 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniVision: A Unified Framework for Vision-Centric 3D Perception
Jan 13, 2024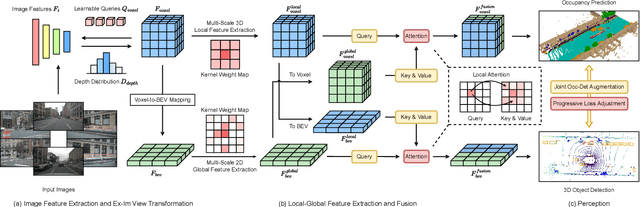
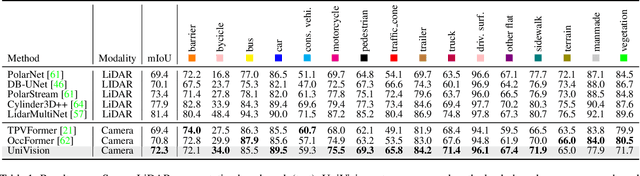
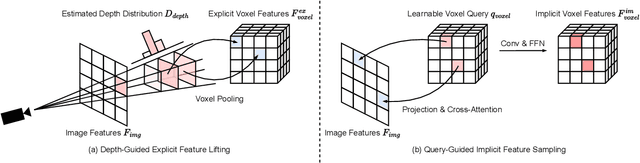
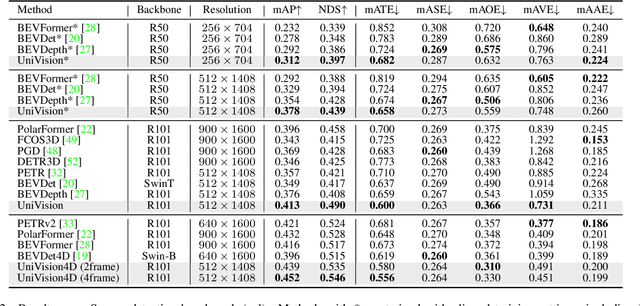
The past few years have witnessed the rapid development of vision-centric 3D perception in autonomous driving. Although the 3D perception models share many structural and conceptual similarities, there still exist gaps in their feature representations, data formats, and objectives, posing challenges for unified and efficient 3D perception framework design. In this paper, we present UniVision, a simple and efficient framework that unifies two major tasks in vision-centric 3D perception, \ie, occupancy prediction and object detection. Specifically, we propose an explicit-implicit view transform module for complementary 2D-3D feature transformation. We propose a local-global feature extraction and fusion module for efficient and adaptive voxel and BEV feature extraction, enhancement, and interaction. Further, we propose a joint occupancy-detection data augmentation strategy and a progressive loss weight adjustment strategy which enables the efficiency and stability of the multi-task framework training. We conduct extensive experiments for different perception tasks on four public benchmarks, including nuScenes LiDAR segmentation, nuScenes detection, OpenOccupancy, and Occ3D. UniVision achieves state-of-the-art results with +1.5 mIoU, +1.8 NDS, +1.5 mIoU, and +1.8 mIoU gains on each benchmark, respectively. We believe that the UniVision framework can serve as a high-performance baseline for the unified vision-centric 3D perception task. The code will be available at \url{https://github.com/Cc-Hy/UniVision}.
Large Trajectory Models are Scalable Motion Predictors and Planners
Oct 30, 2023Motion prediction and planning are vital tasks in autonomous driving, and recent efforts have shifted to machine learning-based approaches. The challenges include understanding diverse road topologies, reasoning traffic dynamics over a long time horizon, interpreting heterogeneous behaviors, and generating policies in a large continuous state space. Inspired by the success of large language models in addressing similar complexities through model scaling, we introduce a scalable trajectory model called State Transformer (STR). STR reformulates the motion prediction and motion planning problems by arranging observations, states, and actions into one unified sequence modeling task. With a simple model design, STR consistently outperforms baseline approaches in both problems. Remarkably, experimental results reveal that large trajectory models (LTMs), such as STR, adhere to the scaling laws by presenting outstanding adaptability and learning efficiency. Qualitative results further demonstrate that LTMs are capable of making plausible predictions in scenarios that diverge significantly from the training data distribution. LTMs also learn to make complex reasonings for long-term planning, without explicit loss designs or costly high-level annotations.