 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModernizing Old Photos Using Multiple References via Photorealistic Style Transfer
Apr 10, 2023



This paper firstly presents old photo modernization using multiple references by performing stylization and enhancement in a unified manner. In order to modernize old photos, we propose a novel multi-reference-based old photo modernization (MROPM) framework consisting of a network MROPM-Net and a novel synthetic data generation scheme. MROPM-Net stylizes old photos using multiple references via photorealistic style transfer (PST) and further enhances the results to produce modern-looking images. Meanwhile, the synthetic data generation scheme trains the network to effectively utilize multiple references to perform modernization. To evaluate the performance, we propose a new old photos benchmark dataset (CHD) consisting of diverse natural indoor and outdoor scenes. Extensive experiments show that the proposed method outperforms other baselines in performing modernization on real old photos, even though no old photos were used during training. Moreover, our method can appropriately select styles from multiple references for each semantic region in the old photo to further improve the modernization performance.
XVFI: eXtreme Video Frame Interpolation
Mar 30, 2021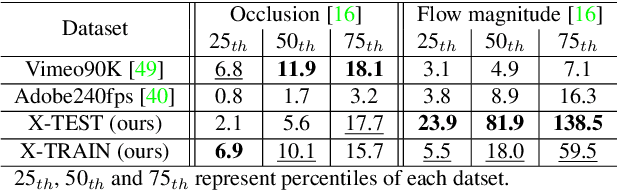

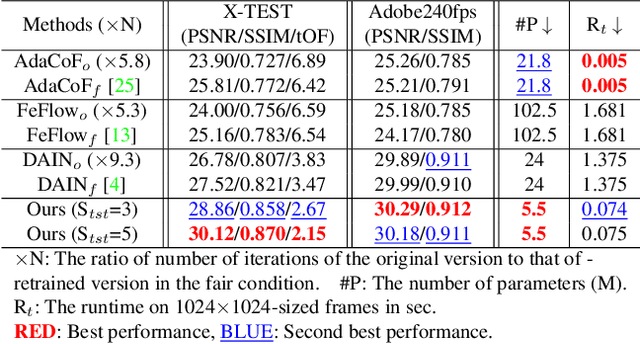
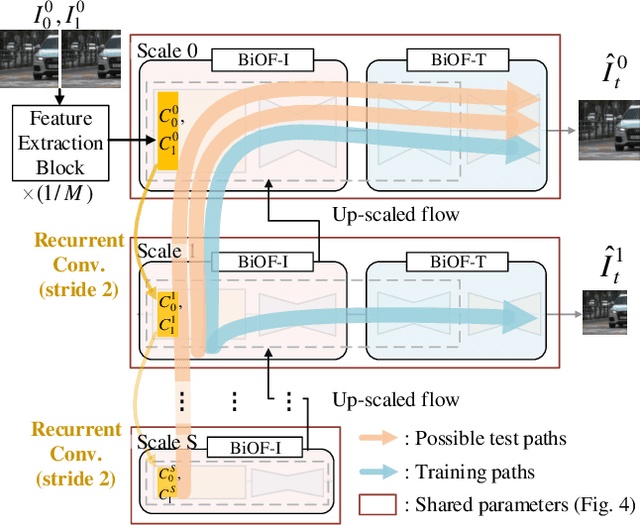
In this paper, we firstly present a dataset (X4K1000FPS) of 4K videos of 1000 fps with the extreme motion to the research community for video frame interpolation (VFI), and propose an extreme VFI network, called XVFI-Net, that first handles the VFI for 4K videos with large motion. The XVFI-Net is based on a recursive multi-scale shared structure that consists of two cascaded modules for bidirectional optical flow learning between two input frames (BiOF-I) and for bidirectional optical flow learning from target to input frames (BiOF-T). The optical flows are stably approximated by a complementary flow reversal (CFR) proposed in BiOF-T module. During inference, the BiOF-I module can start at any scale of input while the BiOF-T module only operates at the original input scale so that the inference can be accelerated while maintaining highly accurate VFI performance. Extensive experimental results show that our XVFI-Net can successfully capture the essential information of objects with extremely large motions and complex textures while the state-of-the-art methods exhibit poor performance. Furthermore, our XVFI-Net framework also performs comparably on the previous lower resolution benchmark dataset, which shows a robustness of our algorithm as well. All source codes, pre-trained models, and proposed X4K1000FPS datasets are publicly available at https://github.com/JihyongOh/XVFI.
KOALAnet: Blind Super-Resolution using Kernel-Oriented Adaptive Local Adjustment
Dec 15, 2020
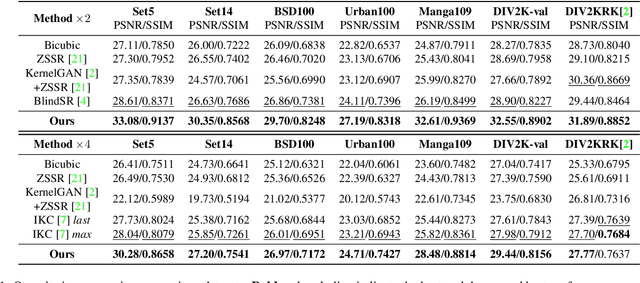
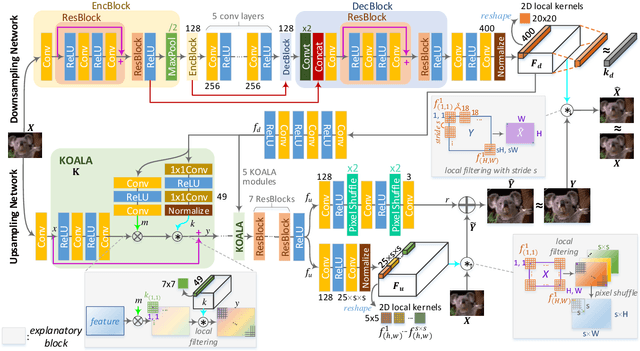
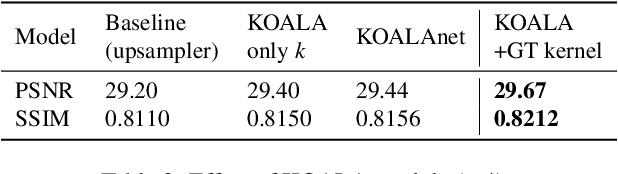
Blind super-resolution (SR) methods aim to generate a high quality high resolution image from a low resolution image containing unknown degradations. However, natural images contain various types and amounts of blur: some may be due to the inherent degradation characteristics of the camera, but some may even be intentional, for aesthetic purposes (eg. Bokeh effect). In the case of the latter, it becomes highly difficult for SR methods to disentangle the blur to remove, and that to leave as is. In this paper, we propose a novel blind SR framework based on kernel-oriented adaptive local adjustment (KOALA) of SR features, called KOALAnet, which jointly learns spatially-variant degradation and restoration kernels in order to adapt to the spatially-variant blur characteristics in real images. Our KOALAnet outperforms recent blind SR methods for synthesized LR images obtained with randomized degradations, and we further show that the proposed KOALAnet produces the most natural results for artistic photographs with intentional blur, which are not over-sharpened, by effectively handling images mixed with in-focus and out-of-focus areas.
Breaking Moravec's Paradox: Visual-Based Distribution in Smart Fashion Retail
Jul 10, 2020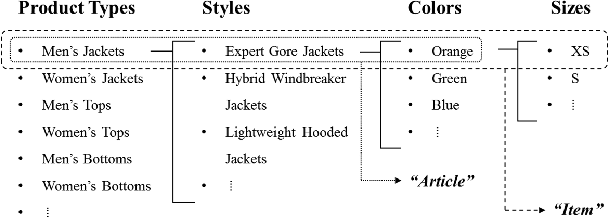
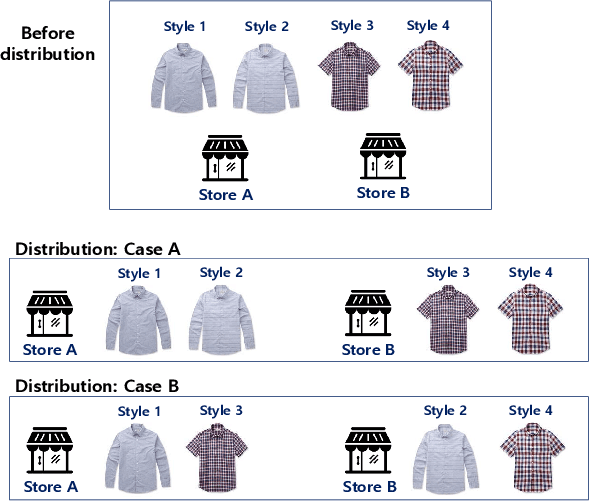
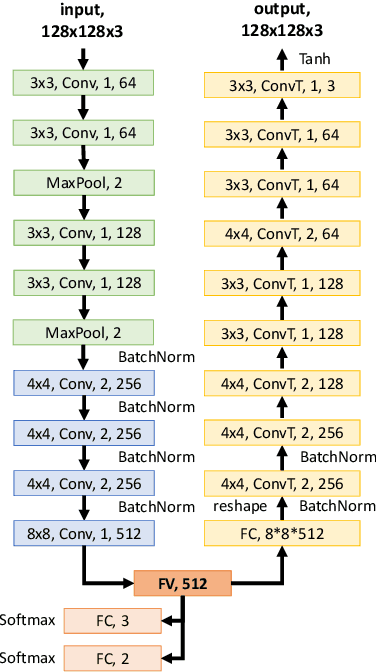

In this paper, we report an industry-academia collaborative study on the distribution method of fashion products using an artificial intelligence (AI) technique combined with an optimization method. To meet the current fashion trend of short product lifetimes and an increasing variety of styles, the company produces limited volumes of a large variety of styles. However, due to the limited volume of each style, some styles may not be distributed to some off-line stores. As a result, this high-variety, low-volume strategy presents another challenge to distribution managers. We collaborated with KOLON F/C, one of the largest fashion business units in South Korea, to develop models and an algorithm to optimally distribute the products to the stores based on the visual images of the products. The team developed a deep learning model that effectively represents the styles of clothes based on their visual image. Moreover, the team created an optimization model that effectively determines the product mix for each store based on the image representation of clothes. In the past, computers were only considered to be useful for conducting logical calculations, and visual perception and cognition were considered to be difficult computational tasks. The proposed approach is significant in that it uses both AI (perception and cognition) and mathematical optimization (logical calculation) to address a practical supply chain problem, which is why the study was called "Breaking Moravec's Paradox."