 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-RRM: Advancing Omni Reward Modeling via Automatic Rubric-Grounded Preference Synthesis
Jan 31, 2026Multimodal large language models (MLLMs) have shown remarkable capabilities, yet their performance is often capped by the coarse nature of existing alignment techniques. A critical bottleneck remains the lack of effective reward models (RMs): existing RMs are predominantly vision-centric, return opaque scalar scores, and rely on costly human annotations. We introduce \textbf{Omni-RRM}, the first open-source rubric-grounded reward model that produces structured, multi-dimension preference judgments with dimension-wise justifications across \textbf{text, image, video, and audio}. At the core of our approach is \textbf{Omni-Preference}, a large-scale dataset built via a fully automated pipeline: we synthesize candidate response pairs by contrasting models of different capabilities, and use strong teacher models to \emph{reconcile and filter} preferences while providing a modality-aware \emph{rubric-grounded rationale} for each pair. This eliminates the need for human-labeled training preferences. Omni-RRM is trained in two stages: supervised fine-tuning to learn the rubric-grounded outputs, followed by reinforcement learning (GRPO) to sharpen discrimination on difficult, low-contrast pairs. Comprehensive evaluations show that Omni-RRM achieves state-of-the-art accuracy on video (80.2\% on ShareGPT-V) and audio (66.8\% on Audio-HH-RLHF) benchmarks, and substantially outperforms existing open-source RMs on image tasks, with a 17.7\% absolute gain over its base model on overall accuracy. Omni-RRM also improves downstream performance via Best-of-$N$ selection and transfers to text-only preference benchmarks. Our data, code, and models are available at https://anonymous.4open.science/r/Omni-RRM-CC08.
Interpretable Safety Alignment via SAE-Constructed Low-Rank Subspace Adaptation
Dec 29, 2025Parameter-efficient fine-tuning has become the dominant paradigm for adapting large language models to downstream tasks. Low-rank adaptation methods such as LoRA operate under the assumption that task-relevant weight updates reside in a low-rank subspace, yet this subspace is learned implicitly from data in a black-box manner, offering no interpretability or direct control. We hypothesize that this difficulty stems from polysemanticity--individual dimensions encoding multiple entangled concepts. To address this, we leverage pre-trained Sparse Autoencoders (SAEs) to identify task-relevant features in a disentangled feature space, then construct an explicit, interpretable low-rank subspace to guide adapter initialization. We provide theoretical analysis proving that under monosemanticity assumptions, SAE-based subspace identification achieves arbitrarily small recovery error, while direct identification in polysemantic space suffers an irreducible error floor. On safety alignment, our method achieves up to 99.6% safety rate--exceeding full fine-tuning by 7.4 percentage points and approaching RLHF-based methods--while updating only 0.19-0.24% of parameters. Crucially, our method provides interpretable insights into the learned alignment subspace through the semantic grounding of SAE features. Our work demonstrates that incorporating mechanistic interpretability into the fine-tuning process can simultaneously improve both performance and transparency.
Unlocking the Address Book: Dissecting the Sparse Semantic Structure of LLM Key-Value Caches via Sparse Autoencoders
Dec 11, 2025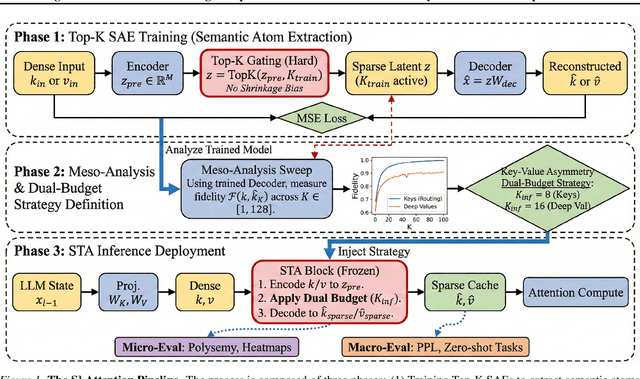

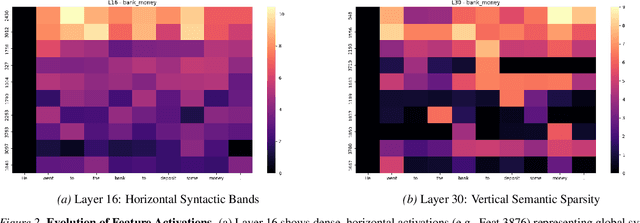

The Key-Value (KV) cache is the primary memory bottleneck in long-context Large Language Models, yet it is typically treated as an opaque numerical tensor. In this work, we propose \textbf{STA-Attention}, a framework that utilizes Top-K Sparse Autoencoders (SAEs) to decompose the KV cache into interpretable ``semantic atoms.'' Unlike standard $L_1$-regularized SAEs, our Top-K approach eliminates shrinkage bias, preserving the precise dot-product geometry required for attention. Our analysis uncovers a fundamental \textbf{Key-Value Asymmetry}: while Key vectors serve as highly sparse routers dominated by a ``Semantic Elbow,'' deep Value vectors carry dense content payloads requiring a larger budget. Based on this structure, we introduce a Dual-Budget Strategy that selectively preserves the most informative semantic components while filtering representational noise. Experiments on Yi-6B, Mistral-7B, Qwen2.5-32B, and others show that our semantic reconstructions maintain perplexity and zero-shot performance comparable to the original models, effectively bridging the gap between mechanistic interpretability and faithful attention modeling.
A*-Thought: Efficient Reasoning via Bidirectional Compression for Low-Resource Settings
May 30, 2025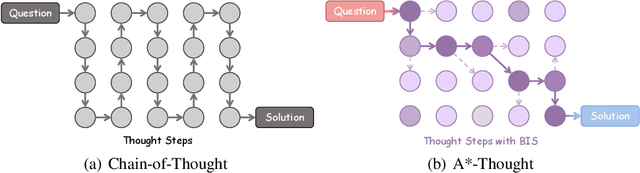
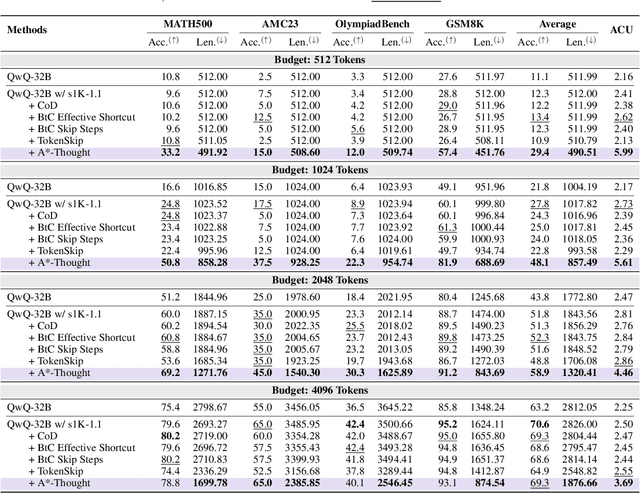
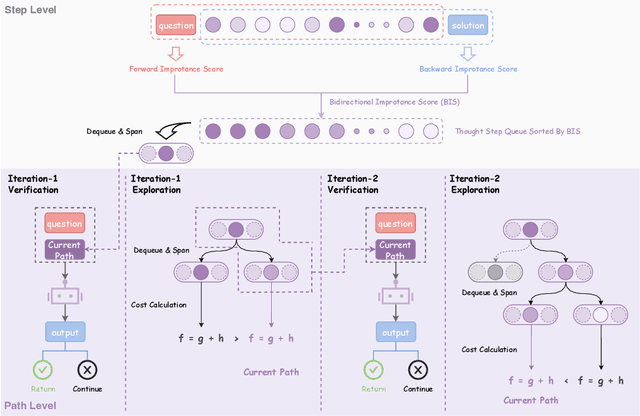

Large Reasoning Models (LRMs) achieve superior performance by extending the thought length. However, a lengthy thinking trajectory leads to reduced efficiency. Most of the existing methods are stuck in the assumption of overthinking and attempt to reason efficiently by compressing the Chain-of-Thought, but this often leads to performance degradation. To address this problem, we introduce A*-Thought, an efficient tree search-based unified framework designed to identify and isolate the most essential thoughts from the extensive reasoning chains produced by these models. It formulates the reasoning process of LRMs as a search tree, where each node represents a reasoning span in the giant reasoning space. By combining the A* search algorithm with a cost function specific to the reasoning path, it can efficiently compress the chain of thought and determine a reasoning path with high information density and low cost. In addition, we also propose a bidirectional importance estimation mechanism, which further refines this search process and enhances its efficiency beyond uniform sampling. Extensive experiments on several advanced math tasks show that A*-Thought effectively balances performance and efficiency over a huge search space. Specifically, A*-Thought can improve the performance of QwQ-32B by 2.39$\times$ with low-budget and reduce the length of the output token by nearly 50% with high-budget. The proposed method is also compatible with several other LRMs, demonstrating its generalization capability. The code can be accessed at: https://github.com/AI9Stars/AStar-Thought.
Beyond Face Swapping: A Diffusion-Based Digital Human Benchmark for Multimodal Deepfake Detection
May 22, 2025In recent years, the rapid development of deepfake technology has given rise to an emerging and serious threat to public security: diffusion model-based digital human generation. Unlike traditional face manipulation methods, such models can generate highly realistic videos with consistency through multimodal control signals. Their flexibility and covertness pose severe challenges to existing detection strategies. To bridge this gap, we introduce DigiFakeAV, the first large-scale multimodal digital human forgery dataset based on diffusion models. Employing five latest digital human generation methods (Sonic, Hallo, etc.) and voice cloning method, we systematically produce a dataset comprising 60,000 videos (8.4 million frames), covering multiple nationalities, skin tones, genders, and real-world scenarios, significantly enhancing data diversity and realism. User studies show that the confusion rate between forged and real videos reaches 68%, and existing state-of-the-art (SOTA) detection models exhibit large drops in AUC values on DigiFakeAV, highlighting the challenge of the dataset. To address this problem, we further propose DigiShield, a detection baseline based on spatiotemporal and cross-modal fusion. By jointly modeling the 3D spatiotemporal features of videos and the semantic-acoustic features of audio, DigiShield achieves SOTA performance on both the DigiFakeAV and DF-TIMIT datasets. Experiments show that this method effectively identifies covert artifacts through fine-grained analysis of the temporal evolution of facial features in synthetic videos.
Rethinking Class-Incremental Learning from a Dynamic Imbalanced Learning Perspective
May 24, 2024



Deep neural networks suffer from catastrophic forgetting when continually learning new concepts. In this paper, we analyze this problem from a data imbalance point of view. We argue that the imbalance between old task and new task data contributes to forgetting of the old tasks. Moreover, the increasing imbalance ratio during incremental learning further aggravates the problem. To address the dynamic imbalance issue, we propose Uniform Prototype Contrastive Learning (UPCL), where uniform and compact features are learned. Specifically, we generate a set of non-learnable uniform prototypes before each task starts. Then we assign these uniform prototypes to each class and guide the feature learning through prototype contrastive learning. We also dynamically adjust the relative margin between old and new classes so that the feature distribution will be maintained balanced and compact. Finally, we demonstrate through extensive experiments that the proposed method achieves state-of-the-art performance on several benchmark datasets including CIFAR100, ImageNet100 and TinyImageNet.
Dynamic Generation of Personalities with Large Language Models
Apr 10, 2024
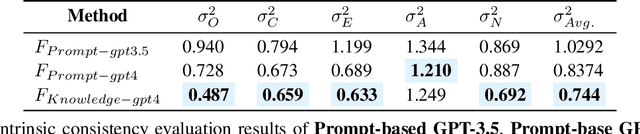
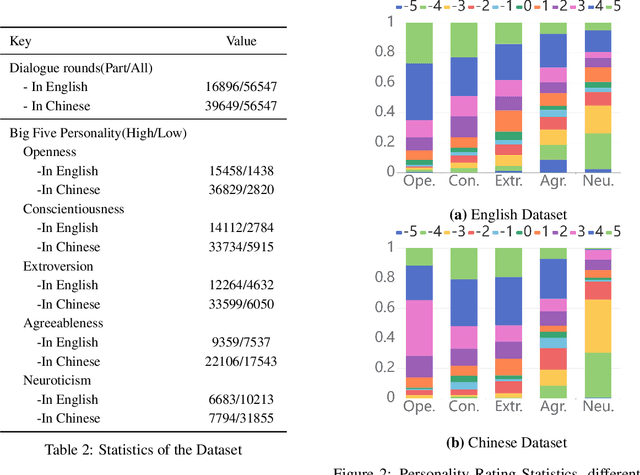

In the realm of mimicking human deliberation, large language models (LLMs) show promising performance, thereby amplifying the importance of this research area. Deliberation is influenced by both logic and personality. However, previous studies predominantly focused on the logic of LLMs, neglecting the exploration of personality aspects. In this work, we introduce Dynamic Personality Generation (DPG), a dynamic personality generation method based on Hypernetworks. Initially, we embed the Big Five personality theory into GPT-4 to form a personality assessment machine, enabling it to evaluate characters' personality traits from dialogues automatically. We propose a new metric to assess personality generation capability based on this evaluation method. Then, we use this personality assessment machine to evaluate dialogues in script data, resulting in a personality-dialogue dataset. Finally, we fine-tune DPG on the personality-dialogue dataset. Experiments prove that DPG's personality generation capability is stronger after fine-tuning on this dataset than traditional fine-tuning methods, surpassing prompt-based GPT-4.
HyperMoE: Paying Attention to Unselected Experts in Mixture of Experts via Dynamic Transfer
Feb 25, 2024



The Mixture of Experts (MoE) for language models has been proven effective in augmenting the capacity of models by dynamically routing each input token to a specific subset of experts for processing. Despite the success, most existing methods face a challenge for balance between sparsity and the availability of expert knowledge: enhancing performance through increased use of expert knowledge often results in diminishing sparsity during expert selection. To mitigate this contradiction, we propose HyperMoE, a novel MoE framework built upon Hypernetworks. This framework integrates the computational processes of MoE with the concept of knowledge transferring in multi-task learning. Specific modules generated based on the information of unselected experts serve as supplementary information, which allows the knowledge of experts not selected to be used while maintaining selection sparsity. Our comprehensive empirical evaluations across multiple datasets and backbones establish that HyperMoE significantly outperforms existing MoE methods under identical conditions concerning the number of experts.
Shortcut Sequence Tagging
Jan 03, 2017



Deep stacked RNNs are usually hard to train. Adding shortcut connections across different layers is a common way to ease the training of stacked networks. However, extra shortcuts make the recurrent step more complicated. To simply the stacked architecture, we propose a framework called shortcut block, which is a marriage of the gating mechanism and shortcuts, while discarding the self-connected part in LSTM cell. We present extensive empirical experiments showing that this design makes training easy and improves generalization. We propose various shortcut block topologies and compositions to explore its effectiveness. Based on this architecture, we obtain a 6% relatively improvement over the state-of-the-art on CCGbank supertagging dataset. We also get comparable results on POS tagging task.
An Empirical Exploration of Skip Connections for Sequential Tagging
Oct 11, 2016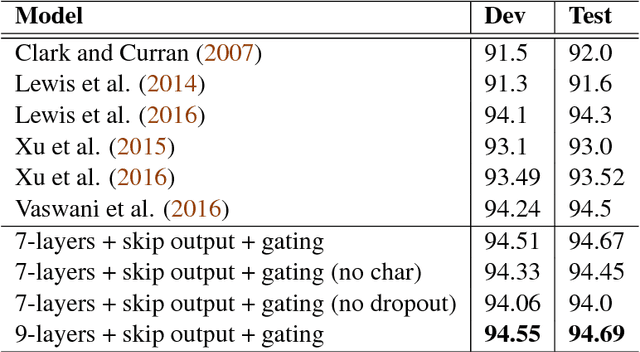

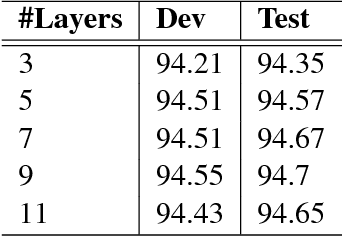

In this paper, we empirically explore the effects of various kinds of skip connections in stacked bidirectional LSTMs for sequential tagging. We investigate three kinds of skip connections connecting to LSTM cells: (a) skip connections to the gates, (b) skip connections to the internal states and (c) skip connections to the cell outputs. We present comprehensive experiments showing that skip connections to cell outputs outperform the remaining two. Furthermore, we observe that using gated identity functions as skip mappings works pretty well. Based on this novel skip connections, we successfully train deep stacked bidirectional LSTM models and obtain state-of-the-art results on CCG supertagging and comparable results on POS tagging.