 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Electro-Optical Vision Foundation Models for Remote Sensing Retrieval: A Controlled Comparison with Generalist VFM
May 04, 2026Vision foundation models have attracted significant attention for their ability to leverage large-scale unlabeled visual data. This advantage is particularly important in remote sensing, where data acquisition is costly and annotation often requires expert knowledge. Recent electro-optical vision foundation models aim to learn domain-specific representations from remote sensing imagery, but it remains unclear whether they are more effective than strong generalist vision foundation models under retrieval-based evaluation. In this study, we conduct a controlled comparison between representative EO-specific and generalist vision foundation models for remote sensing image retrieval. Using the same datasets, retrieval protocol, and evaluation metric, we evaluate both in-domain performance and cross-scene generalization. Our results show that strong generalist vision foundation models are competitive with, and in some cases outperform, existing EO-specific models. Moreover, EO-specific models often suffer from substantial degradation under cross-scene evaluation, while generalist models show more stable transfer. These findings suggest that EO pretraining alone does not guarantee stronger retrieval-oriented remote sensing representations. We discuss the limitations of current EO-specific pretraining strategies and highlight the need for future EO vision foundation models to better exploit the physical, spatial, spectral, and geographic characteristics of remote sensing imagery.
AIS-LLM: A Unified Framework for Maritime Trajectory Prediction, Anomaly Detection, and Collision Risk Assessment with Explainable Forecasting
Aug 11, 2025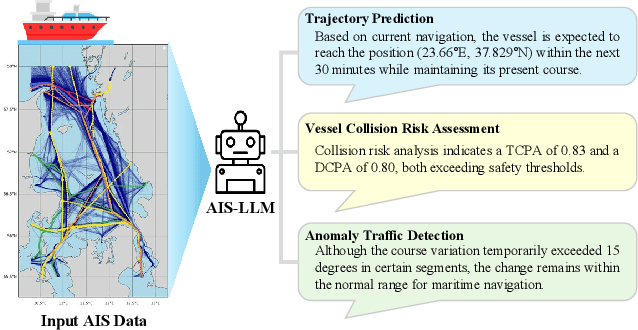

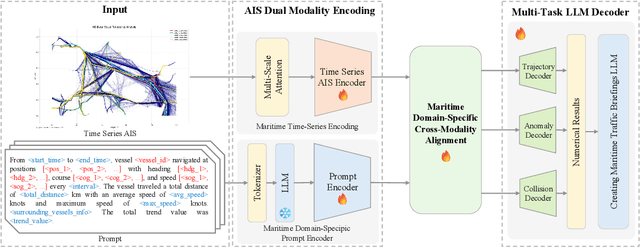

With the increase in maritime traffic and the mandatory implementation of the Automatic Identification System (AIS), the importance and diversity of maritime traffic analysis tasks based on AIS data, such as vessel trajectory prediction, anomaly detection, and collision risk assessment, is rapidly growing. However, existing approaches tend to address these tasks individually, making it difficult to holistically consider complex maritime situations. To address this limitation, we propose a novel framework, AIS-LLM, which integrates time-series AIS data with a large language model (LLM). AIS-LLM consists of a Time-Series Encoder for processing AIS sequences, an LLM-based Prompt Encoder, a Cross-Modality Alignment Module for semantic alignment between time-series data and textual prompts, and an LLM-based Multi-Task Decoder. This architecture enables the simultaneous execution of three key tasks: trajectory prediction, anomaly detection, and risk assessment of vessel collisions within a single end-to-end system. Experimental results demonstrate that AIS-LLM outperforms existing methods across individual tasks, validating its effectiveness. Furthermore, by integratively analyzing task outputs to generate situation summaries and briefings, AIS-LLM presents the potential for more intelligent and efficient maritime traffic management.
PBVS 2024 Solution: Self-Supervised Learning and Sampling Strategies for SAR Classification in Extreme Long-Tail Distribution
Dec 17, 2024



The Multimodal Learning Workshop (PBVS 2024) aims to improve the performance of automatic target recognition (ATR) systems by leveraging both Synthetic Aperture Radar (SAR) data, which is difficult to interpret but remains unaffected by weather conditions and visible light, and Electro-Optical (EO) data for simultaneous learning. The subtask, known as the Multi-modal Aerial View Imagery Challenge - Classification, focuses on predicting the class label of a low-resolution aerial image based on a set of SAR-EO image pairs and their respective class labels. The provided dataset consists of SAR-EO pairs, characterized by a severe long-tail distribution with over a 1000-fold difference between the largest and smallest classes, making typical long-tail methods difficult to apply. Additionally, the domain disparity between the SAR and EO datasets complicates the effectiveness of standard multimodal methods. To address these significant challenges, we propose a two-stage learning approach that utilizes self-supervised techniques, combined with multimodal learning and inference through SAR-to-EO translation for effective EO utilization. In the final testing phase of the PBVS 2024 Multi-modal Aerial View Image Challenge - Classification (SAR Classification) task, our model achieved an accuracy of 21.45%, an AUC of 0.56, and a total score of 0.30, placing us 9th in the competition.
A Multi-In-Single-Out Network for Video Frame Interpolation without Optical Flow
Dec 05, 2023In general, deep learning-based video frame interpolation (VFI) methods have predominantly focused on estimating motion vectors between two input frames and warping them to the target time. While this approach has shown impressive performance for linear motion between two input frames, it exhibits limitations when dealing with occlusions and nonlinear movements. Recently, generative models have been applied to VFI to address these issues. However, as VFI is not a task focused on generating plausible images, but rather on predicting accurate intermediate frames between two given frames, performance limitations still persist. In this paper, we propose a multi-in-single-out (MISO) based VFI method that does not rely on motion vector estimation, allowing it to effectively model occlusions and nonlinear motion. Additionally, we introduce a novel motion perceptual loss that enables MISO-VFI to better capture the spatio-temporal correlations within the video frames. Our MISO-VFI method achieves state-of-the-art results on VFI benchmarks Vimeo90K, Middlebury, and UCF101, with a significant performance gap compared to existing approaches.