 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformer with Attentive Pooling for Robust Facial Expression Recognition
Dec 11, 2022



Facial Expression Recognition (FER) in the wild is an extremely challenging task. Recently, some Vision Transformers (ViT) have been explored for FER, but most of them perform inferiorly compared to Convolutional Neural Networks (CNN). This is mainly because the new proposed modules are difficult to converge well from scratch due to lacking inductive bias and easy to focus on the occlusion and noisy areas. TransFER, a representative transformer-based method for FER, alleviates this with multi-branch attention dropping but brings excessive computations. On the contrary, we present two attentive pooling (AP) modules to pool noisy features directly. The AP modules include Attentive Patch Pooling (APP) and Attentive Token Pooling (ATP). They aim to guide the model to emphasize the most discriminative features while reducing the impacts of less relevant features. The proposed APP is employed to select the most informative patches on CNN features, and ATP discards unimportant tokens in ViT. Being simple to implement and without learnable parameters, the APP and ATP intuitively reduce the computational cost while boosting the performance by ONLY pursuing the most discriminative features. Qualitative results demonstrate the motivations and effectiveness of our attentive poolings. Besides, quantitative results on six in-the-wild datasets outperform other state-of-the-art methods.
Coarse-to-Fine Cascaded Networks with Smooth Predicting for Video Facial Expression Recognition
Mar 28, 2022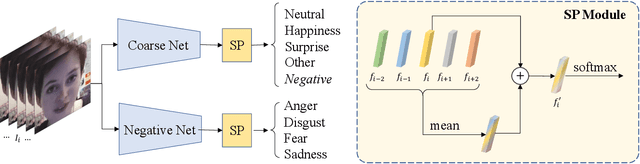
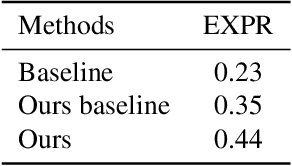

Facial expression recognition plays an important role in human-computer interaction. In this paper, we propose the Coarse-to-Fine Cascaded network with Smooth Predicting (CFC-SP) to improve the performance of facial expression recognition. CFC-SP contains two core components, namely Coarse-to-Fine Cascaded networks (CFC) and Smooth Predicting (SP). For CFC, it first groups several similar emotions to form a rough category, and then employs a network to conduct a coarse but accurate classification. Later, an additional network for these grouped emotions is further used to obtain fine-grained predictions. For SP, it improves the recognition capability of the model by capturing both universal and unique expression features. To be specific, the universal features denote the general characteristic of facial emotions within a period and the unique features denote the specific characteristic at this moment. Experiments on Aff-Wild2 show the effectiveness of the proposed CFSP.