 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionGrounder: Grounded Multi-Object Motion Transfer via Diffusion Transformer
Apr 01, 2026Motion transfer enables controllable video generation by transferring temporal dynamics from a reference video to synthesize a new video conditioned on a target caption. However, existing Diffusion Transformer (DiT)-based methods are limited to single-object videos, restricting fine-grained control in real-world scenes with multiple objects. In this work, we introduce MotionGrounder, a DiT-based framework that firstly handles motion transfer with multi-object controllability. Our Flow-based Motion Signal (FMS) in MotionGrounder provides a stable motion prior for target video generation, while our Object-Caption Alignment Loss (OCAL) grounds object captions to their corresponding spatial regions. We further propose a new Object Grounding Score (OGS), which jointly evaluates (i) spatial alignment between source video objects and their generated counterparts and (ii) semantic consistency between each generated object and its target caption. Our experiments show that MotionGrounder consistently outperforms recent baselines across quantitative, qualitative, and human evaluations.
MIVE: New Design and Benchmark for Multi-Instance Video Editing
Dec 17, 2024



Recent AI-based video editing has enabled users to edit videos through simple text prompts, significantly simplifying the editing process. However, recent zero-shot video editing techniques primarily focus on global or single-object edits, which can lead to unintended changes in other parts of the video. When multiple objects require localized edits, existing methods face challenges, such as unfaithful editing, editing leakage, and lack of suitable evaluation datasets and metrics. To overcome these limitations, we propose a zero-shot $\textbf{M}$ulti-$\textbf{I}$nstance $\textbf{V}$ideo $\textbf{E}$diting framework, called MIVE. MIVE is a general-purpose mask-based framework, not dedicated to specific objects (e.g., people). MIVE introduces two key modules: (i) Disentangled Multi-instance Sampling (DMS) to prevent editing leakage and (ii) Instance-centric Probability Redistribution (IPR) to ensure precise localization and faithful editing. Additionally, we present our new MIVE Dataset featuring diverse video scenarios and introduce the Cross-Instance Accuracy (CIA) Score to evaluate editing leakage in multi-instance video editing tasks. Our extensive qualitative, quantitative, and user study evaluations demonstrate that MIVE significantly outperforms recent state-of-the-art methods in terms of editing faithfulness, accuracy, and leakage prevention, setting a new benchmark for multi-instance video editing. The project page is available at https://kaist-viclab.github.io/mive-site/
Modernizing Old Photos Using Multiple References via Photorealistic Style Transfer
Apr 10, 2023



This paper firstly presents old photo modernization using multiple references by performing stylization and enhancement in a unified manner. In order to modernize old photos, we propose a novel multi-reference-based old photo modernization (MROPM) framework consisting of a network MROPM-Net and a novel synthetic data generation scheme. MROPM-Net stylizes old photos using multiple references via photorealistic style transfer (PST) and further enhances the results to produce modern-looking images. Meanwhile, the synthetic data generation scheme trains the network to effectively utilize multiple references to perform modernization. To evaluate the performance, we propose a new old photos benchmark dataset (CHD) consisting of diverse natural indoor and outdoor scenes. Extensive experiments show that the proposed method outperforms other baselines in performing modernization on real old photos, even though no old photos were used during training. Moreover, our method can appropriately select styles from multiple references for each semantic region in the old photo to further improve the modernization performance.
Test-time Adaptation for Real Image Denoising via Meta-transfer Learning
Jul 05, 2022
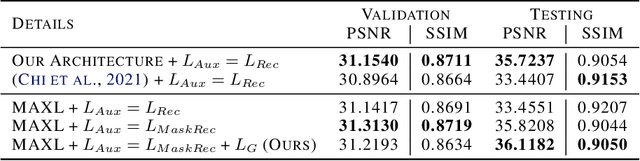

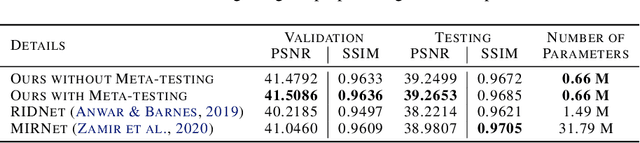
In recent years, a ton of research has been conducted on real image denoising tasks. However, the efforts are more focused on improving real image denoising through creating a better network architecture. We explore a different direction where we propose to improve real image denoising performance through a better learning strategy that can enable test-time adaptation on the multi-task network. The learning strategy is two stages where the first stage pre-train the network using meta-auxiliary learning to get better meta-initialization. Meanwhile, we use meta-learning for fine-tuning (meta-transfer learning) the network as the second stage of our training to enable test-time adaptation on real noisy images. To exploit a better learning strategy, we also propose a network architecture with self-supervised masked reconstruction loss. Experiments on a real noisy dataset show the contribution of the proposed method and show that the proposed method can outperform other SOTA methods.
Understanding and Improving Group Normalization
Jul 05, 2022
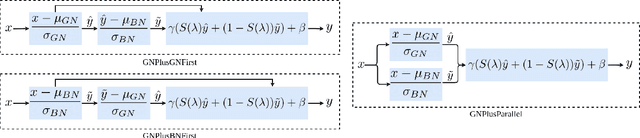
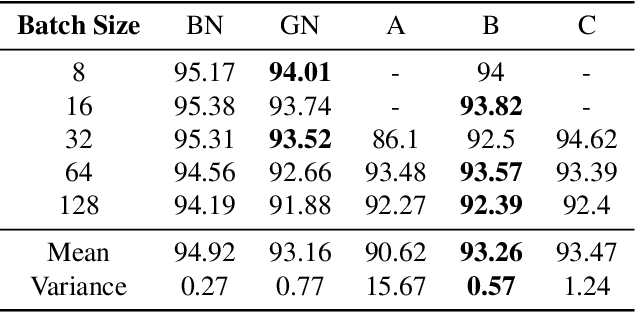
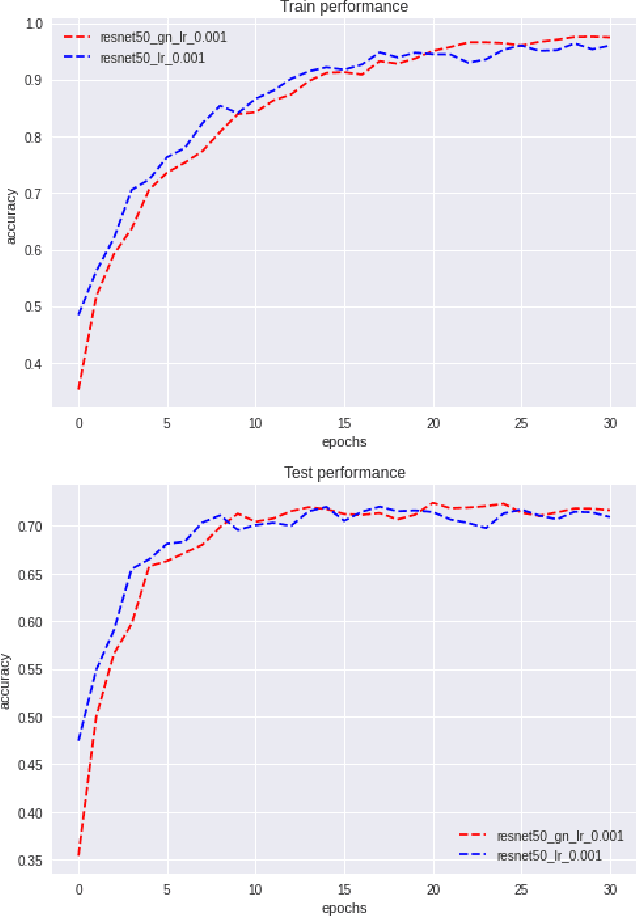
Various normalization layers have been proposed to help the training of neural networks. Group Normalization (GN) is one of the effective and attractive studies that achieved significant performances in the visual recognition task. Despite the great success achieved, GN still has several issues that may negatively impact neural network training. In this paper, we introduce an analysis framework and discuss the working principles of GN in affecting the training process of the neural network. From experimental results, we conclude the real cause of GN's inferior performance against Batch normalization (BN): 1) \textbf{unstable training performance}, 2) \textbf{more sensitive} to distortion, whether it comes from external noise or perturbations introduced by the regularization. In addition, we found that GN can only help the neural network training in some specific period, unlike BN, which helps the network throughout the training. To solve these issues, we propose a new normalization layer built on top of GN, by incorporating the advantages of BN. Experimental results on the image classification task demonstrated that the proposed normalization layer outperforms the official GN to improve recognition accuracy regardless of the batch sizes and stabilize the network training.
CISRNet: Compressed Image Super-Resolution Network
Jan 16, 2022In recent years, tons of research has been conducted on Single Image Super-Resolution (SISR). However, to the best of our knowledge, few of these studies are mainly focused on compressed images. A problem such as complicated compression artifacts hinders the advance of this study in spite of its high practical values. To tackle this problem, we proposed CISRNet; a network that employs a two-stage coarse-to-fine learning framework that is mainly optimized for Compressed Image Super-Resolution Problem. Specifically, CISRNet consists of two main subnetworks; the coarse and refinement network, where recursive and residual learning is employed within these two networks respectively. Extensive experiments show that with a careful design choice, CISRNet performs favorably against competing Single-Image Super-Resolution methods in the Compressed Image Super-Resolution tasks.