 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVLA-RL: Dual-Level Vision-Language Alignment with Reinforcement Learning Gating for Few-Shot Learning
Jan 31, 2026Few-shot learning (FSL) aims to generalize to novel categories with only a few samples. Recent approaches incorporate large language models (LLMs) to enrich visual representations with semantic embeddings derived from class names. However, they overlook progressive and adaptive alignment between vision and language from low-level to high-level semantics, resulting in limited semantic gains. To address these challenges, we propose Dual-level Vision-Language Alignment with Reinforcement Learning gating (DVLA-RL), which consists of Dual-level Semantic Construction (DSC) and RL-gated Attention (RLA). Specifically, DSC conditions LLMs on both class names and support samples to generate discriminative attributes, progressively selects the most relevant ones, and then synthesizes them into coherent class descriptions. This process provides complementary low-level attributes and high-level descriptions, enabling both fine-grained grounding and holistic class understanding. To dynamically integrate dual-level semantics along with the visual network layers, RLA formulates cross-modal fusion as a sequential decision process. A lightweight policy trained with episodic REINFORCE adaptively adjusts the contributions of self-attention and cross-attention to integrate textual and visual tokens. As a result, shallow layers refine local attributes and deep layers emphasize global semantics, enabling more precise cross-modal alignment. This achieves class-specific discrimination and generalized representations with merely a few support samples. DVLA-RL achieves new state-of-the-art performance across nine benchmarks in three diverse FSL scenarios.
KNN Transformer with Pyramid Prompts for Few-Shot Learning
Oct 14, 2024Few-Shot Learning (FSL) aims to recognize new classes with limited labeled data. Recent studies have attempted to address the challenge of rare samples with textual prompts to modulate visual features. However, they usually struggle to capture complex semantic relationships between textual and visual features. Moreover, vanilla self-attention is heavily affected by useless information in images, severely constraining the potential of semantic priors in FSL due to the confusion of numerous irrelevant tokens during interaction. To address these aforementioned issues, a K-NN Transformer with Pyramid Prompts (KTPP) is proposed to select discriminative information with K-NN Context Attention (KCA) and adaptively modulate visual features with Pyramid Cross-modal Prompts (PCP). First, for each token, the KCA only selects the K most relevant tokens to compute the self-attention matrix and incorporates the mean of all tokens as the context prompt to provide the global context in three cascaded stages. As a result, irrelevant tokens can be progressively suppressed. Secondly, pyramid prompts are introduced in the PCP to emphasize visual features via interactions between text-based class-aware prompts and multi-scale visual features. This allows the ViT to dynamically adjust the importance weights of visual features based on rich semantic information at different scales, making models robust to spatial variations. Finally, augmented visual features and class-aware prompts are interacted via the KCA to extract class-specific features. Consequently, our model further enhances noise-free visual representations via deep cross-modal interactions, extracting generalized visual representation in scenarios with few labeled samples. Extensive experiments on four benchmark datasets demonstrate the effectiveness of our method.
Recent Advances of Local Mechanisms in Computer Vision: A Survey and Outlook of Recent Work
Jun 02, 2023



Inspired by the fact that human brains can emphasize discriminative parts of the input and suppress irrelevant ones, substantial local mechanisms have been designed to boost the development of computer vision. They can not only focus on target parts to learn discriminative local representations, but also process information selectively to improve the efficiency. In terms of application scenarios and paradigms, local mechanisms have different characteristics. In this survey, we provide a systematic review of local mechanisms for various computer vision tasks and approaches, including fine-grained visual recognition, person re-identification, few-/zero-shot learning, multi-modal learning, self-supervised learning, Vision Transformers, and so on. Categorization of local mechanisms in each field is summarized. Then, advantages and disadvantages for every category are analyzed deeply, leaving room for exploration. Finally, future research directions about local mechanisms have also been discussed that may benefit future works. To the best our knowledge, this is the first survey about local mechanisms on computer vision. We hope that this survey can shed light on future research in the computer vision field.
Vision Transformer with Attentive Pooling for Robust Facial Expression Recognition
Dec 11, 2022



Facial Expression Recognition (FER) in the wild is an extremely challenging task. Recently, some Vision Transformers (ViT) have been explored for FER, but most of them perform inferiorly compared to Convolutional Neural Networks (CNN). This is mainly because the new proposed modules are difficult to converge well from scratch due to lacking inductive bias and easy to focus on the occlusion and noisy areas. TransFER, a representative transformer-based method for FER, alleviates this with multi-branch attention dropping but brings excessive computations. On the contrary, we present two attentive pooling (AP) modules to pool noisy features directly. The AP modules include Attentive Patch Pooling (APP) and Attentive Token Pooling (ATP). They aim to guide the model to emphasize the most discriminative features while reducing the impacts of less relevant features. The proposed APP is employed to select the most informative patches on CNN features, and ATP discards unimportant tokens in ViT. Being simple to implement and without learnable parameters, the APP and ATP intuitively reduce the computational cost while boosting the performance by ONLY pursuing the most discriminative features. Qualitative results demonstrate the motivations and effectiveness of our attentive poolings. Besides, quantitative results on six in-the-wild datasets outperform other state-of-the-art methods.
TransFER: Learning Relation-aware Facial Expression Representations with Transformers
Aug 25, 2021
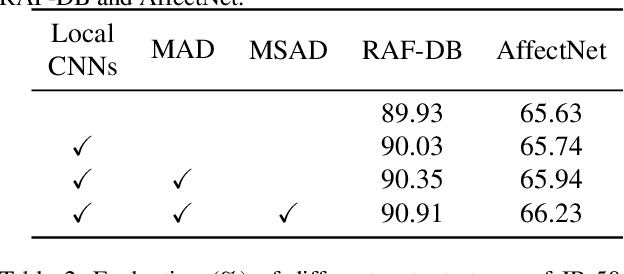
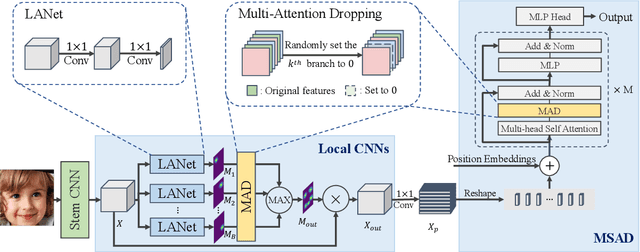

Facial expression recognition (FER) has received increasing interest in computer vision. We propose the TransFER model which can learn rich relation-aware local representations. It mainly consists of three components: Multi-Attention Dropping (MAD), ViT-FER, and Multi-head Self-Attention Dropping (MSAD). First, local patches play an important role in distinguishing various expressions, however, few existing works can locate discriminative and diverse local patches. This can cause serious problems when some patches are invisible due to pose variations or viewpoint changes. To address this issue, the MAD is proposed to randomly drop an attention map. Consequently, models are pushed to explore diverse local patches adaptively. Second, to build rich relations between different local patches, the Vision Transformers (ViT) are used in FER, called ViT-FER. Since the global scope is used to reinforce each local patch, a better representation is obtained to boost the FER performance. Thirdly, the multi-head self-attention allows ViT to jointly attend to features from different information subspaces at different positions. Given no explicit guidance, however, multiple self-attentions may extract similar relations. To address this, the MSAD is proposed to randomly drop one self-attention module. As a result, models are forced to learn rich relations among diverse local patches. Our proposed TransFER model outperforms the state-of-the-art methods on several FER benchmarks, showing its effectiveness and usefulness.
Learning Channel Inter-dependencies at Multiple Scales on Dense Networks for Face Recognition
Nov 28, 2017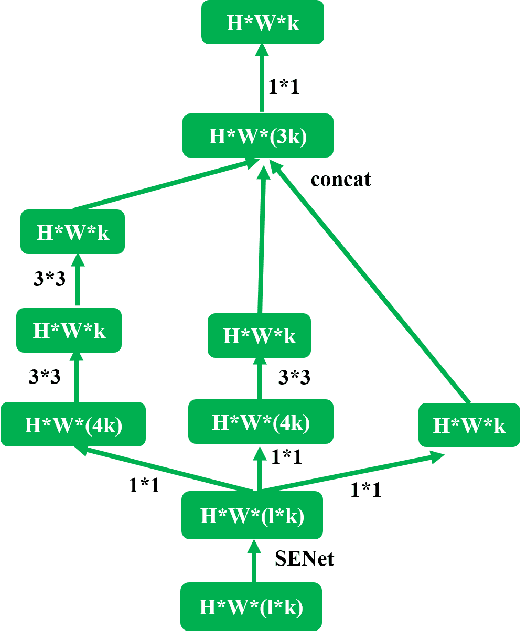
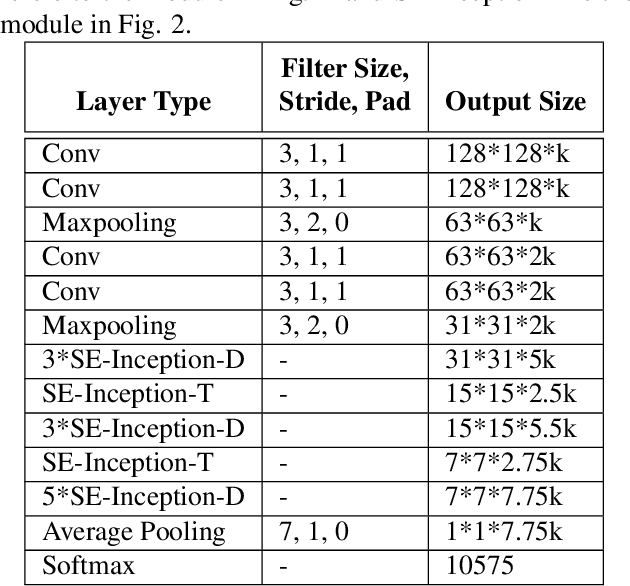
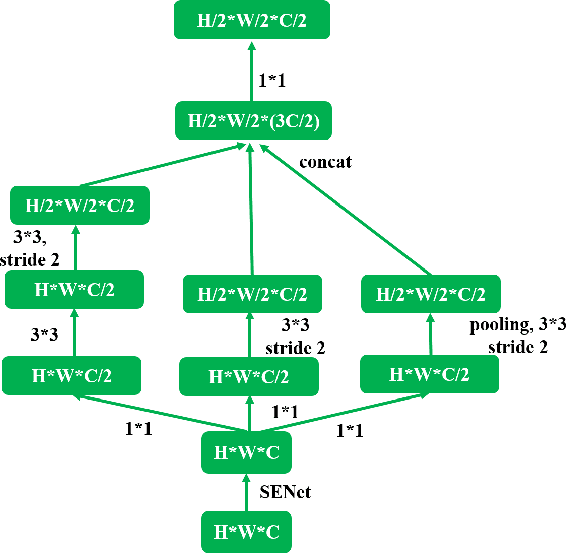
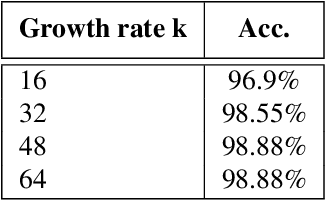
We propose a new deep network structure for unconstrained face recognition. The proposed network integrates several key components together in order to characterize complex data distributions, such as in unconstrained face images. Inspired by recent progress in deep networks, we consider some important concepts, including multi-scale feature learning, dense connections of network layers, and weighting different network flows, for building our deep network structure. The developed network is evaluated in unconstrained face matching, showing the capability of learning complex data distributions caused by face images with various qualities.