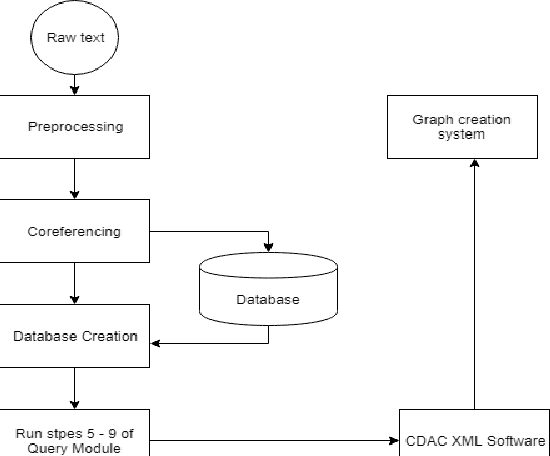
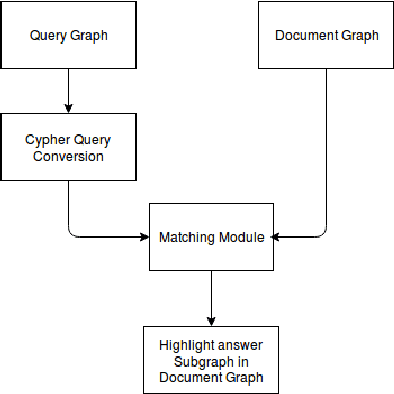
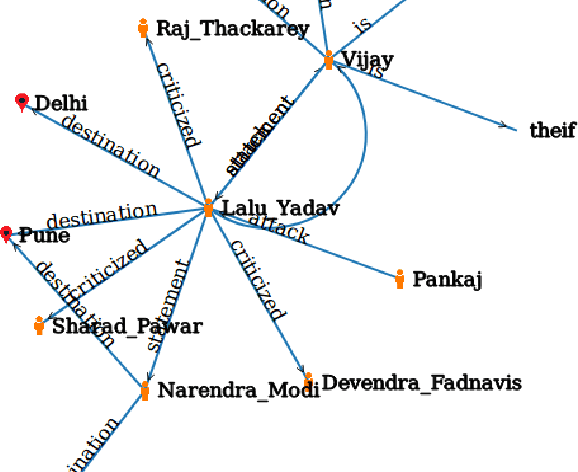
In today's digital age in the dawning era of big data analytics it is not the information but the linking of information through entities and actions which defines the discourse. Any textual data either available on the Internet off off-line (like newspaper data, Wikipedia dump, etc) is basically connect information which cannot be treated isolated for its wholesome semantics. There is a need for an automated retrieval process with proper information extraction to structure the data for relevant and fast text analytics. The first big challenge is the conversion of unstructured textual data to structured data. Unlike other databases, graph databases handle relationships and connections elegantly. Our project aims at developing a graph-based information extraction and retrieval system.