 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE(3)-Equivariant Ternary Complex Prediction Towards Target Protein Degradation
Feb 26, 2025



Targeted protein degradation (TPD) induced by small molecules has emerged as a rapidly evolving modality in drug discovery, targeting proteins traditionally considered "undruggable". Proteolysis-targeting chimeras (PROTACs) and molecular glue degraders (MGDs) are the primary small molecules that induce TPD. Both types of molecules form a ternary complex linking an E3 ligase with a target protein, a crucial step for drug discovery. While significant advances have been made in binary structure prediction for proteins and small molecules, ternary structure prediction remains challenging due to obscure interaction mechanisms and insufficient training data. Traditional methods relying on manually assigned rules perform poorly and are computationally demanding due to extensive random sampling. In this work, we introduce DeepTernary, a novel deep learning-based approach that directly predicts ternary structures in an end-to-end manner using an encoder-decoder architecture. DeepTernary leverages an SE(3)-equivariant graph neural network (GNN) with both intra-graph and ternary inter-graph attention mechanisms to capture intricate ternary interactions from our collected high-quality training dataset, TernaryDB. The proposed query-based Pocket Points Decoder extracts the 3D structure of the final binding ternary complex from learned ternary embeddings, demonstrating state-of-the-art accuracy and speed in existing PROTAC benchmarks without prior knowledge from known PROTACs. It also achieves notable accuracy on the more challenging MGD benchmark under the blind docking protocol. Remarkably, our experiments reveal that the buried surface area calculated from predicted structures correlates with experimentally obtained degradation potency-related metrics. Consequently, DeepTernary shows potential in effectively assisting and accelerating the development of TPDs for previously undruggable targets.
Exploring Expression-related Self-supervised Learning for Affective Behaviour Analysis
Mar 18, 2023

This paper explores an expression-related self-supervised learning (SSL) method (ContraWarping) to perform expression classification in the 5th Affective Behavior Analysis in-the-wild (ABAW) competition. Affective datasets are expensive to annotate, and SSL methods could learn from large-scale unlabeled data, which is more suitable for this task. By evaluating on the Aff-Wild2 dataset, we demonstrate that ContraWarping outperforms most existing supervised methods and shows great application potential in the affective analysis area. Codes will be released on: https://github.com/youqingxiaozhua/ABAW5.
Unsupervised Facial Expression Representation Learning with Contrastive Local Warping
Mar 16, 2023


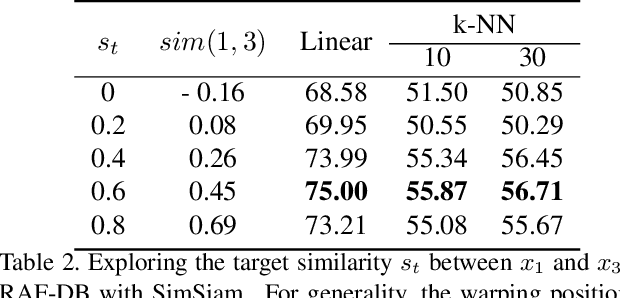
This paper investigates unsupervised representation learning for facial expression analysis. We think Unsupervised Facial Expression Representation (UFER) deserves exploration and has the potential to address some key challenges in facial expression analysis, such as scaling, annotation bias, the discrepancy between discrete labels and continuous emotions, and model pre-training. Such motivated, we propose a UFER method with contrastive local warping (ContraWarping), which leverages the insight that the emotional expression is robust to current global transformation (affine transformation, color jitter, etc.) but can be easily changed by random local warping. Therefore, given a facial image, ContraWarping employs some global transformations and local warping to generate its positive and negative samples and sets up a novel contrastive learning framework. Our in-depth investigation shows that: 1) the positive pairs from global transformations may be exploited with general self-supervised learning (e.g., BYOL) and already bring some informative features, and 2) the negative pairs from local warping explicitly introduce expression-related variation and further bring substantial improvement. Based on ContraWarping, we demonstrate the benefit of UFER under two facial expression analysis scenarios: facial expression recognition and image retrieval. For example, directly using ContraWarping features for linear probing achieves 79.14% accuracy on RAF-DB, significantly reducing the gap towards the full-supervised counterpart (88.92% / 84.81% with/without pre-training).
TransMatting: Tri-token Equipped Transformer Model for Image Matting
Mar 11, 2023



Image matting aims to predict alpha values of elaborate uncertainty areas of natural images, like hairs, smoke, and spider web. However, existing methods perform poorly when faced with highly transparent foreground objects due to the large area of uncertainty to predict and the small receptive field of convolutional networks. To address this issue, we propose a Transformer-based network (TransMatting) to model transparent objects with long-range features and collect a high-resolution matting dataset of transparent objects (Transparent-460) for performance evaluation. Specifically, to utilize semantic information in the trimap flexibly and effectively, we also redesign the trimap as three learnable tokens, named tri-token. Both Transformer and convolution matting models could benefit from our proposed tri-token design. By replacing the traditional trimap concatenation strategy with our tri-token, existing matting methods could achieve about 10% improvement in SAD and 20% in MSE. Equipped with the new tri-token design, our proposed TransMatting outperforms current state-of-the-art methods on several popular matting benchmarks and our newly collected Transparent-460.
Vision Transformer with Attentive Pooling for Robust Facial Expression Recognition
Dec 11, 2022



Facial Expression Recognition (FER) in the wild is an extremely challenging task. Recently, some Vision Transformers (ViT) have been explored for FER, but most of them perform inferiorly compared to Convolutional Neural Networks (CNN). This is mainly because the new proposed modules are difficult to converge well from scratch due to lacking inductive bias and easy to focus on the occlusion and noisy areas. TransFER, a representative transformer-based method for FER, alleviates this with multi-branch attention dropping but brings excessive computations. On the contrary, we present two attentive pooling (AP) modules to pool noisy features directly. The AP modules include Attentive Patch Pooling (APP) and Attentive Token Pooling (ATP). They aim to guide the model to emphasize the most discriminative features while reducing the impacts of less relevant features. The proposed APP is employed to select the most informative patches on CNN features, and ATP discards unimportant tokens in ViT. Being simple to implement and without learnable parameters, the APP and ATP intuitively reduce the computational cost while boosting the performance by ONLY pursuing the most discriminative features. Qualitative results demonstrate the motivations and effectiveness of our attentive poolings. Besides, quantitative results on six in-the-wild datasets outperform other state-of-the-art methods.
TransMatting: Enhancing Transparent Objects Matting with Transformers
Aug 05, 2022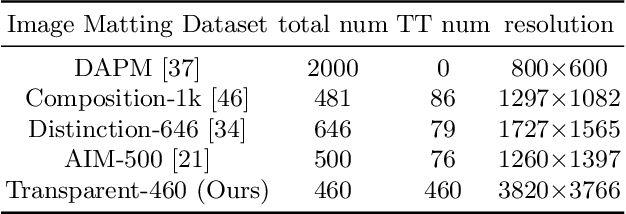
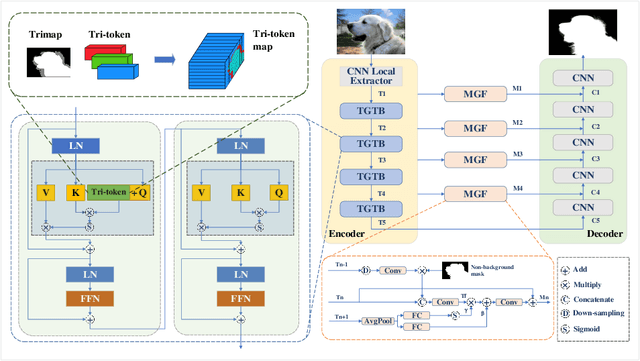
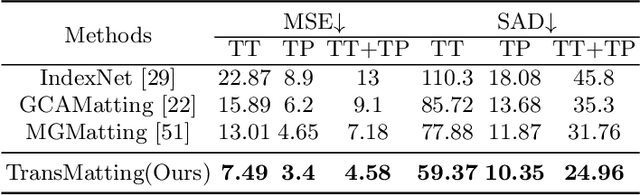

Image matting refers to predicting the alpha values of unknown foreground areas from natural images. Prior methods have focused on propagating alpha values from known to unknown regions. However, not all natural images have a specifically known foreground. Images of transparent objects, like glass, smoke, web, etc., have less or no known foreground. In this paper, we propose a Transformer-based network, TransMatting, to model transparent objects with a big receptive field. Specifically, we redesign the trimap as three learnable tri-tokens for introducing advanced semantic features into the self-attention mechanism. A small convolutional network is proposed to utilize the global feature and non-background mask to guide the multi-scale feature propagation from encoder to decoder for maintaining the contexture of transparent objects. In addition, we create a high-resolution matting dataset of transparent objects with small known foreground areas. Experiments on several matting benchmarks demonstrate the superiority of our proposed method over the current state-of-the-art methods.
Coarse-to-Fine Cascaded Networks with Smooth Predicting for Video Facial Expression Recognition
Mar 28, 2022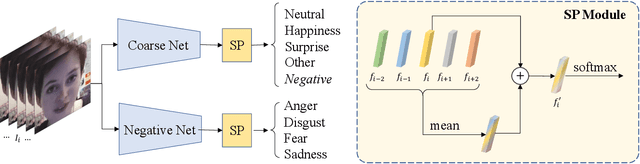

Facial expression recognition plays an important role in human-computer interaction. In this paper, we propose the Coarse-to-Fine Cascaded network with Smooth Predicting (CFC-SP) to improve the performance of facial expression recognition. CFC-SP contains two core components, namely Coarse-to-Fine Cascaded networks (CFC) and Smooth Predicting (SP). For CFC, it first groups several similar emotions to form a rough category, and then employs a network to conduct a coarse but accurate classification. Later, an additional network for these grouped emotions is further used to obtain fine-grained predictions. For SP, it improves the recognition capability of the model by capturing both universal and unique expression features. To be specific, the universal features denote the general characteristic of facial emotions within a period and the unique features denote the specific characteristic at this moment. Experiments on Aff-Wild2 show the effectiveness of the proposed CFSP.
TransFER: Learning Relation-aware Facial Expression Representations with Transformers
Aug 25, 2021
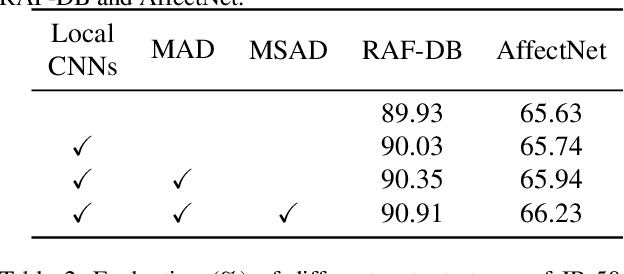
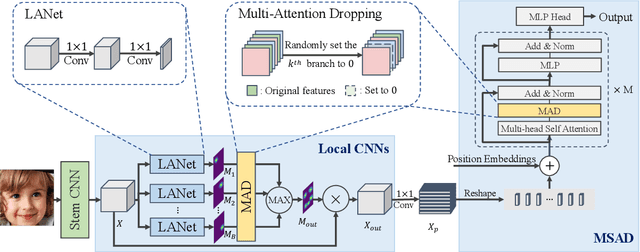

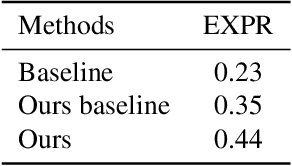
Facial expression recognition (FER) has received increasing interest in computer vision. We propose the TransFER model which can learn rich relation-aware local representations. It mainly consists of three components: Multi-Attention Dropping (MAD), ViT-FER, and Multi-head Self-Attention Dropping (MSAD). First, local patches play an important role in distinguishing various expressions, however, few existing works can locate discriminative and diverse local patches. This can cause serious problems when some patches are invisible due to pose variations or viewpoint changes. To address this issue, the MAD is proposed to randomly drop an attention map. Consequently, models are pushed to explore diverse local patches adaptively. Second, to build rich relations between different local patches, the Vision Transformers (ViT) are used in FER, called ViT-FER. Since the global scope is used to reinforce each local patch, a better representation is obtained to boost the FER performance. Thirdly, the multi-head self-attention allows ViT to jointly attend to features from different information subspaces at different positions. Given no explicit guidance, however, multiple self-attentions may extract similar relations. To address this, the MSAD is proposed to randomly drop one self-attention module. As a result, models are forced to learn rich relations among diverse local patches. Our proposed TransFER model outperforms the state-of-the-art methods on several FER benchmarks, showing its effectiveness and usefulness.