 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
MoDE: A Mixture-of-Experts Model with Mutual Distillation among the Experts
Jan 31, 2024The application of mixture-of-experts (MoE) is gaining popularity due to its ability to improve model's performance. In an MoE structure, the gate layer plays a significant role in distinguishing and routing input features to different experts. This enables each expert to specialize in processing their corresponding sub-tasks. However, the gate's routing mechanism also gives rise to narrow vision: the individual MoE's expert fails to use more samples in learning the allocated sub-task, which in turn limits the MoE to further improve its generalization ability. To effectively address this, we propose a method called Mixture-of-Distilled-Expert (MoDE), which applies moderate mutual distillation among experts to enable each expert to pick up more features learned by other experts and gain more accurate perceptions on their original allocated sub-tasks. We conduct plenty experiments including tabular, NLP and CV datasets, which shows MoDE's effectiveness, universality and robustness. Furthermore, we develop a parallel study through innovatively constructing "expert probing", to experimentally prove why MoDE works: moderate distilling knowledge can improve each individual expert's test performances on their assigned tasks, leading to MoE's overall performance improvement.
ALT: An Automatic System for Long Tail Scenario Modeling
May 19, 2023



In this paper, we consider the problem of long tail scenario modeling with budget limitation, i.e., insufficient human resources for model training stage and limited time and computing resources for model inference stage. This problem is widely encountered in various applications, yet has received deficient attention so far. We present an automatic system named ALT to deal with this problem. Several efforts are taken to improve the algorithms used in our system, such as employing various automatic machine learning related techniques, adopting the meta learning philosophy, and proposing an essential budget-limited neural architecture search method, etc. Moreover, to build the system, many optimizations are performed from a systematic perspective, and essential modules are armed, making the system more feasible and efficient. We perform abundant experiments to validate the effectiveness of our system and demonstrate the usefulness of the critical modules in our system. Moreover, online results are provided, which fully verified the efficacy of our system.
SAFE: Scalable Automatic Feature Engineering Framework for Industrial Tasks
Mar 09, 2020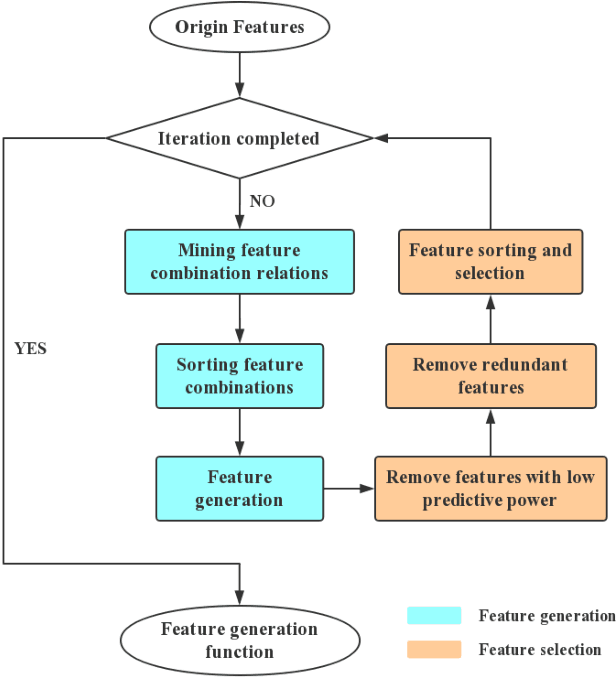
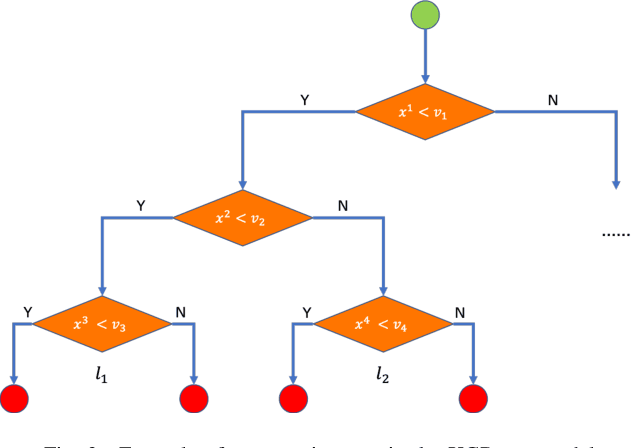
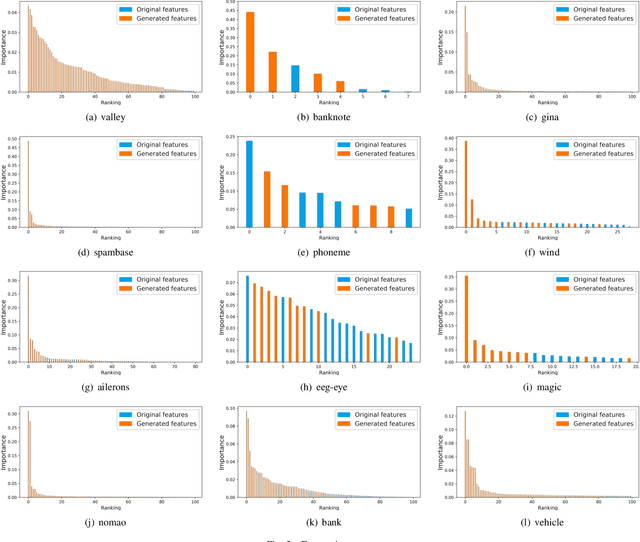
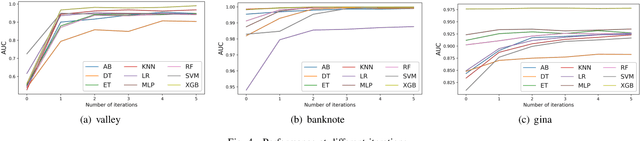
Machine learning techniques have been widely applied in Internet companies for various tasks, acting as an essential driving force, and feature engineering has been generally recognized as a crucial tache when constructing machine learning systems. Recently, a growing effort has been made to the development of automatic feature engineering methods, so that the substantial and tedious manual effort can be liberated. However, for industrial tasks, the efficiency and scalability of these methods are still far from satisfactory. In this paper, we proposed a staged method named SAFE (Scalable Automatic Feature Engineering), which can provide excellent efficiency and scalability, along with requisite interpretability and promising performance. Extensive experiments are conducted and the results show that the proposed method can provide prominent efficiency and competitive effectiveness when comparing with other methods. What's more, the adequate scalability of the proposed method ensures it to be deployed in large scale industrial tasks.