 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Classifiers of Prototypes and Reciprocal Points for Universal Domain Adaptation
Dec 16, 2022



Universal Domain Adaptation aims to transfer the knowledge between the datasets by handling two shifts: domain-shift and category-shift. The main challenge is correctly distinguishing the unknown target samples while adapting the distribution of known class knowledge from source to target. Most existing methods approach this problem by first training the target adapted known classifier and then relying on the single threshold to distinguish unknown target samples. However, this simple threshold-based approach prevents the model from considering the underlying complexities existing between the known and unknown samples in the high-dimensional feature space. In this paper, we propose a new approach in which we use two sets of feature points, namely dual Classifiers for Prototypes and Reciprocals (CPR). Our key idea is to associate each prototype with corresponding known class features while pushing the reciprocals apart from these prototypes to locate them in the potential unknown feature space. The target samples are then classified as unknown if they fall near any reciprocals at test time. To successfully train our framework, we collect the partial, confident target samples that are classified as known or unknown through on our proposed multi-criteria selection. We then additionally apply the entropy loss regularization to them. For further adaptation, we also apply standard consistency regularization that matches the predictions of two different views of the input to make more compact target feature space. We evaluate our proposal, CPR, on three standard benchmarks and achieve comparable or new state-of-the-art results. We also provide extensive ablation experiments to verify our main design choices in our framework.
ML-BPM: Multi-teacher Learning with Bidirectional Photometric Mixing for Open Compound Domain Adaptation in Semantic Segmentation
Jul 19, 2022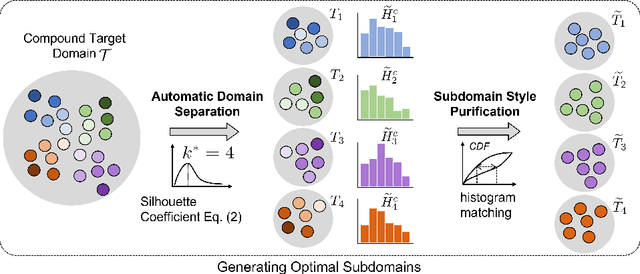
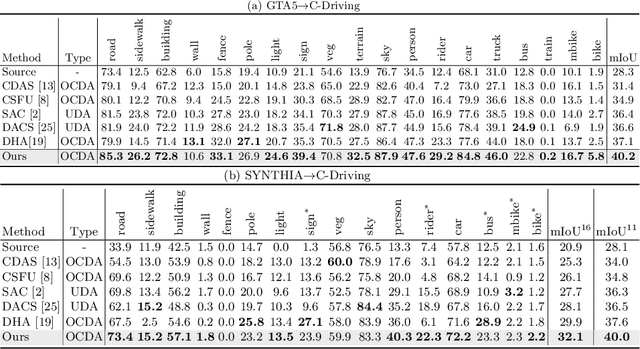

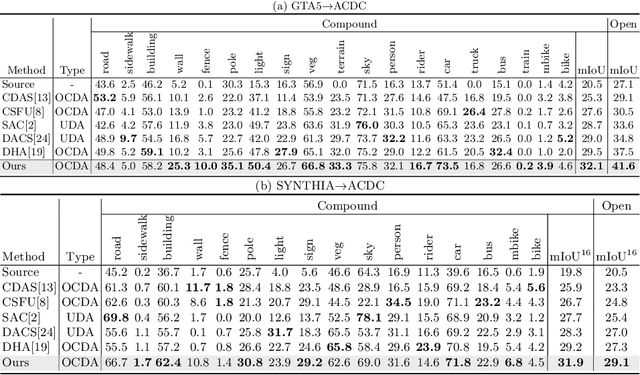
Open compound domain adaptation (OCDA) considers the target domain as the compound of multiple unknown homogeneous subdomains. The goal of OCDA is to minimize the domain gap between the labeled source domain and the unlabeled compound target domain, which benefits the model generalization to the unseen domains. Current OCDA for semantic segmentation methods adopt manual domain separation and employ a single model to simultaneously adapt to all the target subdomains. However, adapting to a target subdomain might hinder the model from adapting to other dissimilar target subdomains, which leads to limited performance. In this work, we introduce a multi-teacher framework with bidirectional photometric mixing to separately adapt to every target subdomain. First, we present an automatic domain separation to find the optimal number of subdomains. On this basis, we propose a multi-teacher framework in which each teacher model uses bidirectional photometric mixing to adapt to one target subdomain. Furthermore, we conduct an adaptive distillation to learn a student model and apply consistency regularization to improve the student generalization. Experimental results on benchmark datasets show the efficacy of the proposed approach for both the compound domain and the open domains against existing state-of-the-art approaches.