 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality Mixer for Multi-modal Action Recognition
Paper and Code
Aug 24, 2022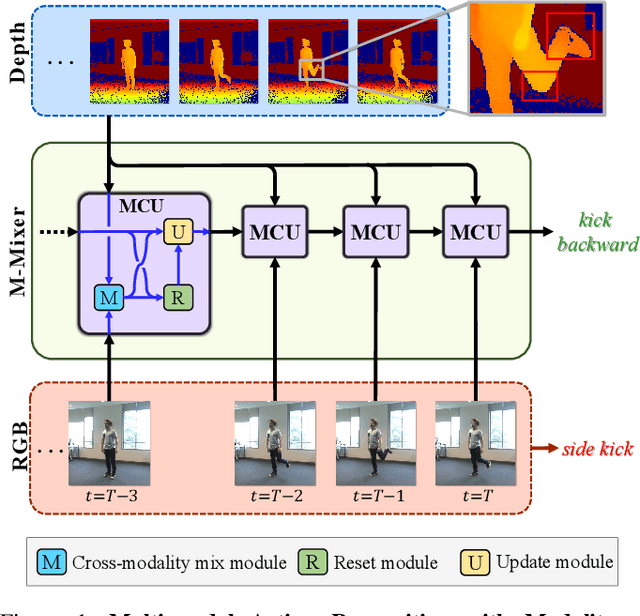


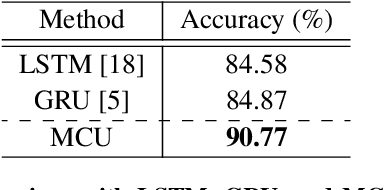
In multi-modal action recognition, it is important to consider not only the complementary nature of different modalities but also global action content. In this paper, we propose a novel network, named Modality Mixer (M-Mixer) network, to leverage complementary information across modalities and temporal context of an action for multi-modal action recognition. We also introduce a simple yet effective recurrent unit, called Multi-modal Contextualization Unit (MCU), which is a core component of M-Mixer. Our MCU temporally encodes a sequence of one modality (e.g., RGB) with action content features of other modalities (e.g., depth, IR). This process encourages M-Mixer to exploit global action content and also to supplement complementary information of other modalities. As a result, our proposed method outperforms state-of-the-art methods on NTU RGB+D 60, NTU RGB+D 120, and NW-UCLA datasets. Moreover, we demonstrate the effectiveness of M-Mixer by conducting comprehensive ablation studies.