 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplications of Deep Circuits in Improving Quality of Quantum Question Answering
May 12, 2023Question Answering (QA) has proved to be an arduous challenge in the area of natural language processing (NLP) and artificial intelligence (AI). Many attempts have been made to develop complete solutions for QA as well as improving significant sub-modules of the QA systems to improve the overall performance through the course of time. Questions are the most important piece of QA, because knowing the question is equivalent to knowing what counts as an answer (Harrah in Philos Sci, 1961 [1]). In this work, we have attempted to understand questions in a better way by using Quantum Machine Learning (QML). The properties of Quantum Computing (QC) have enabled classically intractable data processing. So, in this paper, we have performed question classification on questions from two classes of SelQA (Selection-based Question Answering) dataset using quantum-based classifier algorithms-quantum support vector machine (QSVM) and variational quantum classifier (VQC) from Qiskit (Quantum Information Science toolKIT) for Python. We perform classification with both classifiers in almost similar environments and study the effects of circuit depths while comparing the results of both classifiers. We also use these classification results with our own rule-based QA system and observe significant performance improvement. Hence, this experiment has helped in improving the quality of QA in general.
Improving the Quality of Neural Machine Translation Through Proper Translation of Name Entities
May 12, 2023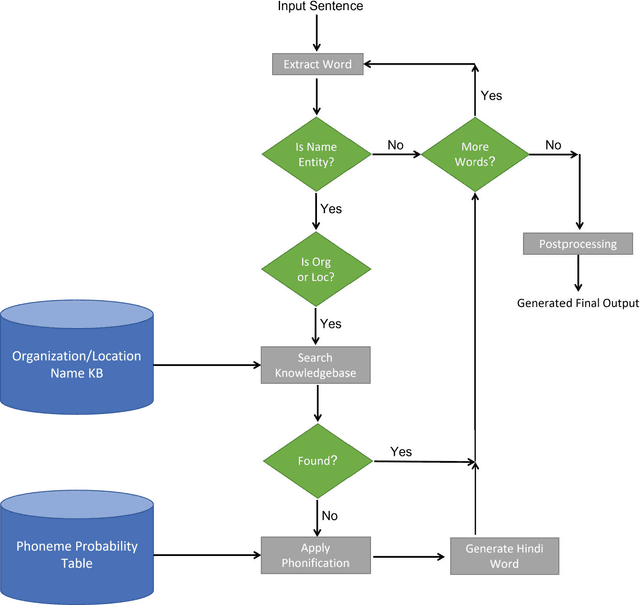
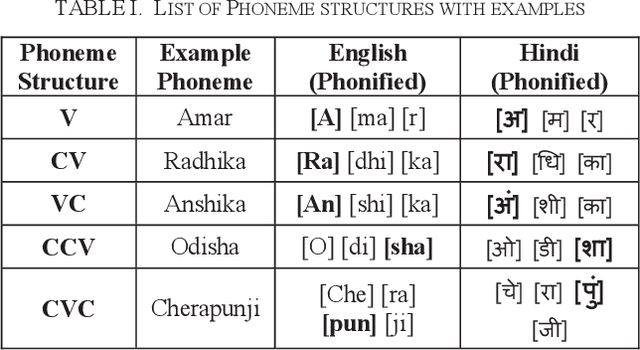
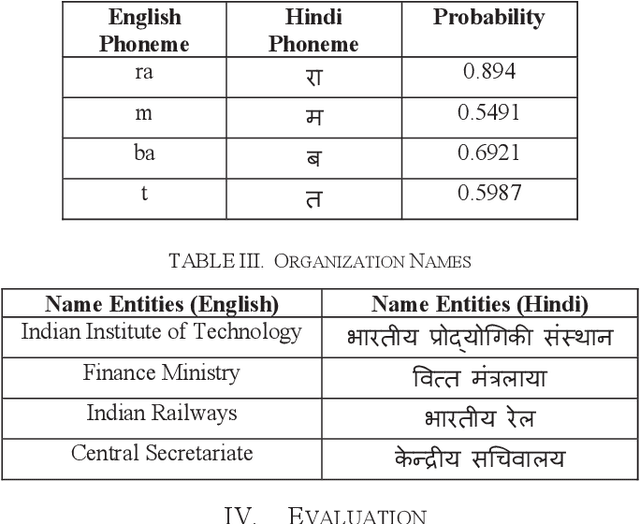
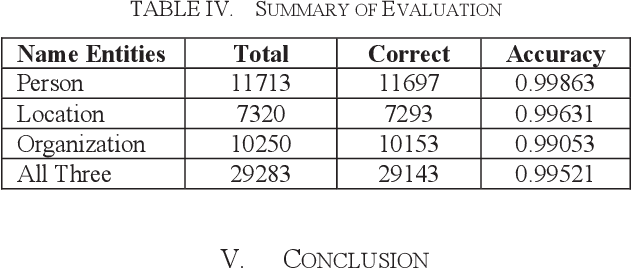
In this paper, we have shown a method of improving the quality of neural machine translation by translating/transliterating name entities as a preprocessing step. Through experiments we have shown the performance gain of our system. For evaluation we considered three types of name entities viz person names, location names and organization names. The system was able to correctly translate mostly all the name entities. For person names the accuracy was 99.86%, for location names the accuracy was 99.63% and for organization names the accuracy was 99.05%. Overall, the accuracy of the system was 99.52%
Towards Transliteration between Sindhi Scripts from Devanagari to Perso-Arabic
May 12, 2023



In this paper, we have shown a script conversion (transliteration) technique that converts Sindhi text in the Devanagari script to the Perso-Arabic script. We showed this by incorporating a hybrid approach where some part of the text is converted using a rule base and in case an ambiguity arises then a probabilistic model is used to resolve the same. Using this approach, the system achieved an overall accuracy of 99.64%.
A Model for Translation of Text from Indian Languages to Bharti Braille Characters
May 05, 2023People who are visually impaired face a lot of difficulties while studying. One of the major causes to this is lack of available text in Bharti Braille script. In this paper, we have suggested a scheme to convert text in major Indian languages into Bharti Braille. The system uses a hybrid approach where at first the text in Indian language is given to a rule based system and in case if there is any ambiguity then it is resolved by applying a LSTM based model. The developed model has also been tested and found to have produced near accurate results.
Implications of Multi-Word Expressions on English to Bharti Braille Machine Translation
May 05, 2023In this paper, we have shown the improvement of English to Bharti Braille machine translation system. We have shown how we can improve a baseline NMT model by adding some linguistic knowledge to it. This was done for five language pairs where English sentences were translated into five Indian languages and then subsequently to corresponding Bharti Braille. This has been demonstrated by adding a sub-module for translating multi-word expressions. The approach shows promising results as across language pairs, we could see improvement in the quality of NMT outputs. The least improvement was observed in English-Nepali language pair with 22.08% and the most improvement was observed in the English-Hindi language pair with 23.30%.
Evaluating the Performance of Some Local Optimizers for Variational Quantum Classifiers
Feb 17, 2021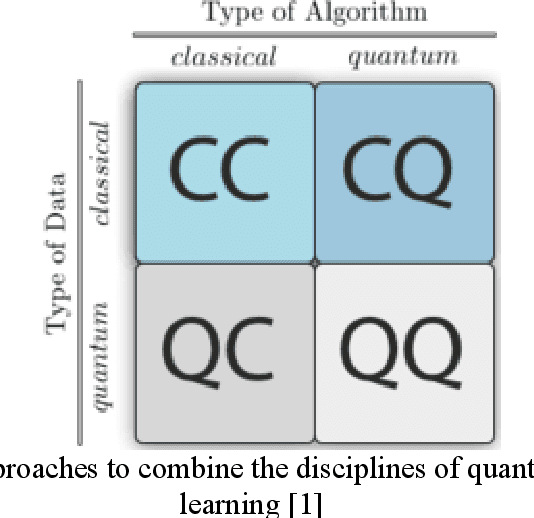
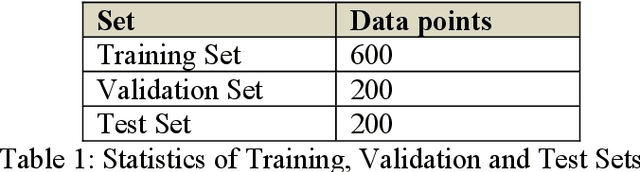
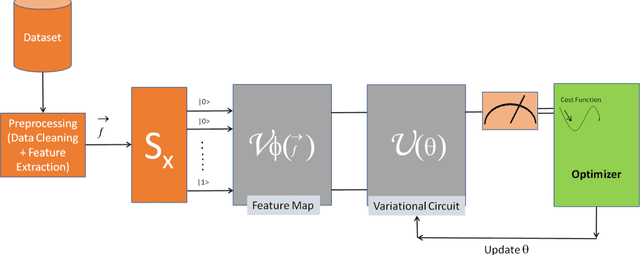
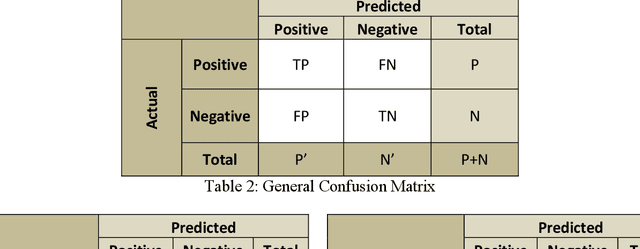
In this paper, we have studied the performance and role of local optimizers in quantum variational circuits. We studied the performance of the two most popular optimizers and compared their results with some popular classical machine learning algorithms. The classical algorithms we used in our study are support vector machine (SVM), gradient boosting (GB), and random forest (RF). These were compared with a variational quantum classifier (VQC) using two sets of local optimizers viz AQGD and COBYLA. For experimenting with VQC, IBM Quantum Experience and IBM Qiskit was used while for classical machine learning models, sci-kit learn was used. The results show that machine learning on noisy immediate scale quantum machines can produce comparable results as on classical machines. For our experiments, we have used a popular restaurant sentiment analysis dataset. The extracted features from this dataset and then after applying PCA reduced the feature set into 5 features. Quantum ML models were trained using 100 epochs and 150 epochs on using EfficientSU2 variational circuit. Overall, four Quantum ML models were trained and three Classical ML models were trained. The performance of the trained models was evaluated using standard evaluation measures viz, Accuracy, Precision, Recall, F-Score. In all the cases AQGD optimizer-based model with 100 Epochs performed better than all other models. It produced an accuracy of 77% and an F-Score of 0.785 which were highest across all the trained models.
Classifier-Based Text Simplification for Improved Machine Translation
Jul 12, 2015



Machine Translation is one of the research fields of Computational Linguistics. The objective of many MT Researchers is to develop an MT System that produce good quality and high accuracy output translations and which also covers maximum language pairs. As internet and Globalization is increasing day by day, we need a way that improves the quality of translation. For this reason, we have developed a Classifier based Text Simplification Model for English-Hindi Machine Translation Systems. We have used support vector machines and Na\"ive Bayes Classifier to develop this model. We have also evaluated the performance of these classifiers.
Quality Estimation Of Machine Translation Outputs Through Stemming
Jul 10, 2014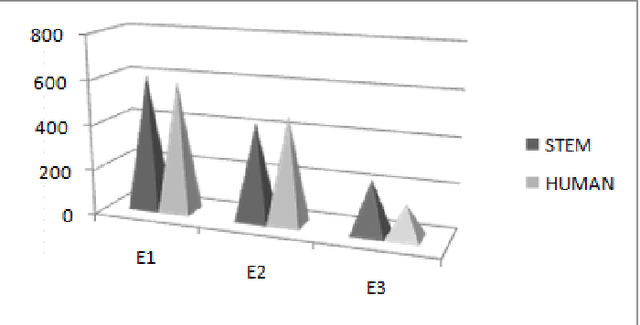
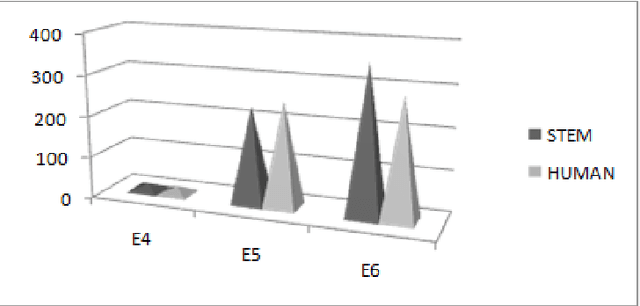

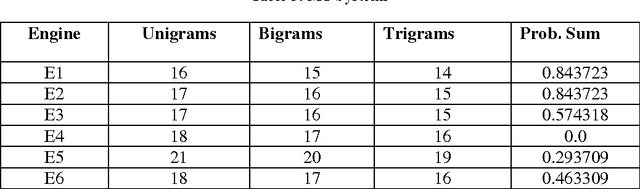
Machine Translation is the challenging problem for Indian languages. Every day we can see some machine translators being developed, but getting a high quality automatic translation is still a very distant dream . The correct translated sentence for Hindi language is rarely found. In this paper, we are emphasizing on English-Hindi language pair, so in order to preserve the correct MT output we present a ranking system, which employs some machine learning techniques and morphological features. In ranking no human intervention is required. We have also validated our results by comparing it with human ranking.
Shiva++: An Enhanced Graph based Ontology Matcher
Apr 19, 2014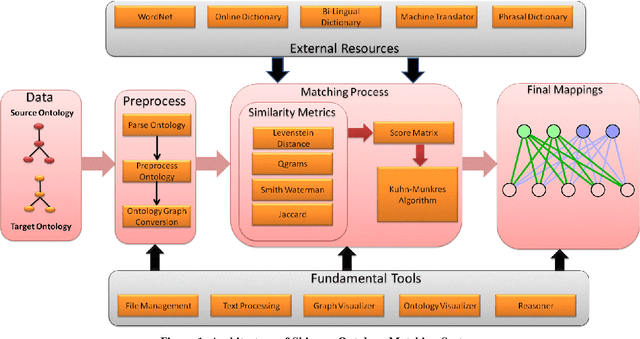
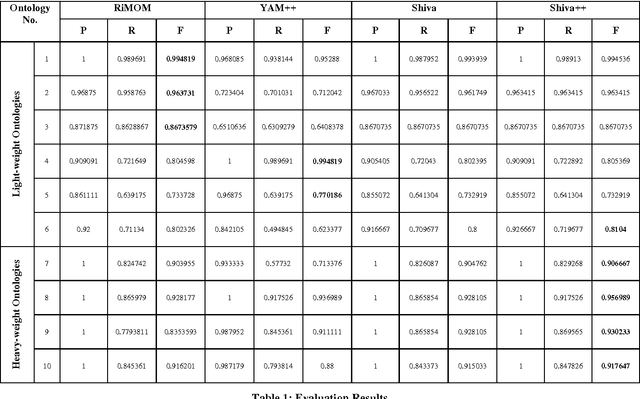
With the web getting bigger and assimilating knowledge about different concepts and domains, it is becoming very difficult for simple database driven applications to capture the data for a domain. Thus developers have come out with ontology based systems which can store large amount of information and can apply reasoning and produce timely information. Thus facilitating effective knowledge management. Though this approach has made our lives easier, but at the same time has given rise to another problem. Two different ontologies assimilating same knowledge tend to use different terms for the same concepts. This creates confusion among knowledge engineers and workers, as they do not know which is a better term then the other. Thus we need to merge ontologies working on same domain so that the engineers can develop a better application over it. This paper shows the development of one such matcher which merges the concepts available in two ontologies at two levels; 1) at string level and 2) at semantic level; thus producing better merged ontologies. We have used a graph matching technique which works at the core of the system. We have also evaluated the system and have tested its performance with its predecessor which works only on string matching. Thus current approach produces better results.
* arXiv admin note: text overlap with arXiv:1403.7465
Shiva: A Framework for Graph Based Ontology Matching
Mar 28, 2014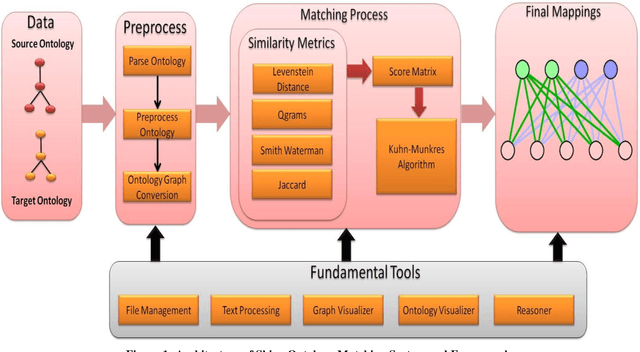
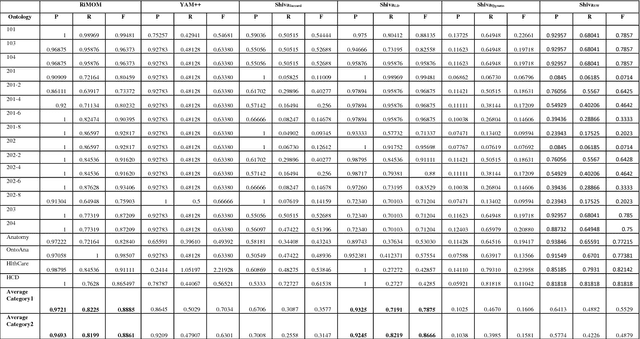
Since long, corporations are looking for knowledge sources which can provide structured description of data and can focus on meaning and shared understanding. Structures which can facilitate open world assumptions and can be flexible enough to incorporate and recognize more than one name for an entity. A source whose major purpose is to facilitate human communication and interoperability. Clearly, databases fail to provide these features and ontologies have emerged as an alternative choice, but corporations working on same domain tend to make different ontologies. The problem occurs when they want to share their data/knowledge. Thus we need tools to merge ontologies into one. This task is termed as ontology matching. This is an emerging area and still we have to go a long way in having an ideal matcher which can produce good results. In this paper we have shown a framework to matching ontologies using graphs.