 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-DPO: Mitigating Hallucination in Large Vision Language Models via Vision-Guided Direct Preference Optimization
Nov 05, 2024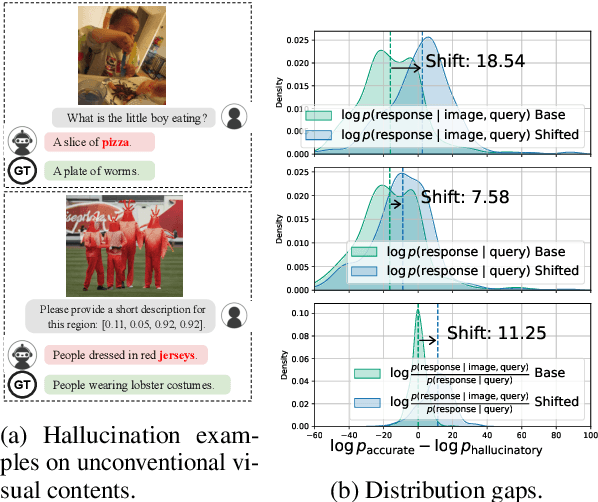
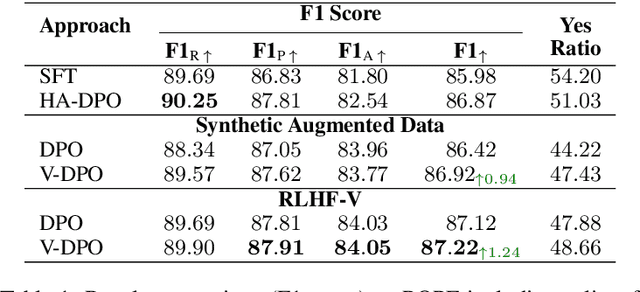
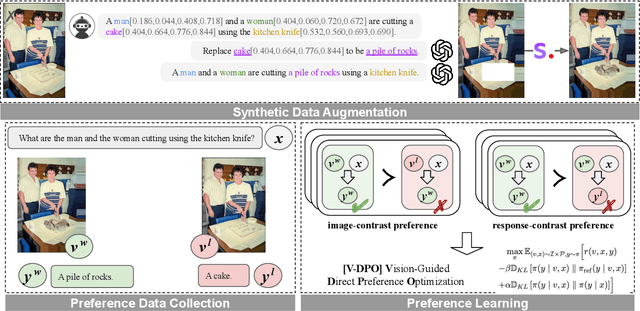
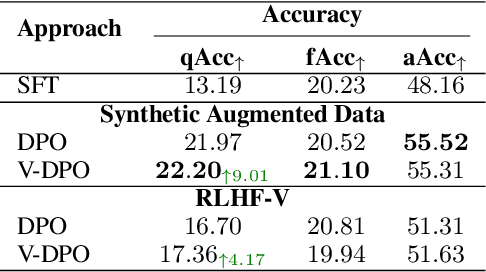
Large vision-language models (LVLMs) suffer from hallucination, resulting in misalignment between the output textual response and the input visual content. Recent research indicates that the over-reliance on the Large Language Model (LLM) backbone, as one cause of the LVLM hallucination, inherently introduces bias from language priors, leading to insufficient context attention to the visual inputs. We tackle this issue of hallucination by mitigating such over-reliance through preference learning. We propose Vision-guided Direct Preference Optimization (V-DPO) to enhance visual context learning at training time. To interpret the effectiveness and generalizability of V-DPO on different types of training data, we construct a synthetic dataset containing both response- and image-contrast preference pairs, compared against existing human-annotated hallucination samples. Our approach achieves significant improvements compared with baseline methods across various hallucination benchmarks. Our analysis indicates that V-DPO excels in learning from image-contrast preference data, demonstrating its superior ability to elicit and understand nuances of visual context. Our code is publicly available at https://github.com/YuxiXie/V-DPO.
MVP-Bench: Can Large Vision--Language Models Conduct Multi-level Visual Perception Like Humans?
Oct 06, 2024

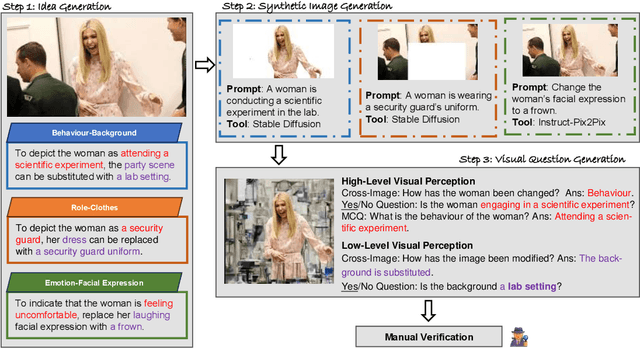
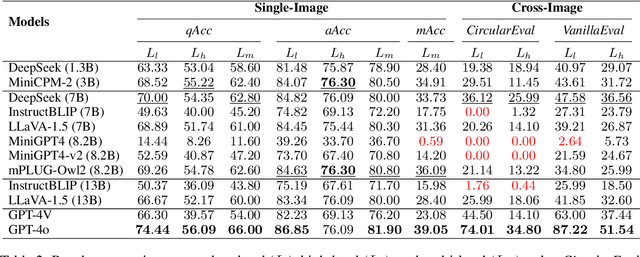
Humans perform visual perception at multiple levels, including low-level object recognition and high-level semantic interpretation such as behavior understanding. Subtle differences in low-level details can lead to substantial changes in high-level perception. For example, substituting the shopping bag held by a person with a gun suggests violent behavior, implying criminal or violent activity. Despite significant advancements in various multimodal tasks, Large Visual-Language Models (LVLMs) remain unexplored in their capabilities to conduct such multi-level visual perceptions. To investigate the perception gap between LVLMs and humans, we introduce MVP-Bench, the first visual-language benchmark systematically evaluating both low- and high-level visual perception of LVLMs. We construct MVP-Bench across natural and synthetic images to investigate how manipulated content influences model perception. Using MVP-Bench, we diagnose the visual perception of 10 open-source and 2 closed-source LVLMs, showing that high-level perception tasks significantly challenge existing LVLMs. The state-of-the-art GPT-4o only achieves an accuracy of $56\%$ on Yes/No questions, compared with $74\%$ in low-level scenarios. Furthermore, the performance gap between natural and manipulated images indicates that current LVLMs do not generalize in understanding the visual semantics of synthetic images as humans do. Our data and code are publicly available at https://github.com/GuanzhenLi/MVP-Bench.
ECHo: Event Causality Inference via Human-centric Reasoning
May 24, 2023



We introduce ECHo, a diagnostic dataset of event causality inference grounded in visual-and-linguistic social scenarios. ECHo employs real-world human-centric deductive information collected from crime drama, bridging the gap in multimodal reasoning towards higher social intelligence through the elicitation of intermediate Theory-of-Mind (ToM). We propose a unified framework aligned with the Chain-of-Thought (CoT) paradigm to assess the reasoning capability of current AI systems. This ToM-enhanced CoT pipeline can accommodate and integrate various large foundation models in zero-shot visual-and-linguistic understanding. With this framework, we scrutinize the advanced large language and multimodal models via three complementary human-centric ECHo tasks. Further analysis demonstrates ECHo as a challenging dataset to expose imperfections and inconsistencies in reasoning.