 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-Assisted Motion Learning Network for Weakly-Supervised Group Activity Recognition
May 28, 2024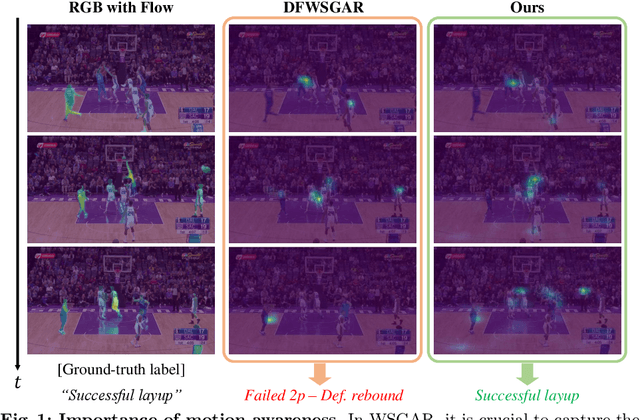



Weakly-Supervised Group Activity Recognition (WSGAR) aims to understand the activity performed together by a group of individuals with the video-level label and without actor-level labels. We propose Flow-Assisted Motion Learning Network (Flaming-Net) for WSGAR, which consists of the motion-aware actor encoder to extract actor features and the two-pathways relation module to infer the interaction among actors and their activity. Flaming-Net leverages an additional optical flow modality in the training stage to enhance its motion awareness when finding locally active actors. The first pathway of the relation module, the actor-centric path, initially captures the temporal dynamics of individual actors and then constructs inter-actor relationships. In parallel, the group-centric path starts by building spatial connections between actors within the same timeframe and then captures simultaneous spatio-temporal dynamics among them. We demonstrate that Flaming-Net achieves new state-of-the-art WSGAR results on two benchmarks, including a 2.8%p higher MPCA score on the NBA dataset. Importantly, we use the optical flow modality only for training and not for inference.
Modality Mixer Exploiting Complementary Information for Multi-modal Action Recognition
Nov 21, 2023Due to the distinctive characteristics of sensors, each modality exhibits unique physical properties. For this reason, in the context of multi-modal action recognition, it is important to consider not only the overall action content but also the complementary nature of different modalities. In this paper, we propose a novel network, named Modality Mixer (M-Mixer) network, which effectively leverages and incorporates the complementary information across modalities with the temporal context of actions for action recognition. A key component of our proposed M-Mixer is the Multi-modal Contextualization Unit (MCU), a simple yet effective recurrent unit. Our MCU is responsible for temporally encoding a sequence of one modality (e.g., RGB) with action content features of other modalities (e.g., depth and infrared modalities). This process encourages M-Mixer network to exploit global action content and also to supplement complementary information of other modalities. Furthermore, to extract appropriate complementary information regarding to the given modality settings, we introduce a new module, named Complementary Feature Extraction Module (CFEM). CFEM incorporates sepearte learnable query embeddings for each modality, which guide CFEM to extract complementary information and global action content from the other modalities. As a result, our proposed method outperforms state-of-the-art methods on NTU RGB+D 60, NTU RGB+D 120, and NW-UCLA datasets. Moreover, through comprehensive ablation studies, we further validate the effectiveness of our proposed method.
Audio-Visual Glance Network for Efficient Video Recognition
Aug 18, 2023


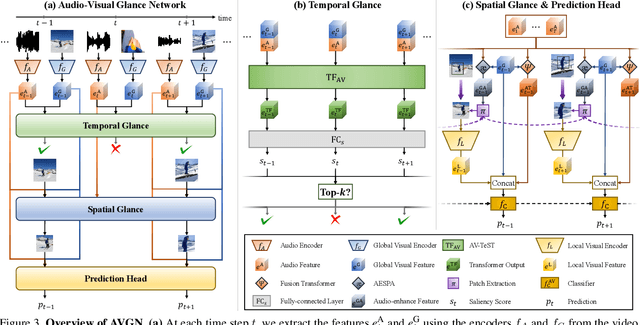
Deep learning has made significant strides in video understanding tasks, but the computation required to classify lengthy and massive videos using clip-level video classifiers remains impractical and prohibitively expensive. To address this issue, we propose Audio-Visual Glance Network (AVGN), which leverages the commonly available audio and visual modalities to efficiently process the spatio-temporally important parts of a video. AVGN firstly divides the video into snippets of image-audio clip pair and employs lightweight unimodal encoders to extract global visual features and audio features. To identify the important temporal segments, we use an Audio-Visual Temporal Saliency Transformer (AV-TeST) that estimates the saliency scores of each frame. To further increase efficiency in the spatial dimension, AVGN processes only the important patches instead of the whole images. We use an Audio-Enhanced Spatial Patch Attention (AESPA) module to produce a set of enhanced coarse visual features, which are fed to a policy network that produces the coordinates of the important patches. This approach enables us to focus only on the most important spatio-temporally parts of the video, leading to more efficient video recognition. Moreover, we incorporate various training techniques and multi-modal feature fusion to enhance the robustness and effectiveness of our AVGN. By combining these strategies, our AVGN sets new state-of-the-art performance in multiple video recognition benchmarks while achieving faster processing speed.
Towards Good Practices for Missing Modality Robust Action Recognition
Nov 25, 2022Standard multi-modal models assume the use of the same modalities in training and inference stages. However, in practice, the environment in which multi-modal models operate may not satisfy such assumption. As such, their performances degrade drastically if any modality is missing in the inference stage. We ask: how can we train a model that is robust to missing modalities? This paper seeks a set of good practices for multi-modal action recognition, with a particular interest in circumstances where some modalities are not available at an inference time. First, we study how to effectively regularize the model during training (e.g., data augmentation). Second, we investigate on fusion methods for robustness to missing modalities: we find that transformer-based fusion shows better robustness for missing modality than summation or concatenation. Third, we propose a simple modular network, ActionMAE, which learns missing modality predictive coding by randomly dropping modality features and tries to reconstruct them with the remaining modality features. Coupling these good practices, we build a model that is not only effective in multi-modal action recognition but also robust to modality missing. Our model achieves the state-of-the-arts on multiple benchmarks and maintains competitive performances even in missing modality scenarios. Codes are available at https://github.com/sangminwoo/ActionMAE.
Modality Mixer for Multi-modal Action Recognition
Aug 24, 2022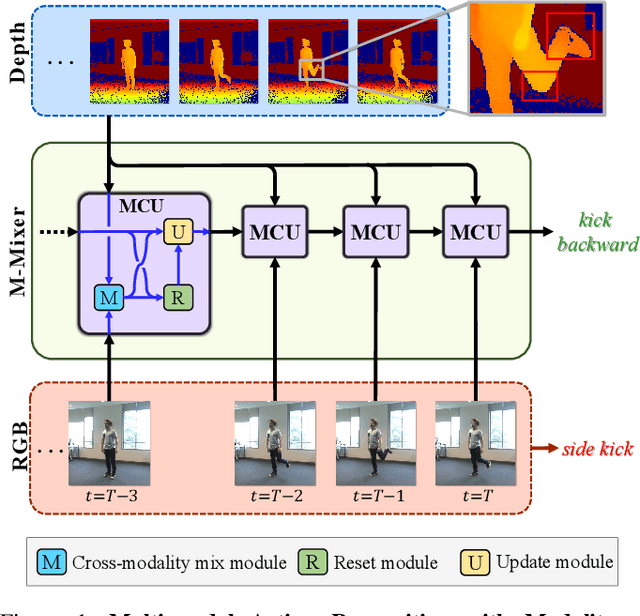


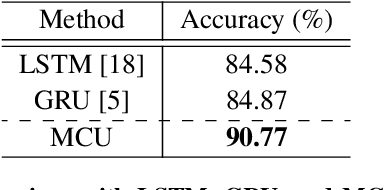
In multi-modal action recognition, it is important to consider not only the complementary nature of different modalities but also global action content. In this paper, we propose a novel network, named Modality Mixer (M-Mixer) network, to leverage complementary information across modalities and temporal context of an action for multi-modal action recognition. We also introduce a simple yet effective recurrent unit, called Multi-modal Contextualization Unit (MCU), which is a core component of M-Mixer. Our MCU temporally encodes a sequence of one modality (e.g., RGB) with action content features of other modalities (e.g., depth, IR). This process encourages M-Mixer to exploit global action content and also to supplement complementary information of other modalities. As a result, our proposed method outperforms state-of-the-art methods on NTU RGB+D 60, NTU RGB+D 120, and NW-UCLA datasets. Moreover, we demonstrate the effectiveness of M-Mixer by conducting comprehensive ablation studies.
Test-time Adaptation for Real Image Denoising via Meta-transfer Learning
Jul 05, 2022
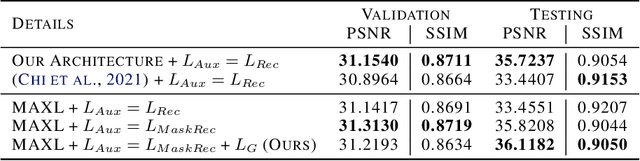

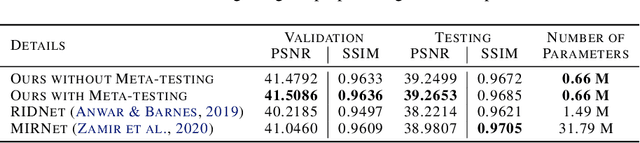
In recent years, a ton of research has been conducted on real image denoising tasks. However, the efforts are more focused on improving real image denoising through creating a better network architecture. We explore a different direction where we propose to improve real image denoising performance through a better learning strategy that can enable test-time adaptation on the multi-task network. The learning strategy is two stages where the first stage pre-train the network using meta-auxiliary learning to get better meta-initialization. Meanwhile, we use meta-learning for fine-tuning (meta-transfer learning) the network as the second stage of our training to enable test-time adaptation on real noisy images. To exploit a better learning strategy, we also propose a network architecture with self-supervised masked reconstruction loss. Experiments on a real noisy dataset show the contribution of the proposed method and show that the proposed method can outperform other SOTA methods.