 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment of Marathi Part of Speech Tagger Using Statistical Approach
Oct 09, 2013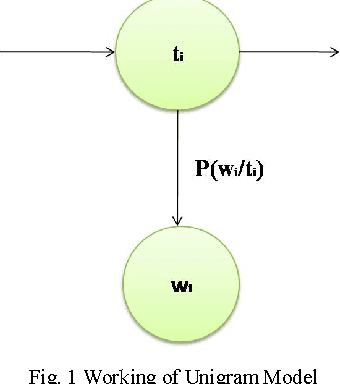



Part-of-speech (POS) tagging is a process of assigning the words in a text corresponding to a particular part of speech. A fundamental version of POS tagging is the identification of words as nouns, verbs, adjectives etc. For processing natural languages, Part of Speech tagging is a prominent tool. It is one of the simplest as well as most constant and statistical model for many NLP applications. POS Tagging is an initial stage of linguistics, text analysis like information retrieval, machine translator, text to speech synthesis, information extraction etc. In POS Tagging we assign a Part of Speech tag to each word in a sentence and literature. Various approaches have been proposed to implement POS taggers. In this paper we present a Marathi part of speech tagger. It is morphologically rich language. Marathi is spoken by the native people of Maharashtra. The general approach used for development of tagger is statistical using Unigram, Bigram, Trigram and HMM Methods. It presents a clear idea about all the algorithms with suitable examples. It also introduces a tag set for Marathi which can be used for tagging Marathi text. In this paper we have shown the development of the tagger as well as compared to check the accuracy of taggers output. The three Marathi POS taggers viz. Unigram, Bigram, Trigram and HMM gives the accuracy of 77.38%, 90.30%, 91.46% and 93.82% respectively.
Part of Speech Tagging of Marathi Text Using Trigram Method
Jul 15, 2013

In this paper we present a Marathi part of speech tagger. It is a morphologically rich language. It is spoken by the native people of Maharashtra. The general approach used for development of tagger is statistical using trigram Method. The main concept of trigram is to explore the most likely POS for a token based on given information of previous two tags by calculating probabilities to determine which is the best sequence of a tag. In this paper we show the development of the tagger. Moreover we have also shown the evaluation done.