 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVP-Bench: Can Large Vision--Language Models Conduct Multi-level Visual Perception Like Humans?
Paper and Code


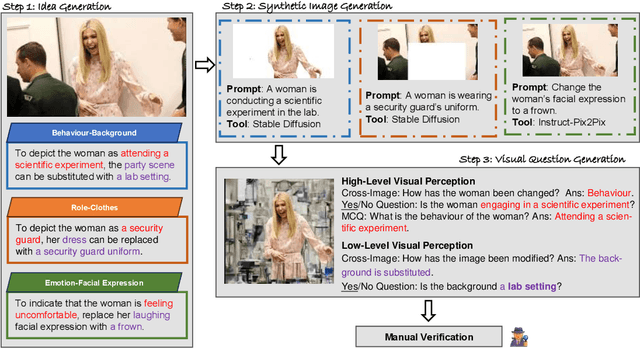
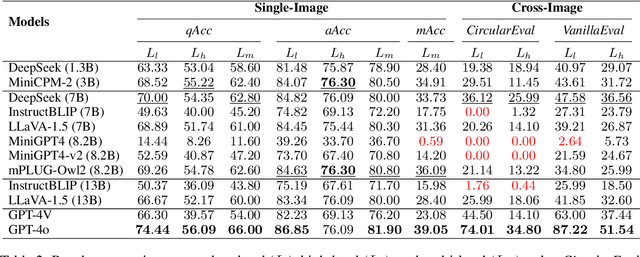
Humans perform visual perception at multiple levels, including low-level object recognition and high-level semantic interpretation such as behavior understanding. Subtle differences in low-level details can lead to substantial changes in high-level perception. For example, substituting the shopping bag held by a person with a gun suggests violent behavior, implying criminal or violent activity. Despite significant advancements in various multimodal tasks, Large Visual-Language Models (LVLMs) remain unexplored in their capabilities to conduct such multi-level visual perceptions. To investigate the perception gap between LVLMs and humans, we introduce MVP-Bench, the first visual-language benchmark systematically evaluating both low- and high-level visual perception of LVLMs. We construct MVP-Bench across natural and synthetic images to investigate how manipulated content influences model perception. Using MVP-Bench, we diagnose the visual perception of 10 open-source and 2 closed-source LVLMs, showing that high-level perception tasks significantly challenge existing LVLMs. The state-of-the-art GPT-4o only achieves an accuracy of $56\%$ on Yes/No questions, compared with $74\%$ in low-level scenarios. Furthermore, the performance gap between natural and manipulated images indicates that current LVLMs do not generalize in understanding the visual semantics of synthetic images as humans do. Our data and code are publicly available at https://github.com/GuanzhenLi/MVP-Bench.