 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Compression using only Attention based Neural Networks
Oct 17, 2023In recent research, Learned Image Compression has gained prominence for its capacity to outperform traditional handcrafted pipelines, especially at low bit-rates. While existing methods incorporate convolutional priors with occasional attention blocks to address long-range dependencies, recent advances in computer vision advocate for a transformative shift towards fully transformer-based architectures grounded in the attention mechanism. This paper investigates the feasibility of image compression exclusively using attention layers within our novel model, QPressFormer. We introduce the concept of learned image queries to aggregate patch information via cross-attention, followed by quantization and coding techniques. Through extensive evaluations, our work demonstrates competitive performance achieved by convolution-free architectures across the popular Kodak, DIV2K, and CLIC datasets.
Domain-Aware Augmentations for Unsupervised Online General Continual Learning
Sep 13, 2023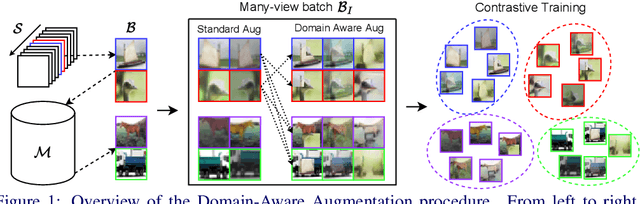
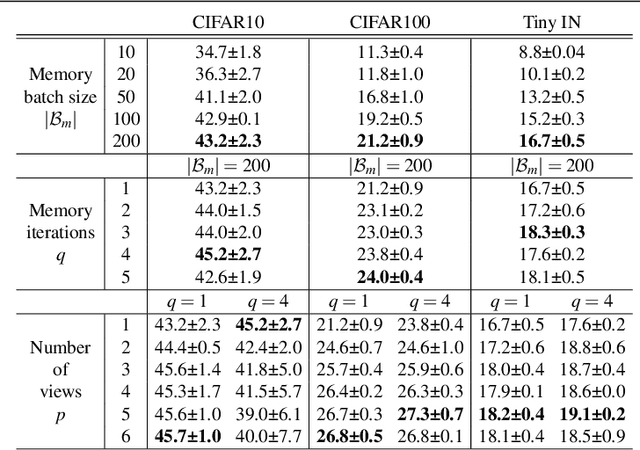
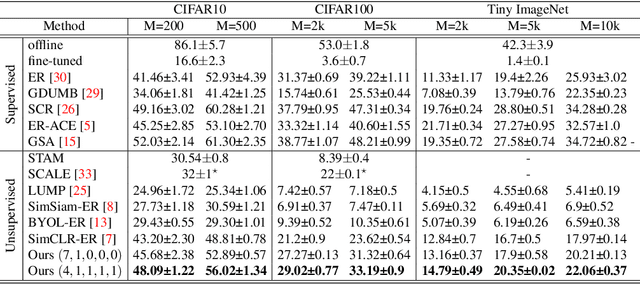
Continual Learning has been challenging, especially when dealing with unsupervised scenarios such as Unsupervised Online General Continual Learning (UOGCL), where the learning agent has no prior knowledge of class boundaries or task change information. While previous research has focused on reducing forgetting in supervised setups, recent studies have shown that self-supervised learners are more resilient to forgetting. This paper proposes a novel approach that enhances memory usage for contrastive learning in UOGCL by defining and using stream-dependent data augmentations together with some implementation tricks. Our proposed method is simple yet effective, achieves state-of-the-art results compared to other unsupervised approaches in all considered setups, and reduces the gap between supervised and unsupervised continual learning. Our domain-aware augmentation procedure can be adapted to other replay-based methods, making it a promising strategy for continual learning.
New metrics for analyzing continual learners
Sep 01, 2023
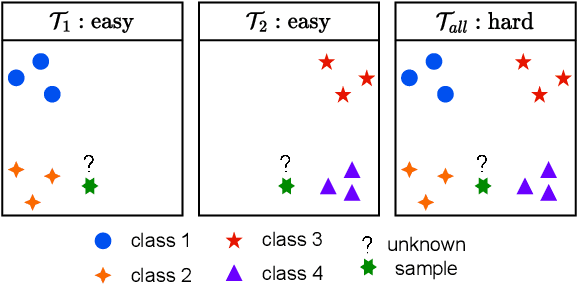
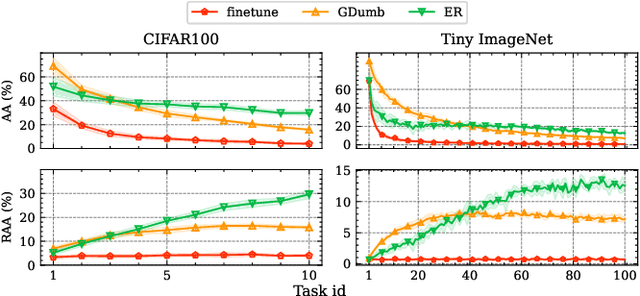
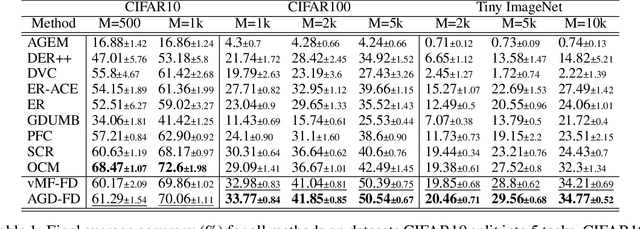
Deep neural networks have shown remarkable performance when trained on independent and identically distributed data from a fixed set of classes. However, in real-world scenarios, it can be desirable to train models on a continuous stream of data where multiple classification tasks are presented sequentially. This scenario, known as Continual Learning (CL) poses challenges to standard learning algorithms which struggle to maintain knowledge of old tasks while learning new ones. This stability-plasticity dilemma remains central to CL and multiple metrics have been proposed to adequately measure stability and plasticity separately. However, none considers the increasing difficulty of the classification task, which inherently results in performance loss for any model. In that sense, we analyze some limitations of current metrics and identify the presence of setup-induced forgetting. Therefore, we propose new metrics that account for the task's increasing difficulty. Through experiments on benchmark datasets, we demonstrate that our proposed metrics can provide new insights into the stability-plasticity trade-off achieved by models in the continual learning environment.
Learning Representations on the Unit Sphere: Application to Online Continual Learning
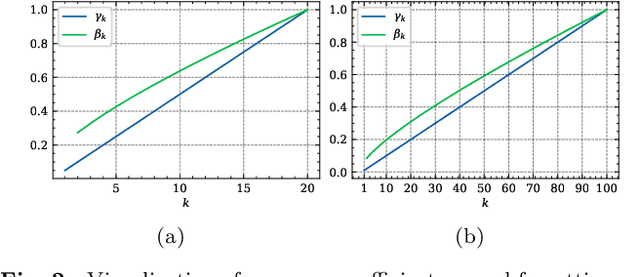
Jun 06, 2023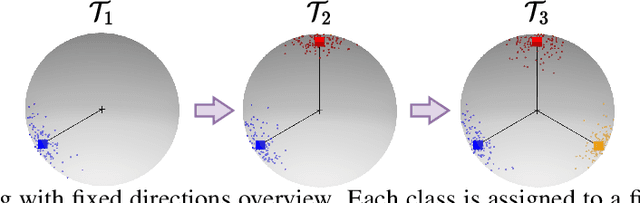
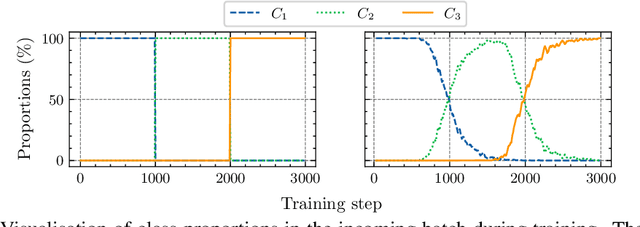
We use the maximum a posteriori estimation principle for learning representations distributed on the unit sphere. We derive loss functions for the von Mises-Fisher distribution and the angular Gaussian distribution, both designed for modeling symmetric directional data. A noteworthy feature of our approach is that the learned representations are pushed toward fixed directions, allowing for a learning strategy that is resilient to data drift. This makes it suitable for online continual learning, which is the problem of training neural networks on a continuous data stream, where multiple classification tasks are presented sequentially so that data from past tasks are no longer accessible, and data from the current task can be seen only once. To address this challenging scenario, we propose a memory-based representation learning technique equipped with our new loss functions. Our approach does not require negative data or knowledge of task boundaries and performs well with smaller batch sizes while being computationally efficient. We demonstrate with extensive experiments that the proposed method outperforms the current state-of-the-art methods on both standard evaluation scenarios and realistic scenarios with blurry task boundaries. For reproducibility, we use the same training pipeline for every compared method and share the code at https://t.ly/SQTj.
Contrastive Learning for Online Semi-Supervised General Continual Learning
Jul 12, 2022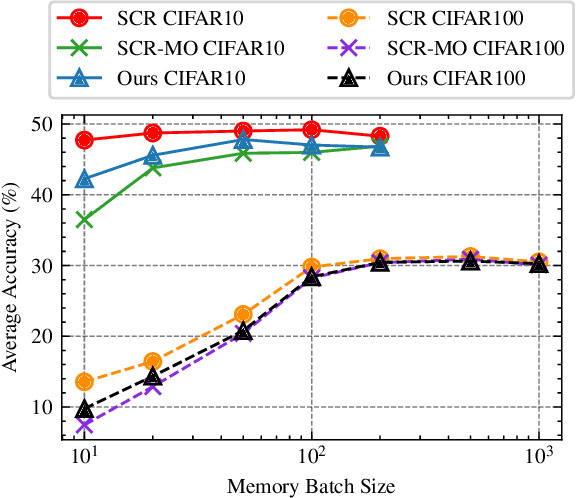

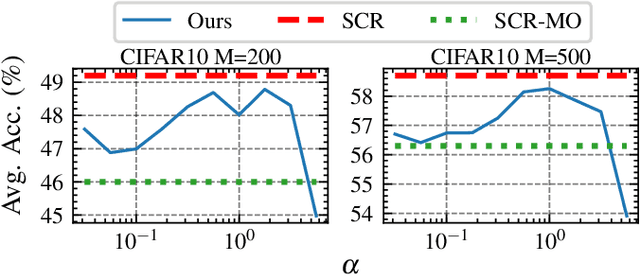
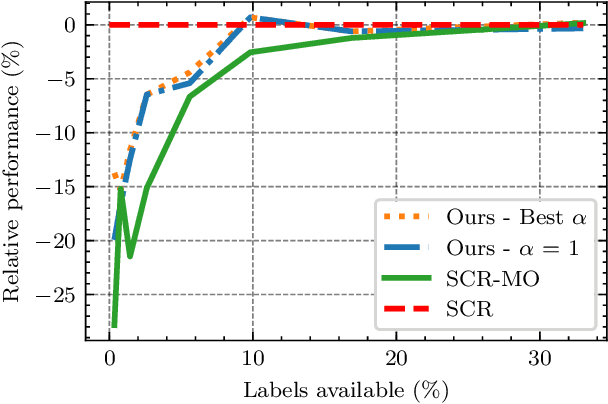
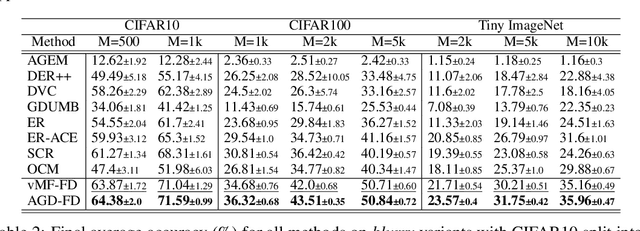
We study Online Continual Learning with missing labels and propose SemiCon, a new contrastive loss designed for partly labeled data. We demonstrate its efficiency by devising a memory-based method trained on an unlabeled data stream, where every data added to memory is labeled using an oracle. Our approach outperforms existing semi-supervised methods when few labels are available, and obtain similar results to state-of-the-art supervised methods while using only 2.6% of labels on Split-CIFAR10 and 10% of labels on Split-CIFAR100.
Online convex optimization and no-regret learning: Algorithms, guarantees and applications
Apr 12, 2018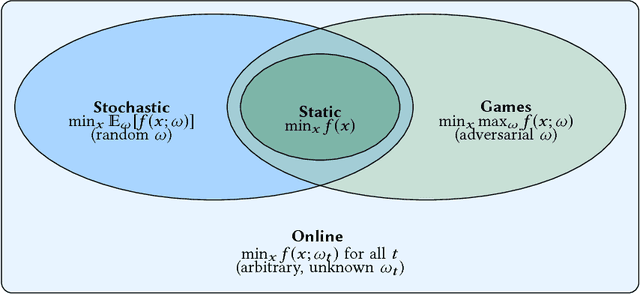



Spurred by the enthusiasm surrounding the "Big Data" paradigm, the mathematical and algorithmic tools of online optimization have found widespread use in problems where the trade-off between data exploration and exploitation plays a predominant role. This trade-off is of particular importance to several branches and applications of signal processing, such as data mining, statistical inference, multimedia indexing and wireless communications (to name but a few). With this in mind, the aim of this tutorial paper is to provide a gentle introduction to online optimization and learning algorithms that are asymptotically optimal in hindsight - i.e., they approach the performance of a virtual algorithm with unlimited computational power and full knowledge of the future, a property known as no-regret. Particular attention is devoted to identifying the algorithms' theoretical performance guarantees and to establish links with classic optimization paradigms (both static and stochastic). To allow a better understanding of this toolbox, we provide several examples throughout the tutorial ranging from metric learning to wireless resource allocation problems.
Distributed stochastic optimization via matrix exponential learning
Jun 03, 2016
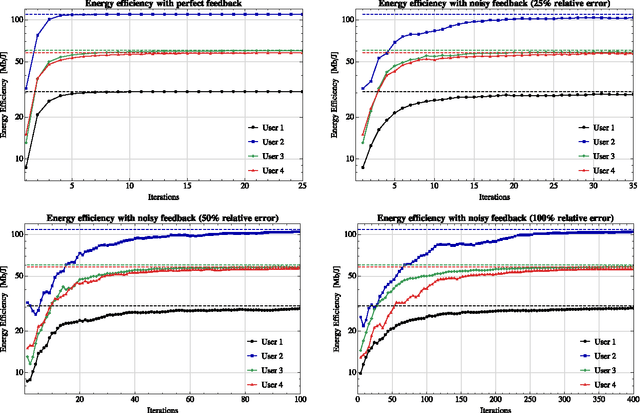
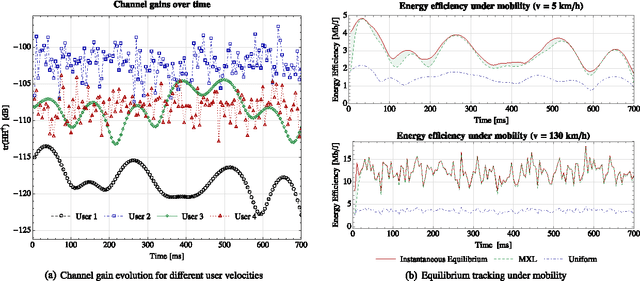
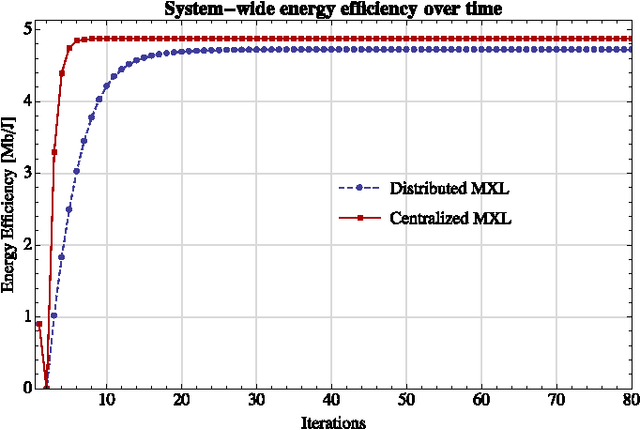
In this paper, we investigate a distributed learning scheme for a broad class of stochastic optimization problems and games that arise in signal processing and wireless communications. The proposed algorithm relies on the method of matrix exponential learning (MXL) and only requires locally computable gradient observations that are possibly imperfect and/or obsolete. To analyze it, we introduce the notion of a stable Nash equilibrium and we show that the algorithm is globally convergent to such equilibria - or locally convergent when an equilibrium is only locally stable. We also derive an explicit linear bound for the algorithm's convergence speed, which remains valid under measurement errors and uncertainty of arbitrarily high variance. To validate our theoretical analysis, we test the algorithm in realistic multi-carrier/multiple-antenna wireless scenarios where several users seek to maximize their energy efficiency. Our results show that learning allows users to attain a net increase between 100% and 500% in energy efficiency, even under very high uncertainty.