 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALT: An Automatic System for Long Tail Scenario Modeling
May 19, 2023



In this paper, we consider the problem of long tail scenario modeling with budget limitation, i.e., insufficient human resources for model training stage and limited time and computing resources for model inference stage. This problem is widely encountered in various applications, yet has received deficient attention so far. We present an automatic system named ALT to deal with this problem. Several efforts are taken to improve the algorithms used in our system, such as employing various automatic machine learning related techniques, adopting the meta learning philosophy, and proposing an essential budget-limited neural architecture search method, etc. Moreover, to build the system, many optimizations are performed from a systematic perspective, and essential modules are armed, making the system more feasible and efficient. We perform abundant experiments to validate the effectiveness of our system and demonstrate the usefulness of the critical modules in our system. Moreover, online results are provided, which fully verified the efficacy of our system.
Interpretable MTL from Heterogeneous Domains using Boosted Tree
Mar 16, 2020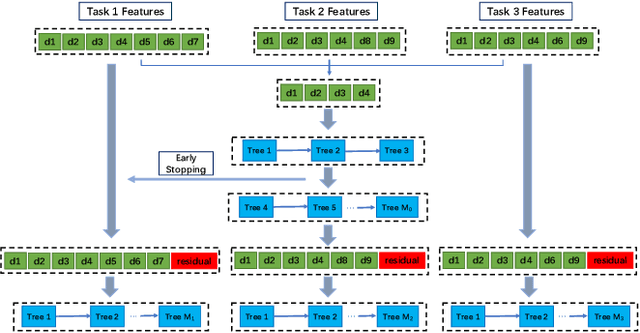

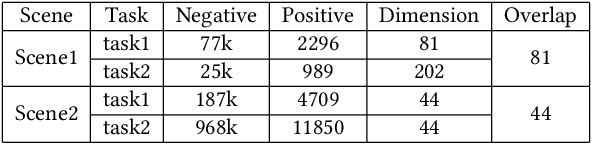

Multi-task learning (MTL) aims at improving the generalization performance of several related tasks by leveraging useful information contained in them. However, in industrial scenarios, interpretability is always demanded, and the data of different tasks may be in heterogeneous domains, making the existing methods unsuitable or unsatisfactory. In this paper, following the philosophy of boosted tree, we proposed a two-stage method. In stage one, a common model is built to learn the commonalities using the common features of all instances. Different from the training of conventional boosted tree model, we proposed a regularization strategy and an early-stopping mechanism to optimize the multi-task learning process. In stage two, started by fitting the residual error of the common model, a specific model is constructed with the task-specific instances to further boost the performance. Experiments on both benchmark and real-world datasets validate the effectiveness of the proposed method. What's more, interpretability can be naturally obtained from the tree based method, satisfying the industrial needs.
SAFE: Scalable Automatic Feature Engineering Framework for Industrial Tasks
Mar 09, 2020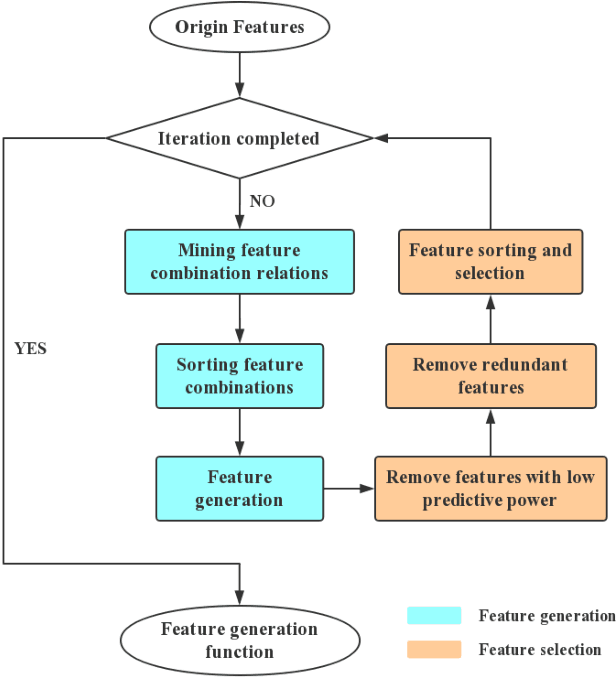
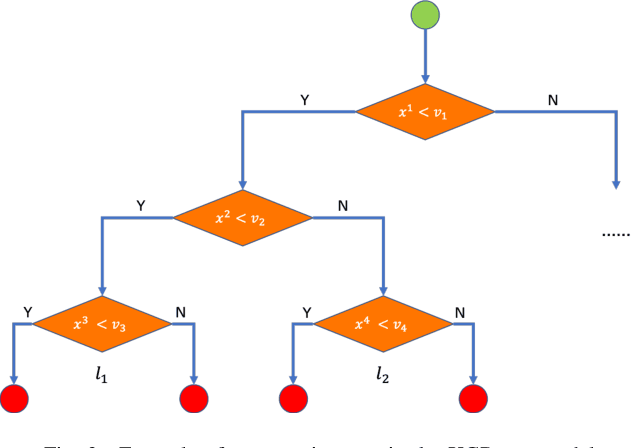
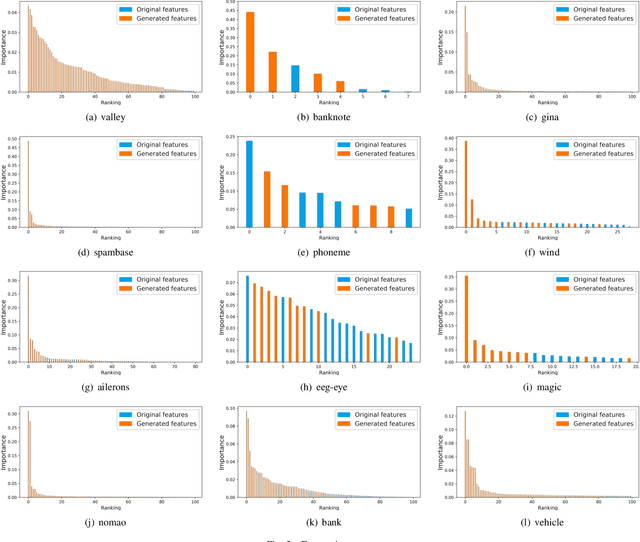
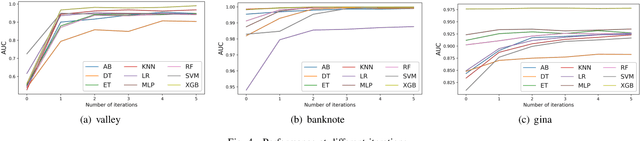
Machine learning techniques have been widely applied in Internet companies for various tasks, acting as an essential driving force, and feature engineering has been generally recognized as a crucial tache when constructing machine learning systems. Recently, a growing effort has been made to the development of automatic feature engineering methods, so that the substantial and tedious manual effort can be liberated. However, for industrial tasks, the efficiency and scalability of these methods are still far from satisfactory. In this paper, we proposed a staged method named SAFE (Scalable Automatic Feature Engineering), which can provide excellent efficiency and scalability, along with requisite interpretability and promising performance. Extensive experiments are conducted and the results show that the proposed method can provide prominent efficiency and competitive effectiveness when comparing with other methods. What's more, the adequate scalability of the proposed method ensures it to be deployed in large scale industrial tasks.
A Time Attention based Fraud Transaction Detection Framework
Dec 26, 2019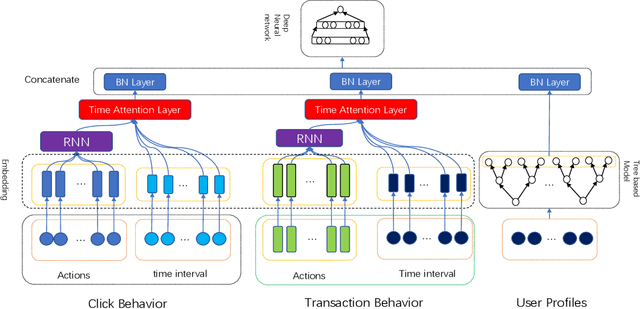
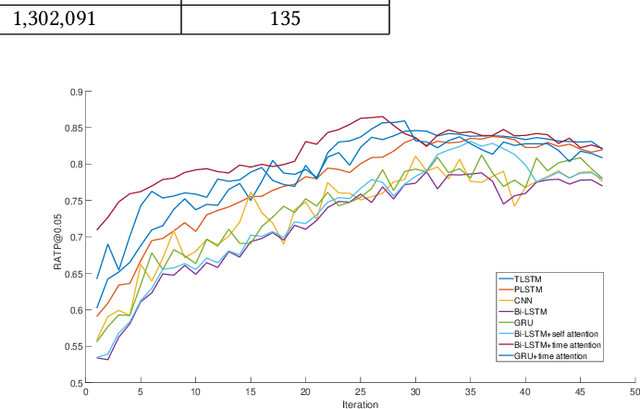
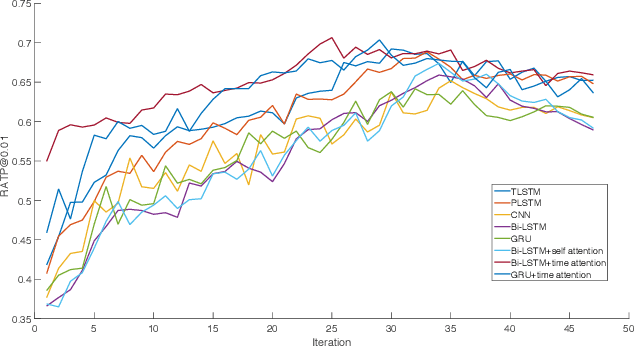
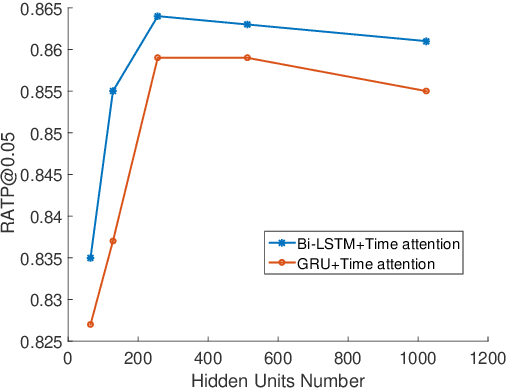
With online payment platforms being ubiquitous and important, fraud transaction detection has become the key for such platforms, to ensure user account safety and platform security. In this work, we present a novel method for detecting fraud transactions by leveraging patterns from both users' static profiles and users' dynamic behaviors in a unified framework. To address and explore the information of users' behaviors in continuous time spaces, we propose to use \emph{time attention based recurrent layers} to embed the detailed information of the time interval, such as the durations of specific actions, time differences between different actions and sequential behavior patterns,etc., in the same latent space. We further combine the learned embeddings and users' static profiles altogether in a unified framework. Extensive experiments validate the effectiveness of our proposed methods over state-of-the-art methods on various evaluation metrics, especially on \emph{recall at top percent} which is an important metric for measuring the balance between service experiences and risk of potential losses.
Distributed Deep Forest and its Application to Automatic Detection of Cash-out Fraud
May 27, 2018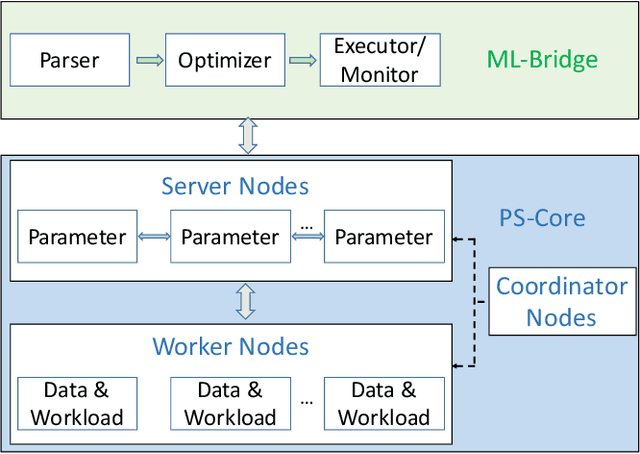
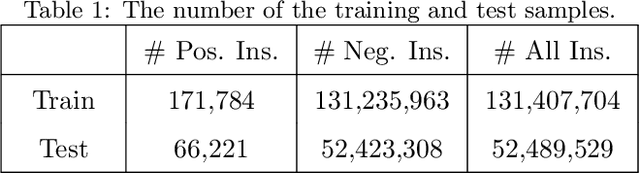
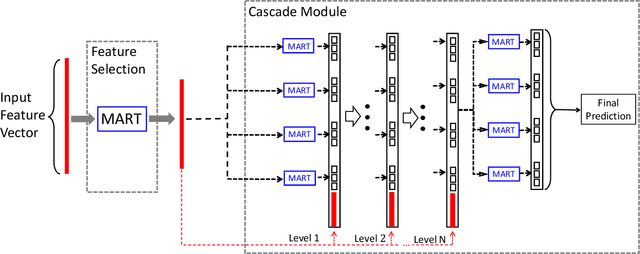
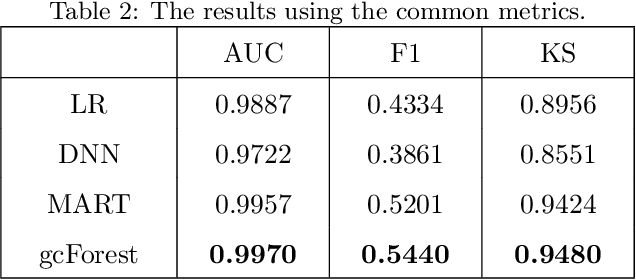
Internet companies are facing the need of handling large scale machine learning applications in a daily basis, and distributed system which can handle extra-large scale tasks is needed. Deep forest is a recently proposed deep learning framework which uses tree ensembles as its building blocks and it has achieved highly competitive results on various domains of tasks. However, it has not been tested on extremely large scale tasks. In this work, based on our parameter server system and platform of artificial intelligence, we developed the distributed version of deep forest with an easy-to-use GUI. To the best of our knowledge, this is the first implementation of distributed deep forest. To meet the need of real-world tasks, many improvements are introduced to the original deep forest model. We tested the deep forest model on an extra-large scale task, i.e., automatic detection of cash-out fraud, with more than 100 millions of training samples. Experimental results showed that the deep forest model has the best performance according to the evaluation metrics from different perspectives even with very little effort for parameter tuning. This model can block fraud transactions in a large amount of money \footnote{detail is business confidential} each day. Even compared with the best deployed model, deep forest model can additionally bring into a significant decrease of economic loss.