 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniVision: A Unified Framework for Vision-Centric 3D Perception
Paper and Code
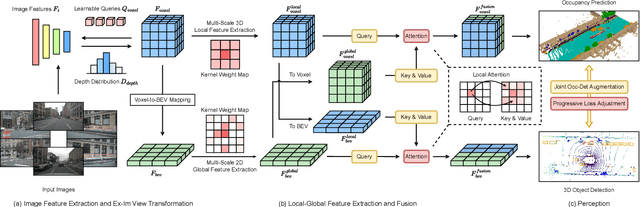
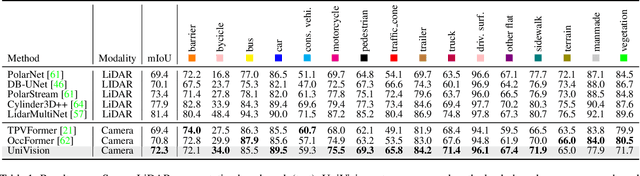
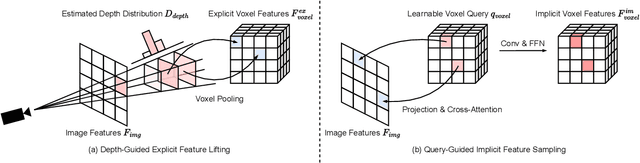
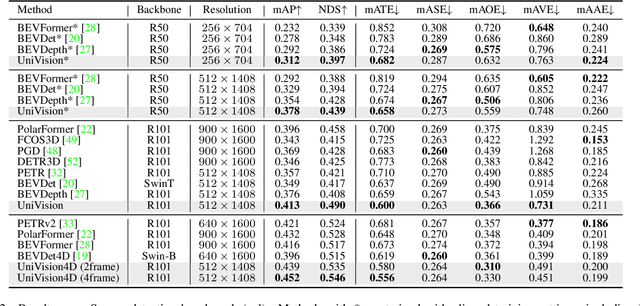
The past few years have witnessed the rapid development of vision-centric 3D perception in autonomous driving. Although the 3D perception models share many structural and conceptual similarities, there still exist gaps in their feature representations, data formats, and objectives, posing challenges for unified and efficient 3D perception framework design. In this paper, we present UniVision, a simple and efficient framework that unifies two major tasks in vision-centric 3D perception, \ie, occupancy prediction and object detection. Specifically, we propose an explicit-implicit view transform module for complementary 2D-3D feature transformation. We propose a local-global feature extraction and fusion module for efficient and adaptive voxel and BEV feature extraction, enhancement, and interaction. Further, we propose a joint occupancy-detection data augmentation strategy and a progressive loss weight adjustment strategy which enables the efficiency and stability of the multi-task framework training. We conduct extensive experiments for different perception tasks on four public benchmarks, including nuScenes LiDAR segmentation, nuScenes detection, OpenOccupancy, and Occ3D. UniVision achieves state-of-the-art results with +1.5 mIoU, +1.8 NDS, +1.5 mIoU, and +1.8 mIoU gains on each benchmark, respectively. We believe that the UniVision framework can serve as a high-performance baseline for the unified vision-centric 3D perception task. The code will be available at \url{https://github.com/Cc-Hy/UniVision}.