 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Representations on the Unit Sphere: Application to Online Continual Learning
Paper and Code
Jun 06, 2023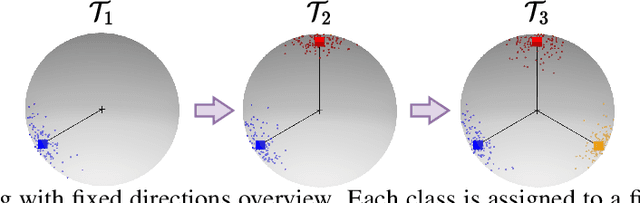
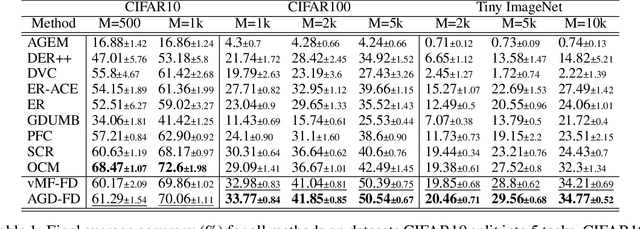
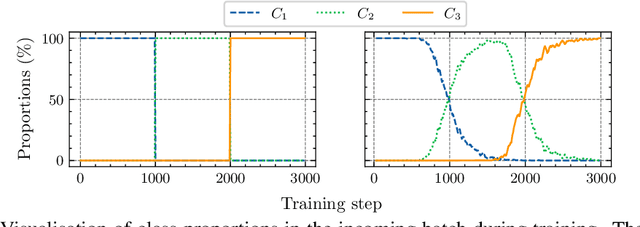
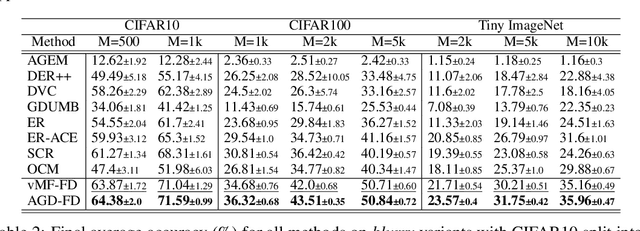
We use the maximum a posteriori estimation principle for learning representations distributed on the unit sphere. We derive loss functions for the von Mises-Fisher distribution and the angular Gaussian distribution, both designed for modeling symmetric directional data. A noteworthy feature of our approach is that the learned representations are pushed toward fixed directions, allowing for a learning strategy that is resilient to data drift. This makes it suitable for online continual learning, which is the problem of training neural networks on a continuous data stream, where multiple classification tasks are presented sequentially so that data from past tasks are no longer accessible, and data from the current task can be seen only once. To address this challenging scenario, we propose a memory-based representation learning technique equipped with our new loss functions. Our approach does not require negative data or knowledge of task boundaries and performs well with smaller batch sizes while being computationally efficient. We demonstrate with extensive experiments that the proposed method outperforms the current state-of-the-art methods on both standard evaluation scenarios and realistic scenarios with blurry task boundaries. For reproducibility, we use the same training pipeline for every compared method and share the code at https://t.ly/SQTj.